
對scrapy經典框架爬蟲原理的理解
https://www.cnblogs.com/themost/p/7131234.html
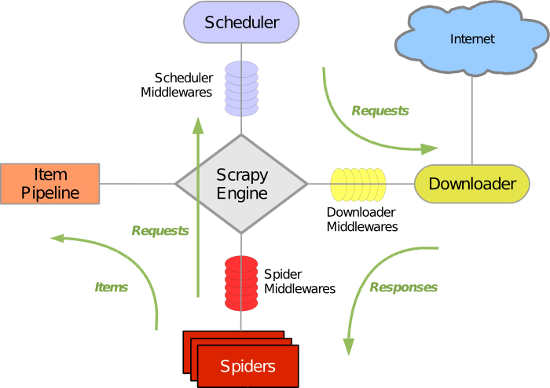
1,spider開啟某網頁,獲取到一個或者多個request,經由scrapy engine傳送給排程器scheduler request特別多並且速度特別快會在scheduler形成請求佇列queue,由scheduler安排執行 2,schelduler會按照一定的次序取出請求,經由引擎, 下載器中間鍵,傳送給下載器dowmloader 這裡的下載器中間鍵是設定在請求執行前,因此可以設定代理,請求頭,cookie等 3,下載下來的網頁資料再次經過下載器中間鍵,經過引擎,經過爬蟲中間鍵傳送給爬蟲spiders 這裡的下載器中間鍵是設定在請求執行後,因此可以修改請求的結果 這裡的爬蟲中間鍵是設定在資料或者請求到達爬蟲之前,與下載器中間鍵有類似的功能 4,由爬蟲spider對下載下來的資料進行解析,按照item設定的資料結構經由爬蟲中間鍵,引擎傳送給專案管道itempipeline 這裡的專案管道itempipeline可以對資料進行進一步的清洗,儲存等操作 這裡爬蟲極有可能從資料中解析到進一步的請求request,它會把請求經由引擎重新發送給排程器shelduler,排程器迴圈執行上述操作 5,專案管道itempipeline管理著最後的輸出
相關推薦
對scrapy經典框架爬蟲原理的理解
https://www.cnblogs.com/themost/p/7131234.html 1,spider開啟某網頁,獲取到一個或者多個request,經由scrapy engine傳送給排程器scheduler request特別多並且速度特別快會在scheduler形成
Android之對Volley網路框架的一些理解
##前言 Volley這個網路框架大家並不陌生,它的優點網上一大堆, 適合網路通訊頻繁操作,並能同時實現多個網路通訊、擴充套件性強、通過介面配置之類的優點。在寫這篇文章之前,特意去了解並使用Volley這個網路框架,文章是對Volley的一點點理解,如有寫得不
一篇文章教會你理解Scrapy網絡爬蟲框架的工作原理和數據采集過程
爬蟲 爬蟲程序 初始 download 設置 lazy tex 保存 apt 今天小編給大家詳細的講解一下Scrapy爬蟲框架,希望對大家的學習有幫助。 1、Scrapy爬蟲框架 Scrapy是一個使用Python編程語言編寫的爬蟲框架,任何人都可以根據自己的需求進行修改,
10 scrapy框架解讀--深入理解爬蟲原理
scrapy框架結構圖: 組成部分介紹: Scrapy Engine: 負責元件之間資料的流轉,當某個動作發生時觸發事件 Scheduler: 接收requests,並把他們入
python爬蟲入門(六) Scrapy框架之原理介紹
Scrapy框架 Scrapy簡介 Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛。 框架的力量,使用者只需要定製開發幾個模組就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。 Scrapy 使用了 Twi
第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄—獲取Scrapy框架Cookies
pid 設置 ade form 需要 span coo decode firefox 第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄 模擬瀏覽器登錄 start_requests()方法,可以返回一個請求給爬蟲的起始網站,這個返回的請求相
Python爬蟲【五】Scrapy分布式原理筆記
啟動 size inf p s 集合 內存 運行 請求 max Scrapy單機架構 在這裏scrapy的核心是scrapy引擎,它通過裏面的一個調度器來調度一個request的隊列,將request發給downloader,然後來執行request請求 但是這些requ
安卓專案實戰之強大的網路請求框架okGo使用詳解(一):實現get,post基本網路請求,下載上傳進度監聽以及對Callback自定義的深入理解
1.新增依賴 //必須使用 compile 'com.lzy.net:okgo:3.0.4' //以下三個選擇新增,okrx和okrx2不能同時使用,一般選擇新增最新的rx2支援即可 compile 'com.lzy.net:okrx:1.0.2' compile 'com.lzy
scrapy框架爬蟲爬取糗事百科 之 Python爬蟲從入門到放棄第不知道多少天(1)
Scrapy框架安裝及使用 1. windows 10 下安裝 Scrapy 框架: 前提:安裝了python-pip 1. windows下按住win+R 輸入cmd 2. 在cmd 下 輸入 pip install scrapy pip inst
Python的scrapy框架爬蟲專案中加入郵箱通知(爬蟲啟動關閉等資訊以郵件的方式傳送到郵箱)
前面關於傳送郵件的部落格參考:普通郵件部落格——點選開啟連結 帶附件的郵件——點選開啟連結 準備: 1、建立scrapy爬蟲專案 2、程式碼主要是兩部分: 呈上程式碼 第一部分是傳送郵
scrapy框架學習,理解不深得到的問題,我遇到的 from avimageitems.items import AvimageItem ModuleNotFoundError: No module named 'scrapy name'
心情複雜呀,這個問題之前找不到解決的思路,原因是沒有人會像我這麼粗心的,沒有認真去看書就寫,不過我是真的沒注意到這個框架名的是什麼,現在才發現setting中的BOT_NAME的作用,不過我是在之前的課程裡瞭解到的
Scrapy框架爬蟲小說網工作流程
1.需求工具 pycharm 小說網的域名 (www.qisuu.com) 第一步—–建立檔案 建立成功後顯示如圖: 這裡寫圖片描述 第二步——將建立在桌面上的scrapy檔案用pycharm開啟: 這是建立成功後在pycharm中的顯示 這裡寫圖片
Pycharm中對scrapy爬蟲工程開啟除錯模式(親測有效)
1、首先通過命令列建立scrapy爬蟲專案,新增爬蟲檔案。然後在scrapy.cfg同級目錄下建立一個除錯程式, 結構如下: 在main.py檔案中輸入引入scrapy.cmdline進行在scrapy中執行類cmd命令 from scrapy.cmdline import
Scrapy框架爬蟲登入與利用打碼介面實現自動識別驗證碼
if len(yzhm) > 0: print("出現驗證碼,請輸入驗證碼") print('驗證碼圖片地址:',yzhm) #將驗證碼圖片儲存到本地 file_path = os.path.join(os.
對IIS7經典模式和整合模式的理解
從IIS6新增應用程式池的概念,到現在IIS7,對HTTP請求處理功能已經越來越精確化和不斷改善,IIS7應用程式池新增了經典模式和整合模式可供選擇,不管官方還是一些書籍或文章都有介紹,但多數過於官方話,下面白話一下我對經典模式和整合模式的理解,希望能對自己以後和其他人更貼切的參考。涉及IIS解析ASP.
Python爬蟲之scrapy框架爬蟲步驟
1.先建立一個資料夾用來執行整個爬蟲專案 2.在PowerShell 中:cd 進入資料夾所在位置 3.通過scrapy 命令建立爬蟲專案: scrapy startprojec
使用Scrapy框架爬蟲例項
給大家安利一篇文章:小白進階之Scrapy第一篇 這篇文章一步步講如何使用Scrapy框架進行網頁爬蟲,簡直是初學者的福音。 我接下來的內容也是按照他的思路寫的,寫這篇文章的目的是為了整理一下思路,把一些關鍵點列出來,大家想詳細閱讀的直接看上面推薦的文章就行了
Scrapy:框架組成與工作原理——元件與資料流
Scrapy元件與資料流 1.Scrapy元件與資料流 ENGINE:引擎,是scrapy框架的核心;內部元件 SCHEDULER:排程器,負責對SPIDER提交的下載請求進行排程;內部元件 DOWNLOADER:下載器,負責下載頁面,即傳送HTTP請求和接
Python爬蟲系列之----Scrapy(一)爬蟲原理
一、Scrapy簡介 Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。 Scrapy 使用 Twisted這個
初識Scrapy框架+爬蟲實戰(7)-爬取鏈家網100頁租房資訊
Scrapy簡介 Scrapy,Python開發的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。Scrapy吸引人的地方在於它是一個框架,任何人都可以根