
pytorch多GPU訓練例項與效能對比
阿新 • • 發佈:2018-12-20
以下實驗是我在百度公司實習的時候做的,記錄下來留個小經驗。
多GPU訓練
cifar10_97.23 使用 run.sh 檔案開始訓練
cifar10_97.50 使用 run.4GPU.sh 開始訓練
在叢集中改變GPU呼叫個數修改 run.sh 檔案
nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU &
修改 –gres=gpu:2 即可
Python 檔案程式碼修改
parser.add_argument(
修改對應 batch size 大小,保證每塊GPU獲得等量的訓練資料,因為batch_size的改變會影響訓練精度
最容易實現的單GPU訓練改為多GPU訓練程式碼
單GPU:logits, logits_aux = model(input)
多GPU:
if torch.cuda.device_count()>1:#判斷是否能夠有大於一的GPU資源可以呼叫
logits, logits_aux =nn.parallel.data_parallel(model,
else:
logits, logits_aux = model(input)
缺點:不是效能最好的實現方式
優點:程式碼嵌入適應性強,不容易報錯
效能分析
該圖為1到8GPU訓練cifar10——97.23網路的實驗對比
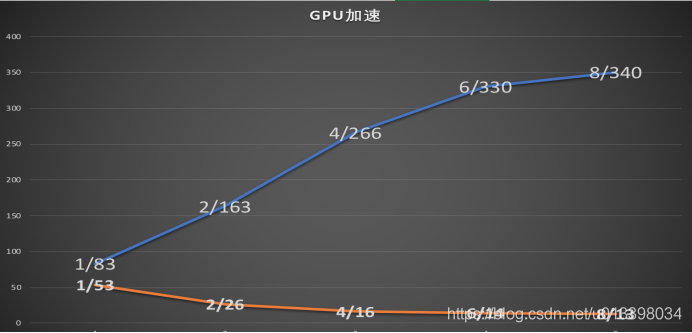
可以看到單核訓練600輪需要53小時、雙核訓練600輪需要26小時、四核16、六核14、八核13。
在可執行7小時的GPU上的對比實驗:單核跑完83輪、雙核跑完163輪、四核跑完266輪
結論:價效比較高的是使用4~6核GPU進行訓練,但是多GPU訓練對於單GPU訓練有所差異,訓練的準確率提升會有所波動,目前發現的是負面的影響。