
使用Keras進行多GPU訓練 multi_gpu_model

使用Keras訓練具有多個GPU的深度神經網路(照片來源:Nor-Tech.com)。
摘要
在今天的部落格文章中,我們學習瞭如何使用多個GPU來訓練基於Keras的深度神經網路。
使用多個GPU使我們能夠獲得準線性加速。
為了驗證這一點,我們在CIFAR-10資料集上訓練了MiniGoogLeNet。
使用單個GPU,我們能夠獲得63秒的時間段,總訓練時間為74分10秒。
然而,通過使用Keras和Python的多GPU訓練,我們將訓練時間減少到16秒,總訓練時間為19m3s。
使用Keras啟用多GPU培訓就像單個函式呼叫一樣簡單 - 我建議您儘可能使用多GPU培訓。在未來,我想象 multi_gpu_model 將演變,讓我們進一步定製專門
方法:使用Keras,Python和深度學習進行多GPU培訓
當我第一次開始使用Keras時,我愛上了API。它簡單而優雅,類似於scikit-learn。然而它非常強大,能夠實施和訓練最先進的深度神經網路。
然而,我對Keras的最大挫折之一是在多GPU環境中使用它可能有點不重要。
如果您使用Theano,請忘掉它 - 多GPU培訓不會發生。
TensorFlow是一種可能性,但它可能需要大量的樣板程式碼和調整才能使您的網路使用多個GPU進行訓練。
我更喜歡在執行多GPU培訓時使用mxnet後端(甚至是mxnet庫直接)到Keras,但這引入了更多的配置來處理。
所有這一切都與改變弗朗索瓦CHOLLET宣佈,使用TensorFlow後端多GPU的支援,現在在烤到Keras V2.0.9。大部分功勞歸功於@ kuza55和他們的keras-extras回購。
我已經使用並測試了這個多GPU功能已近一年了,我非常高興看到它作為官方Keras發行版的一部分。
在今天部落格文章的剩餘部分中,我將演示如何使用Keras,Python和深度學習訓練卷積神經網路進行影象分類。
MiniGoogLeNet深度學習架構
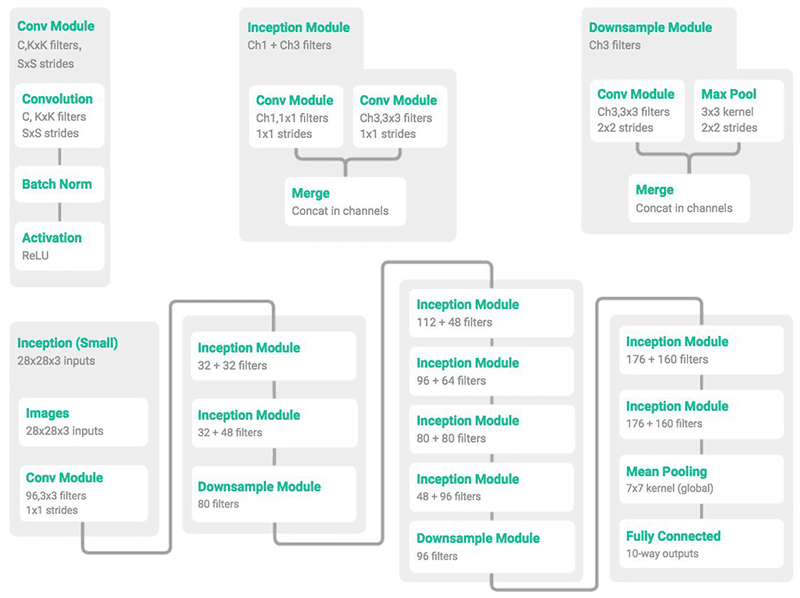
圖1: MiniGoogLeNet架構是它的大兄弟GoogLeNet / Inception的一個小版本。圖片來自
在上面的圖1中,我們可以看到單個卷積(左),初始(中)和下采樣(右)模組,然後是從這些構建塊構建的整體MiniGoogLeNet架構(底部)。我們將在本文後面的多GPU實驗中使用MiniGoogLeNet架構。
MiniGoogLenet中的Inception模組是Szegedy等人設計的原始Inception模組的變體。
我首先從@ ericjang11和@pluskid的推文中瞭解了這個“Miniception”模組,它們可以很好地視覺化模組和相關的MiniGoogLeNet架構。
在做了一些研究後,我發現這張圖片來自張等人的2017年出版物“ 理解深度學習需要重新思考泛化”。
然後我開始在Keras + Python中實現MiniGoogLeNet架構 - 我甚至將它作為使用Python進行計算機視覺深度學習的一部分。
對MiniGoogLeNet Keras實現的全面審查超出了本博文的範圍,因此如果您對網路的工作原理(以及如何編碼)感興趣,請參閱我的書。
否則,您可以使用此部落格文章底部的“下載”部分下載原始碼。
使用Keras和多個GPU訓練深度神經網路
讓我們繼續使用Keras和多個GPU開始培訓深度學習網路。
首先,您需要確保 在虛擬環境中安裝和更新Keras 2.0.9(或更高版本)(我們 在本書中使用名為dl4cv的虛擬環境 ):
| 1 2 | $ workon dl4cv $ pip install -- upgrade keras |
從那裡,開啟一個新檔案,將其命名為 train .py ,並插入以下程式碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # set the matplotlib backend so figures can be saved in the background # (uncomment the lines below if you are using a headless server) # import matplotlib # matplotlib.use("Agg") # import the necessary packages from pyimagesearch . minigooglenet import MiniGoogLeNet from sklearn . preprocessing import LabelBinarizer from keras . preprocessing . image import ImageDataGenerator from keras . callbacks import LearningRateScheduler from keras . utils . training_utils import multi_gpu_model from keras . optimizers import SGD from keras . datasets import cifar10 import matplotlib . pyplot as plt import tensorflow as tf import numpy as np import argparse |
如果您使用的是無頭伺服器,則需要通過取消註釋行來配置第3行和第4行的matplotlib後端。這樣可以將matplotlib圖儲存到磁碟。如果您沒有使用無頭伺服器(即,您的鍵盤+滑鼠+顯示器已插入系統,則可以將線條註釋掉)。
從那裡我們匯入這個指令碼所需的包。
第7行從我的pyimagesearch 模組匯入MiniGoogLeNet (包含在“下載”部分中提供的下載)。
另一個值得注意的匯入是在 第13行,我們匯入CIFAR10資料集。這個輔助函式將使我們能夠只用一行程式碼從磁碟載入CIFAR-10資料集。
現在讓我們解析命令列引數:
| 19 20 21 22 23 24 25 26 27 28 | # construct the argument parse and parse the arguments ap = argparse . ArgumentParser ( ) ap . add_argument ( "-o" , "--output" , required = True , help = "path to output plot" ) ap . add_argument ( "-g" , "--gpus" , type = int , default = 1 , help = "# of GPUs to use for training" ) args = vars ( ap . parse_args ( ) ) # grab the number of GPUs and store it in a conveience variable G = args [ "gpus" ] |
我們使用 argparse 解析一個需要和一個可選的引數線20-25:
- - 輸出 :訓練完成後輸出圖的路徑。
- - gpus :用於培訓的GPU數量。
載入命令列引數後, 為方便起見,我們將GPU的數量儲存為 G(第28行)。
從那裡,我們初始化用於配置我們的訓練過程的兩個重要變數,然後定義 poly_decay ,一個等同於Caffe的多項式學習速率衰減的學習速率排程函式:
| 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | # definine the total number of epochs to train for along with the # initial learning rate NUM_EPOCHS = 70 INIT_LR = 5e - 3 def poly_decay ( epoch ) : # initialize the maximum number of epochs, base learning rate, # and power of the polynomial maxEpochs = NUM_EPOCHS baseLR = INIT_LR power = 1.0 # compute the new learning rate based on polynomial decay alpha = baseLR * ( 1 - ( epoch / float ( maxEpochs ) ) ) * * power # return the new learning rate return alpha |
我們設定 NUM _ EPOCHS = 70 - 這是我們的訓練資料將通過網路的次數(時期)(第32行)。
我們還初始化學習率 INIT_LR = 5e - 3 ,這是在之前的試驗(第33行)中通過實驗發現的值。
從那裡,我們定義 poly_decay 函式,它相當於Caffe的多項式學習速率衰減(第35-46行)。本質上,此功能可在訓練期間更新學習速率,並在每個時期後有效地減少學習速度。設定 功率= 1.0 會將衰減從多項式更改為線性。
接下來我們將載入我們的訓練+測試資料並將影象資料從整數轉換為浮點數:
| 48 49 50 51 52 53 | # load the training and testing data, converting the images from # integers to floats print ( "[INFO] loading CIFAR-10 data..." ) ( ( trainX , trainY ) , ( testX , testY ) ) = cifar10 . load_data ( ) trainX = trainX . astype ( "float" ) testX = testX . astype ( "float" ) |
從那裡我們對資料應用平均減法:
| 55 56 57 58 | # apply mean subtraction to the data mean = np . mean ( trainX , axis = 0 ) trainX -= mean testX -= mean |
在 第56行,我們計算所有訓練影象的平均值,然後是 第57和58行,其中我們從訓練和測試集中的每個影象中減去平均值。
相關推薦
使用Keras進行多GPU訓練 multi_gpu_model
使用Keras訓練具有多個GPU的深度神經網路(照片來源:Nor-Tech.com)。 摘要 在今天的部落格文章中,我們學習瞭如何使用多個GPU來訓練基於Keras的深度神經網路。 使用多個GPU使我們能夠獲得準線性加速。 為了驗證這一點,我們在CIFAR-10資料集上訓練了MiniGoog
使用估算器、tf.keras 和 tf.data 進行多 GPU 訓練
文 / Zalando Research 研究科學家 Kashif Rasul 來源 | TensorFlow 公眾號 與大多數 AI 研究部門一樣,Zalando Research 也意識到了對創意進行嘗試和快速原型設計的重要性。隨著資料集變得越來越龐大,
Keras多GPU訓練以及載入權重無效的問題
目錄 1、資料並行 1.1、單GPU或者無GPU訓練的程式碼如下: 1.2、資料並行的多GPU 訓練 2、裝置並行 參考連結 本文講簡單的探討Keras中使用多GPU訓練的方法以及需要注意的地方。有兩種方法可
keras 多GPU訓練,單GPU預測
多GPU訓練 keras自帶模組 multi_gpu_model,此方式為資料並行的方式,將將目標模型在多個裝置上各複製一份,並使用每個裝置上的複製品處理整個資料集的不同部分資料,最高支援在8片GPU上並行。 使用方式: from keras.utils imp
Python機器學習筆記:利用Keras進行多類分類
名稱 encoder 創建 numeric 種類 deep ast 4.0 允許 Keras是一個用於深度學習的Python庫,它包含高效的數值庫Theano和TensorFlow。 本文的目的是學習如何從csv中加載數據並使其可供Keras使用,如何用神經網絡建立
基於Inception v3進行多標籤訓練 修正了錯誤並進一步完善了程式碼
多標籤訓練只適合未修改inception v3網路的情形,不同於遷移學習。本文參考了基於Inception v3進行多標籤訓練 修正了錯誤並進一步完善了程式碼 資料集的準備,假設有3個類,每個類別差不多有50張圖,注意圖片的規模不能太少(一般一個類不小於25張圖),不然在驗證的時候會
Caffe 多GPU訓練問題,以及batch_size 選擇的問題
1. 多GPU訓練時,速度沒有變得更快。 使用多GPU訓練時,每個GPU都會執行一個 Caffe 模型的例項。比如當使用 n n
【TensorFlow】多GPU訓練:示例程式碼解析
使用多GPU有助於提升訓練速度和調參效率。 本文主要對tensorflow的示例程式碼進行註釋解析:cifar10_multi_gpu_train.py 1080Ti下加速效果如下(batch=128) 單卡: 兩個GPU比單個GPU加速了近一倍 :
pytorch 多GPU訓練
當一臺伺服器有多張GPU時,執行程式預設在一張GPU上執行。通過多GPU訓練,可以增大batchsize,加快訓練速度。 from torch.nn import DataParallel num_gp
pytorch多GPU訓練例項與效能對比
以下實驗是我在百度公司實習的時候做的,記錄下來留個小經驗。 多GPU訓練 cifar10_97.23 使用 run.sh 檔案開始訓練 cifar10_97.50 使用 run.4GPU.sh 開始訓練 在叢集中改變GPU呼叫個數修改 run.sh 檔案 nohup
python&Keras實現多GPU或指定GPU的使用
1. keras新版本中加入多GPU並行使用的函式 下面程式段即可實現一個或多個GPU加速: 注意:使用多GPU加速時,Keras版本必須是Keras2.0.9以上版本 from keras.utils.training_utils import multi_gpu_model &n
pyTorch 使用多GPU訓練
1.在pyTorch中模型使用GPU訓練很方便,直接使用model.gpu()。 2.使用多GPU訓練,model = nn.DataParallel(model) 3.注意訓練/測試過程中 inputs和labels均需載入到GPU中 inputs, l
pytorch使用多GPU訓練MNIST
下面的程式碼引數沒有除錯,可能準確率不高,僅僅供參考程式碼格式。 import argparse import torch import torch.nn as nn import torch.optim as optim import torch.nn.
tensorflow 多gpu訓練
當使用多個gpu訓練時,輸入資料為batch_size*num_gpu,這樣模型訓練時間可以大大較小. tensorflow中使用制定gpu可以通過tf.device()實現.例如我想使用0號顯示卡: gpu_ind=0 with tf.device("/g
Pytorch yolov3 多GPU 訓練
pytorch 多gpu訓練:# -*- coding:utf-8 -*- from __future__ import division import datetime import torch import torch.nn as nn import torch.nn.
基於Inception v3進行多標籤訓練
一.下載github開原始碼 從github上下載開原始碼,我們可以發現它需要對訓練資料集的圖片以及圖片標籤做一些改變: 1.將所有訓練影象放在一個資料夾中,並在專案根目錄中建立一個包含所有可能標籤的檔案labels.txt。例如: 2.需要為
[Keras] 使用Keras呼叫多GPU時出現無法儲存模型的解決方法
在使用keras 的並行多路GPU時出現了模型無法儲存,在使用單個GPU時執行完全沒有問題。執行出現can't pickle的問題隨後在網上找了很多解決方法。下面列舉一些我實驗成功的方法。方法一class ParallelModelCheckpoint(ModelCheckp
keras系列︱影象多分類訓練與利用bottleneck features進行微調(三)
不得不說,這深度學習框架更新太快了尤其到了Keras2.0版本,快到Keras中文版好多都是錯的,快到官方文件也有舊的沒更新,前路坑太多。 到發文為止,已經有theano/tensorflow/CNTK支援keras,雖然說tensorflow造勢很多,但是筆
設定可見GPU,進行多顯示卡深度學習訓練
在深度學習中,如果一臺電腦具有多個NVIDIA的GPUs,使用者想要在不同的GPU上訓練不同的網路,那麼在程式中指定佔用的GPU的id,在python中如: import os os.environ[
『TensorFlow』分布式訓練_其二_多GPU並行demo分析(待續)
print all set represent proto copyright keys 20M runners 建議比對『MXNet』第七彈_多GPU並行程序設計 models/tutorials/image/cifar10/cifer10_multi_gpu-trai