
【演算法】CRF(條件隨機場)
CRF(條件隨機場)
基本概念
- 場是什麼
場就是一個聯合概率分佈。比如有3個變數,y1,y2,y3, 取值範圍是{0,1}。聯合概率分佈就是{P(y2=0|y1=0,y3=0), P(y3=0|y1=0,y2=0), P(y2=0|y1=1,y3=0), P(y3=0|y1=1,y2=0), ...}
下圖就是一個場的簡單示意圖。
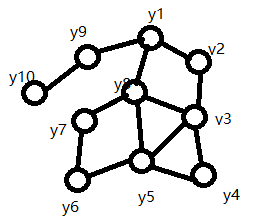
也就是變數間取值的概率分佈。
馬爾科夫隨機場
如果場中的變數只受相鄰變數的影響,而與其他變數無關。則這樣的場叫做馬爾科夫隨機場。
如下圖,綠色點變數的取值只受周圍相鄰的紅色點變數影響,與其他變數無關。
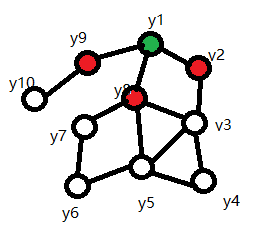
條件隨機場
有隨機變數X(x1,x2,...), Y(y1,y2,...), 在給定X的條件下Y的概率分佈是P(Y|X)。如果該分佈滿足馬爾科夫性,即只和相鄰變數有關,則稱為條件隨機場。
如下圖,與馬爾科夫隨機場的區別是多了條件X。
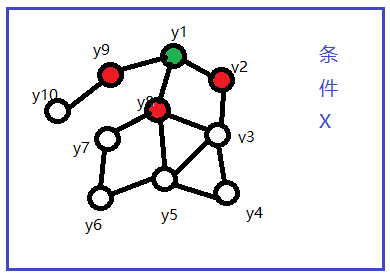
線性鏈條件隨機場
隨機變數Y成線性,即每個變數只和前後變數相關。
當條件X與變數Y的形式相同時,就是如下圖所示的線性鏈條件隨機場。該形式也是最常使用的,廣泛用於詞性標註,命名實體識別等問題。
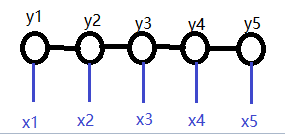
對於詞性標註來說,x就是輸入語句的每一個字,y就是輸出的每個字的詞性。
線性鏈條件隨機場的表示
設\(P(Y|X)\)是線性鏈條件隨機場,則在給定\(X\)的取值\(x\)的情況下,隨機變數\(Y\)取值為\(y\)的條件概率可以表達為:
\[P(y|x)=\frac{1}{Z(x)}exp\left(\sum_{i,k}{\lambda_kt_k(y_{i-1}, y_i,x,i)}+\sum_{i,l}\mu_ls_l(y_i,x,i)\right)\]
\[Z(x)=\sum_yexp\left(\sum_{i,k}{\lambda_kt_k(y_{i-1}, y_i,x,i)}+\sum_{i,l}\mu_ls_l(y_i,x,i)\right)\]
\(i\): 表示當前位置下標
\(t_k()\):表示相鄰兩個輸出間的關係,是轉移特徵函式。取值{0,1},即滿足特徵和不滿足特徵
\(s_l()\): 表示當前位置的特徵,是狀態特徵函式。取值{0,1}。
\(k\): 表示轉移特徵\(t\)的個數
\(l\): 表示狀態特徵\(s\)的個數
非規範化概率:\(P(Y|X)\)的分子部分
從定義角度來分析這個公式: 由於是條件隨機場,即受條件影響,所以每一個\(t_k\)
從實際含義角度分析這個公式: 對於\(s_l\),比如輸入漢字\(x\)為"門",對應位置\(y_i\)標註是名詞n,則滿足條件,取1。每一個\(s_l\)就是輸入對輸出詞性的影響。對於\(t_k\),比如\(y_{i-1}\)是動詞v,\(y_i\)是名詞n則認為滿足標記,取值1。也就是\(t_k\)表明了相鄰輸出間的約束關係。
條件隨機場的化簡形式和矩陣形式
為什麼需要知道條件隨機場的化簡形式和矩陣形式?無他,僅僅是因為後面求解問題時用到了相關的數學表達而已。看公式的感覺很痛苦,一堆符號也不知道是什麼,很煩。大家可能都有這樣的感受。但是想真正理解條件隨機場,這一步跳不過去啊。
條件隨機場的化簡形式
設有\(K_1\)個轉移特徵,\(K_2\)個狀態特徵,記
\[ f_k(y_{i-1},y_i,x,i)=\left\{ \begin{array}{lcl} t_k(y_{i-1},y_i,x,i), & k=1,2,...K_1\\ s_l(y_i,x,i), & k=K_1+l; l=1,2,...K_2 \\ \end{array} \right. \]
對所有位置\(i\)求和,記作
\[f_k(y,x)=\sum_{i=1}^{n}f_k(y_{i-1},y_i,x,i),\quad k=1,2,...,K\]
用\(\omega_k\)表示特徵\(f_k(y,x)\)的權值,即
\[ \omega_k=\left\{ \begin{array}{lcl} \lambda_k, & {k=1,2,...,K_1} \\ \mu_l, & {k=K_1+l; l=1,2,...,K_2} \end{array} \right. \]
那麼,條件隨機場就可以用如下公式表示:
\[P(y|x)=\frac{1}{Z(x)}exp\sum_{k=1}^{K}\omega_kf_k(y,x)\]
\[Z(x)=\sum_{y}exp\sum_{k=1}^{K}\omega_kf_k(y,x)\]
用\(\omega\)表示權值向量,即
\[\omega=(\omega_1,\omega_2,...\omega_k)^{T}\]
用\(F(y,x)\)表示全域性特徵向量,即
\[F(y,x)=(f_1(y,x),f_2(y,x),...,f_K(y,x))^{T}\]
則
\[P_\omega(y|x)=\frac{exp(\omega\cdot F(y,x))}{Z_\omega(x)}\]
\[Z_\omega(x)=\sum_{y}exp(\omega\cdot F(y,x))\]
條件隨機場的矩陣形式
設\(y\)一共有\(m\)種取值,則定義一個\(m\times m\)的矩陣
\[M_i(x)=[M_i(y_{i-1},y_i|x)]\]
\[M_i(y_{i-1},y_i|x)=exp\left(W_i(y_{i-1},y_i|x)\right)\]
\[W_i(y_{i-1},y_i|x)=\sum_{k=1}^{K}\omega_kf_k(y_{i-1},y_i,x,i)\]
\(M_i(y_{i-1},y_i|x)\)中的\(y\)取值是固定的,\(M_i(x)\)則是合併了所有可能的\(y\)取值,在矩陣表示下條件概率可以表達為\(P_\omega(y|x)\)
\[P_\omega(y|x)=\frac{1}{Z_\omega(x)}\prod_{i=1}^{n+1}M_i(y_{i-1},y{i}|x)\]
\[Z_\omega(x)=(M_1(x)M_2(x)...M_{n+1}(x))_{start,stop}\]
CRF涉及的三個問題
- 條件隨機場的概率計算問題
- 條件隨機場的學習演算法
- 條件隨機場的預測演算法
條件隨機場的概率計算問題
該問題是指,在已知條件隨機場分佈情況下,得出每個位置輸出結果的可能性。
比如有一個長度為3的輸入序列{1,2,3},每一個輸出的取值範圍是{0,1}。概率計算問題就是求出P(y1=0|X={1,2,3}),P(y1=1|X={1,2,3}),...。也就是求每個位置y取各個值得概率。
最開始我看這個問題的時候一直有一個困惑,什麼叫做給定條件隨機場。後來明白,給定條件隨機場是指給定所有的約束條件,即給定所有的\(t_k\)和\(s_l\)函式以及相關權重。
這個概率計算問題在實際演算法求解中並不常使用。但作為三個基本問題還是介紹一下處理的思路。
基本的處理思路是動態規劃,藉助了前向和後向向量。
前向向量:\(\alpha_i(y|x)\)表示,即不管從位置0到位置\(i-1\)部分\(y\)的取值,位置\(i\)取值為\(y\)的非規範化概率。
後向向量:\(\beta_i(y|x)\)表示,即不管從位置\(i+1\)到位置\(n\)部分\(y\)的取值,位置\(i\)取值為\(y\)的非規範化概率。
這樣通過前向和後向向量就可以得出相關的概率計算問題解:
\[P(Y_i=y_i|x)=\frac{\alpha_{i}^{T}(y_i|x)\beta_{i}^{T}(y_i|x)}{Z(x)}\]
\[P(Y_{i-1}=y_{i-1},Y_i=y_i|x)=\frac{\alpha_{i-1}^{T}(y_{i-1}|x)M_i(y_{i-1},y_i|x)\beta_{i}^{T}(y_i|x)}{Z(x)}\]
上面公式的詳細推導可以參看李航的《統計學習方法》,這裡只給出結果。很容易理解,因為前向向量隱藏了當前位置之前的取值細節,而後向向量隱藏了當前位置之後的取值細節,所以只需要關注當前位置取值就可以了。
條件隨機場的學習演算法
假設已經有一批輸入和輸出資料,已知所有可能的\(t_k\)和\(s_l\)函式,目標是求解合適的權重\(\omega_k\),使得訓練樣本出現的可能性最大。記住,目標是求權重\(\omega\)。為了實現這個目標,需要先定義目標函式,可以採用極大似然估計,用對數極大似然函式作為目標函式。
設輸入樣本為\((x=(1,2),y=(1,2)),(x=(1,3),y=(1,1)),(x=(2,3),y=(2,1))\)
設經驗概率分佈為\(\tilde{P}(X,Y)\),含義就是在輸入樣本中\(X,Y\)出現的頻率,對於上面例子,\(\tilde{P}(X=(1,2),Y=(1,2))=\frac{1}{3}\)
那麼對應的極大似然函式為:
\[\prod_{x,y}P_\omega(y|x)^{\tilde{P}(x,y)}\]
相應的對數似然函式為:
\[L(\omega)=log\prod_{x,y}P_\omega(y|x)^{\tilde{P}(x,y)}\]
使得\(L(\omega)\)取值最大的\(\omega\)就是我們要求的結果。
目標有了,後面就是數學的優化方法,梯度下降,牛頓法,改進的迭代尺度法,擬牛頓法都可以用。李航的書上重點介紹了改進的迭代尺度法和擬牛頓法。大家對細節感興趣的可以仔細看看P88-P92以及P202-P205頁。公式挺難的,我僅僅可以做到對著書上的公式知道它在做什麼。
簡單記錄一下這兩種方法的思路:
改進的迭代尺度法:思路是確立下界,並不斷提升下界實現求解(PS:這個思路看著跟EM演算法有點像)。首先根據\(-log\alpha\geq1-\alpha\)確立一個緊的下界。但該下界每次更新時需要調整所有的\(\omega_k\),不好求解。所以再根據凸函式的琴聲不等式,確立一個相對不緊的下界,調整該下界每次只需更新一個\(\omega_k\)。這樣通過不斷迭代可以求得最優解。
擬牛頓法:利用二階導數,用變數模擬海森矩陣,簡化求解。
條件隨機場的預測演算法
條件隨機場的預測演算法是指給定條件隨機場和輸入序列,求最可能出現的輸出序列。採用維特比演算法,這也是一種動態規劃演算法。
目標是找到使下式最大化的\(y\),注意下式就是去掉了標準\(P(y|x)\)的分子\(Z(x)\)和分母上的\(exp\)函式部分,其最終結果是不受影響的。
\[\max_y\sum_{i=1}^{n}\omega\cdot F_i(y_{i-1},y_{i},x)\]
其中,
\[F_i(y_{i-1},y_i,x)=(f_1(y_{i-1},y_i,x,i),f_2(y_{i-1},y_i,x,i),...,f_K(y_{i-1},y_i,x,i))^T\]
維特比演算法需要引入兩個變數\(\delta_i(j)\)和\(\psi_i(l)\)
\(\delta_i(j)\),僅考慮從起始位置到到當前位置\(i\)這段序列,在位置\(i\)上,上面目標函式在\(y=j\)時取得的最大值
\(\psi_i(l)=j\),\(i\)表示當前位置,\(l\)表示當前位置\(y_i\)的取值,\(j\)是前一個位置\(y_{i-1}\)的取值。也就是記錄最大值獲取的路徑。
遞推公式:
\[\delta_i(l)=\max_{1\leq j\leq m}\{\delta_{i-1}(j)+\omega\cdot F_i(y_{i-1}=j,y_i=l,x)\},\quad l=1,2,...,m\]
\[\psi_i(l)=arg\max_{1\leq j\leq m}\{\delta_{i-1}(j)+\omega\cdot F_i(y_{i-1}=j,y_i=l,x)\},\quad l=1,2,...,m\]
上述公式之所以成立,也是因為滿足馬爾科夫性,所以每個位置的結果只受上一個位置結果的影響。
參考資料
- 李航《統計學習方法》