
翻譯:Clustered Indexes
原文出自:

當葉級別由多個頁面組成時,SQL Server開始構建索引的中間級別,如圖2-6所示。
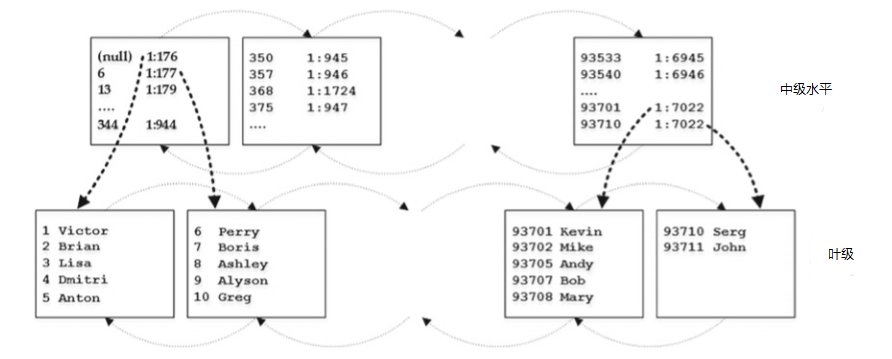
圖2-6. 聚集的索引結構:中級和葉級
中間級別為每個葉級頁面儲存一行。 它儲存兩條資訊:它引用的頁面中的索引鍵的實體地址和最小值。 唯一的例外是第一頁上的第一行,其中SQL Server儲存NULL而不是最小索引鍵值。 通過這種優化,當您在表中插入具有最低鍵值的行時,SQL Server不需要更新非葉級行。 中間級別的頁面也連結到雙鏈表。 SQL Server添加了越來越多的中間級別,直到只包含單個頁面的級別。 此級別稱為根級別,它將成為索引的入口點,如圖2-7

圖2-7. 聚集的索引結構:根級別
如你所見,索引始終具有一個葉級別,一個根級別和零個或多箇中間級別。唯一的例外是索引資料適合單個頁面。在這種情況下,SQL Server不會建立單獨的根級頁面,索引只包含單個葉級頁面。索引中的級別數很大程度上取決於行和索引鍵的大小。例如,4位元組整數列上的索引在中間和根級別上每行需要13個位元組。這13個位元組由一個2位元組的插槽陣列條目,一個4位元組的索引鍵值,一個6位元組的頁面指標和一個1位元組的行開銷組成,這是足夠的,因為索引鍵不包含變數 - length和NULL列。因此,每行可容納8,060位元組/ 13位元組=每頁620行。這意味著,使用一箇中間級別,您可以儲存最多620 * 620 = 384,400個葉級頁面的資訊。如果資料行大小為200位元組,則每個葉級頁面可儲存40行,索引中最多可儲存15,376,000行,只有三個級別。向索引新增另一箇中間級別將基本上涵蓋所有可能的整數值。
注意:在現實生活中,索引碎片會減少這些數字。 我們將在第6章討論索引碎片。
SQL Server可以通過三種不同的方式從索引中讀取資料。 第一個是有序掃描。 假設我們想要執行SELECT Name FROM dbo.Customers ORDER BY CustomerId查詢。 索引的葉級別上的資料已根據CustomerId列值進行排序。 因此,SQL Server可以從第一頁到最後一頁掃描索引的葉級,並按儲存順序返回行。
SQL Server從索引的根頁開始,從那裡讀取第一行。 該行使用表中的最小鍵值引用中間頁面。 SQL Server讀取該頁面並重復該過程,直到找到葉級別的第一頁。 然後,SQL Server開始逐個讀取行,遍歷頁面的連結列表,直到讀取了所有行。 圖2-8說明了這個過程。
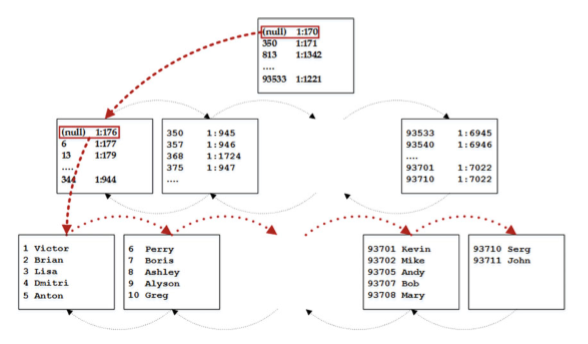
圖2-8. 有序索引掃描
上述查詢的執行計劃顯示了“叢集索引掃描”運算子,其中Ordered屬性設定為true,如圖2-9所示。

圖2-9. 有序索引掃描執行計劃
值得一提的是,觸發有序掃描不需要order by子句。 有序掃描只意味著SQL Server根據索引鍵的順序讀取資料。
SQL Server可以向前和向後兩個方向導航索引。 但是,您必須記住一個重要方面:SQL Server在向後索引掃描期間不使用並行性。
提示:您可以通過檢查執行計劃中的INDEX SCAN或INDEX SEEK操作員屬性來檢查掃描方向。 但請記住,Management Studio不會在執行計劃的圖形表示中顯示這些屬性。 您需要開啟“屬性”視窗以通過在執行計劃中選擇運算子並選擇“檢視/屬性視窗”選單項或按F4鍵來檢視它。
SQL Server企業版具有稱為旋轉木馬掃描的優化功能,允許多個任務共享相同的索引掃描。假設您有會話S1,它正在掃描索引。在掃描中間的某個時刻,另一個會話S2執行需要掃描相同索引的查詢。通過旋轉木馬掃描,S2將S1連線到當前掃描位置。 SQL Server只讀取每個頁面一次,將行傳遞給兩個會話。
當S1掃描到達索引的末尾時,S2開始從索引的開頭掃描資料,直到S2掃描開始的點。旋轉木馬掃描是另一個例子,說明為什麼不能依賴索引鍵的順序以及為什麼在重要時應始終指定ORDER BY子句。
有序掃描之後的下一個訪問方法稱為分配順序掃描。 SQL Server通過IAM頁面訪問表資料,類似於堆表的操作方式。 SELECT名稱FROM dbo.Customers WITH(NOLOCK)查詢和圖2-10說明了這種方法。圖2-11顯示了查詢執行計劃。
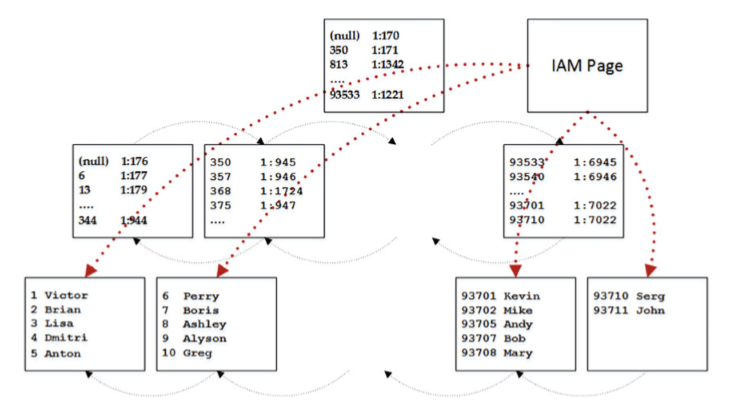
圖2-10. 分配訂單掃描

圖2-11. 分配訂單掃描執行計劃
不幸的是,當SQL Server使用分配順序掃描時,檢測起來並不容易。 即便如此執行計劃中的有序屬性顯示為false,表示SQL Server不關心是否按索引鍵的順序讀取行,而不是使用分配順序掃描。
儘管掃描大型表的啟動成本較高,但分配順序掃描可以更快地掃描大型表。 當表很小時,SQL Server不使用此訪問方法。 另一個重要的考慮是資料一致性 SQL Server不在具有聚簇索引的表中使用轉發指標,並且分配順序掃描可能會產生不一致的結果。 由於頁面拆分導致的資料移動,可以多次跳過或讀取行。 因此,SQL Server通常會避免使用分配順序掃描,除非它讀取READ UNCOMMITTED或SERIALIZABLE事務隔離級別中的資料。
注意:我們將在第6章“索引碎片”中討論頁面拆分和碎片,並討論第三部分“鎖定,阻塞和併發”中的鎖定和資料一致性。
最後一個索引訪問方法稱為索引查詢。 SELECT名稱來自dbo.Customers WHERE CustomerId BETWEEN 4和7查詢以及圖2-12說明了操作。

圖2-12. 索引尋求
為了從表中讀取行的範圍,SQL Server需要從範圍中找到具有最小鍵值的行,即4. SQL Server以根頁面開始,其中第二行引用頁面 最小鍵值350.它大於我們要查詢的鍵值(4),SQL Server讀取根頁面第一行引用的中間級資料頁(1:170)。
同樣,中間頁面將SQL Server引導到第一個葉級頁面(1:176)。 SQL Server讀取該頁面,然後它讀取CustomerIds等於4和5的行,最後,它從第二頁讀取剩餘的兩行。
執行計劃如圖2-13所示。
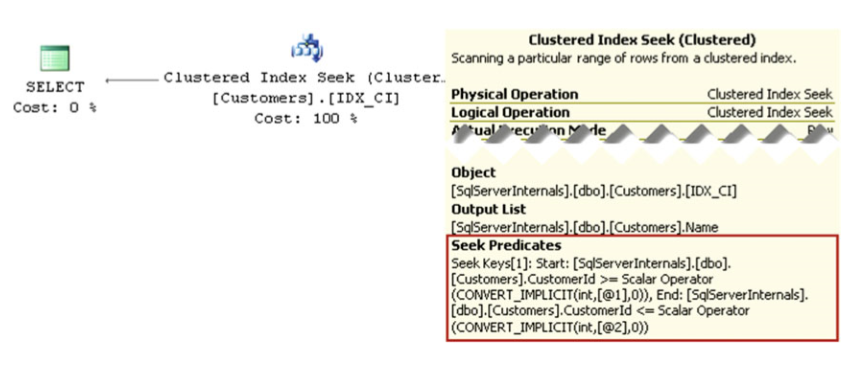
圖2-13. 索引尋求執行計劃
你可以猜測,索引搜尋比索引掃描更有效,因為SQL Server只處理行和資料頁的子集,而不是掃描整個表。
從技術上講,索引搜尋操作有兩種。第一種稱為單例查詢,有時稱為點查詢,其中SQL Server尋找並返回單行。你可以考慮將WHERE CustomerId = 2謂詞作為示例。另一種型別的索引查詢操作稱為範圍掃描,它要求SQL Server查詢鍵的最低值或最高值,並掃描(向前或向後)行集,直到達到掃描範圍的末尾。 CustomerId BETWEEN 4和7之間的謂詞WHERE導致範圍掃描。這兩種情況都在執行計劃中顯示為INDEX SEEK操作。
你可以猜到,範圍掃描完全可以強制SQL Server處理索引中的大量甚至所有資料頁。例如,如果你將查詢更改為使用WHERE CustomerId> 0謂詞,則SQL Server將讀取所有行/頁,即使您在執行計劃中顯示了Index Seek運算子。您必須牢記此行為,並始終在查詢效能調整期間分析範圍掃描的效率。
關係資料庫中有一個名為SARGable謂詞的概念,它代表SearchArg ement能夠。如果索引存在,如果SQL Server可以使用索引查詢操作,則謂詞是SARGable。簡而言之,當SQL Server可以隔離要處理的索引鍵值的單個值或範圍時,謂詞是SARGable,因此在謂詞評估期間限制搜尋。顯然,使用SARGable謂詞編寫查詢並儘可能利用索引查詢是有益的。
SARGable謂詞包括以下運算子:=,>,> =,<,<=,IN,BETWEEN和LIKE(在字首匹配的情況下)。非SARGable運算子包括NOT,<>,LIKE(在非字首匹配的情況下)和NOT IN。
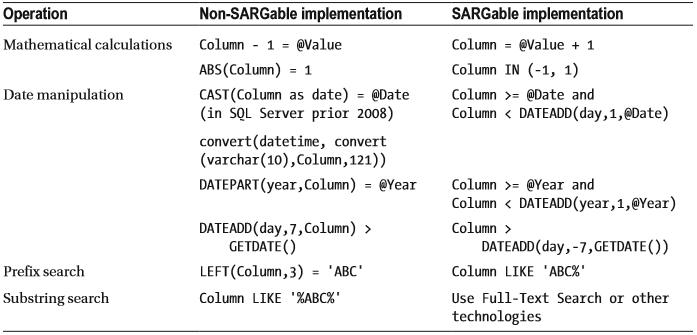
使謂詞非SARGable的另一種情況是對錶列使用函式或數學計算。 SQL Server必須為其處理的每一行呼叫該函式或執行計算。幸運的是,在某些情況下,您可以重構查詢以使這樣的謂詞成為SARGable。表2-1列出了一些例子。
表2-1. 將非SARGable謂詞重構為SARGable的示例
您必須牢記的另一個重要因素是型別轉換。 在某些情況下,您可以使用不正確的資料型別使謂詞非SARGable。 讓我們建立一個帶有varchar列的表,並用一些資料填充它,如清單2-6所示。
清單2-6 SARG謂詞和資料型別:測試表建立
create table dbo.Data ( VarcharKey varchar(10) not null, Placeholder char(200) ); create unique clustered index IDX_Data_VarcharKey on dbo.Data(VarcharKey); ;with N1(C) as (select 0 union all select 0) -- 2 rows ,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows ,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows ,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows ,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows ,IDs(ID) as (select row_number() over (order by (select null)) from N5) insert into dbo.Data(VarcharKey) select convert(varchar(10),ID) from IDs;
聚集索引鍵列定義為varchar,即使它儲存整數值。 現在,讓我們執行兩個選擇,如清單2-7所示,並檢視執行計劃。
清單2-7 SARG謂詞和資料型別:使用整數引數選擇
declare @IntParam int = '200' select * from dbo.Data where VarcharKey = @IntParam; select * from dbo.Data where VarcharKey = convert(varchar(10),@IntParam);
如圖2-14所示,對於整數引數,SQL Server掃描聚集索引,將varchar轉換為每行的整數。 在第二種情況下,SQL Server在開始時將整數引數轉換為varchar,並使用更高效的聚集索引查詢操作。
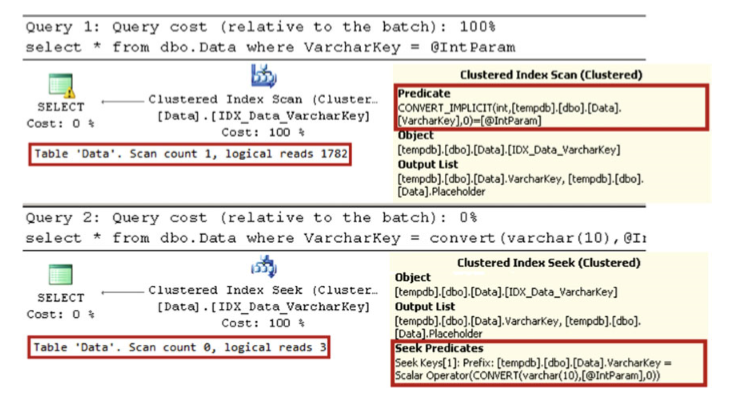
圖2-14. SARG謂詞和資料型別:帶整數引數的執行計劃
提示:請注意連線謂詞中的列資料型別。 隱式或顯式資料型別轉換可能會顯著降低查詢的效能。
在unicode字串引數的情況下,您將觀察到非常類似的行為。 讓我們執行清單2-8中所示的查詢。 圖2-15顯示了語句的執行計劃。
清單2-8 SARG謂詞和資料型別:使用字串引數選擇
select * from dbo.Data where VarcharKey = '200'; select * from dbo.Data where VarcharKey = N'200'; -- unicode parameter

圖2-15. S ARG謂詞和資料型別:帶有引數的執行計劃
如你所見,對於varchar列,unicode字串引數是非SARGable。 這是一個比看起來更大的問題。 雖然很少以這種方式編寫查詢,如清單2-8所示,但現在大多數應用程式開發環境都將字串視為unicode。 因此,除非將引數資料型別顯式指定為varchar,否則SQL Server客戶端庫會為字串物件生成unicode(nvarchar)引數。 這使得謂詞不具有SARG,並且由於不必要的掃描,它可能導致主要的效能命中,即使對varchar列進行索引也是如此。
要點:始終在客戶端應用程式中指定引數資料類 例如,在ADO.Net中,使用Parameters.Add(“@ ParamName”,SqlDbType.Varchar,<Size>)。Value = stringVariable而不是Parameters.Add(“@ ParamName”)。Value = stringVariable overload。 在ORM框架中使用對映來顯式指定類中的非unicode屬性。
值得一提的是,對於nvarchar unicode資料列,varchar引數是SARGable。