
python爬蟲入門(六) Scrapy框架之原理介紹
Scrapy框架
Scrapy簡介
-
Scrapy是用純Python實現一個為了爬取網站資料、提取結構性資料而編寫的應用框架,用途非常廣泛。
-
框架的力量,使用者只需要定製開發幾個模組就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要對手是Tornado)非同步網路框架來處理網路通訊,可以加快我們的下載速度,不用自己去實現非同步框架,並且包含了各種中介軟體介面,可以靈活的完成各種需求。
Scrapy架構
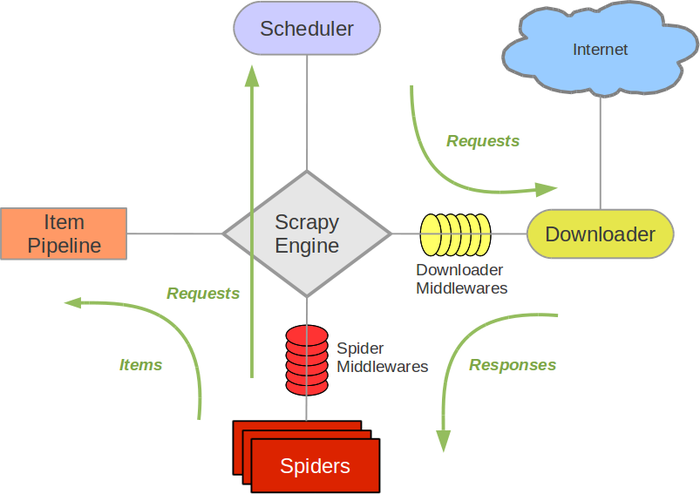
-
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等。 -
Scheduler(排程器): 它負責接受引擎傳送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。 -
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理, -
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器), -
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、儲存等)的地方. -
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件。 -
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spider中間通訊的功能元件(比如進入Spider的Responses;和從Spider出去的Requests)
白話講解Scrapy運作流程
程式碼寫好,程式開始執行...
-
引擎:Hi!Spider, 你要處理哪一個網站? -
Spider:老大要我處理xxxx.com。 -
引擎:你把第一個需要處理的URL給我吧。 -
Spider:給你,第一個URL是xxxxxxx.com。 -
引擎:Hi!排程器,我這有request請求你幫我排序入隊一下。 -
排程器:好的,正在處理你等一下。 -
引擎:Hi!排程器,把你處理好的request請求給我。 -
排程器:給你,這是我處理好的request -
引擎:Hi!下載器,你按照老大的下載中介軟體的設定幫我下載一下這個request請求 -
下載器:好的!給你,這是下載好的東西。(如果失敗:sorry,這個request下載失敗了。然後引擎告訴排程器,這個request下載失敗了,你記錄一下,我們待會兒再下載) -
引擎:Hi!Spider,這是下載好的東西,並且已經按照老大的下載中介軟體處理過了,你自己處理一下(注意!這兒responses預設是交給def parse()這個函式處理的) -
Spider:(處理完畢資料之後對於需要跟進的URL),Hi!引擎,我這裡有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item資料。 -
引擎:Hi !管道我這兒有個item你幫我處理一下!排程器!這是需要跟進URL你幫我處理下。然後從第四步開始迴圈,直到獲取完老大需要全部資訊。 -
管道``排程器:好的,現在就做!
製作Scrapy爬蟲步驟
1.新建專案
scrapy startproject mySpider

scrapy.cfg :專案的配置檔案 mySpider/ :專案的Python模組,將會從這裡引用程式碼 mySpider/items.py :專案的目標檔案 mySpider/pipelines.py :專案的管道檔案 mySpider/settings.py :專案的設定檔案 mySpider/spiders/ :儲存爬蟲程式碼目錄
2.明確目標(mySpider/items.py)
想要爬取哪些資訊,在Item裡面定義結構化資料欄位,儲存爬取到的資料
3.製作爬蟲(spiders/xxxxSpider.py)
import scrapy class ItcastSpider(scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn"] start_urls = ( 'http://www.itcast.cn/', ) def parse(self, response): pass
-
name = "":這個爬蟲的識別名稱,必須是唯一的,在不同的爬蟲必須定義不同的名字。 -
allow_domains = []是搜尋的域名範圍,也就是爬蟲的約束區域,規定爬蟲只爬取這個域名下的網頁,不存在的URL會被忽略。 -
start_urls = ():爬取的URL元祖/列表。爬蟲從這裡開始抓取資料,所以,第一次下載的資料將會從這些urls開始。其他子URL將會從這些起始URL中繼承性生成。 -
parse(self, response):解析的方法,每個初始URL完成下載後將被呼叫,呼叫的時候傳入從每一個URL傳回的Response物件來作為唯一引數,主要作用如下:
4.儲存資料(pipelines.py)
在管道檔案裡面設定儲存資料的方法,可以儲存到本地或資料庫
溫馨提醒
第一次執行scrapy專案的時候
出現-->"DLL load failed" 錯誤提示,需要安裝pypiwin32模組
先寫個簡單入門的例項
(1)items.py
想要爬取的資訊
# -*- coding: utf-8 -*- import scrapy class ItcastItem(scrapy.Item): name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
(2)itcastspider.py
寫爬蟲程式
#!/usr/bin/env python # -*- coding:utf-8 -*- import scrapy from mySpider.items import ItcastItem # 建立一個爬蟲類 class ItcastSpider(scrapy.Spider): # 爬蟲名 name = "itcast" # 允許爬蟲作用的範圍 allowd_domains = ["http://www.itcast.cn/"] # 爬蟲起始的url start_urls = [ "http://www.itcast.cn/channel/teacher.shtml#", ] def parse(self, response): teacher_list = response.xpath('//div[@class="li_txt"]') # 所有老師資訊的列表集合 teacherItem = [] # 遍歷根節點集合 for each in teacher_list: # Item物件用來儲存資料的 item = ItcastItem() # name, extract() 將匹配出來的結果轉換為Unicode字串 # 不加extract() 結果為xpath匹配物件 name = each.xpath('./h3/text()').extract() # title title = each.xpath('./h4/text()').extract() # info info = each.xpath('./p/text()').extract() item['name'] = name[0].encode("gbk") item['title'] = title[0].encode("gbk") item['info'] = info[0].encode("gbk") teacherItem.append(item) return teacherItem
輸入命令:scrapy crawl itcast -o itcast.csv 儲存為 ".csv"的格式
管道檔案pipelines.py的用法
(1)setting.py修改
ITEM_PIPELINES = { #設定好在管道檔案裡寫的類 'mySpider.pipelines.ItcastPipeline': 300, }
(2)itcastspider.py
#!/usr/bin/env python # -*- coding:utf-8 -*- import scrapy from mySpider.items import ItcastItem # 建立一個爬蟲類 class ItcastSpider(scrapy.Spider): # 爬蟲名 name = "itcast" # 允許爬蟲作用的範圍 allowd_domains = ["http://www.itcast.cn/"] # 爬蟲其實的url start_urls = [ "http://www.itcast.cn/channel/teacher.shtml#aandroid", ] def parse(self, response): #with open("teacher.html", "w") as f: # f.write(response.body) # 通過scrapy自帶的xpath匹配出所有老師的根節點列表集合 teacher_list = response.xpath('//div[@class="li_txt"]') # 遍歷根節點集合 for each in teacher_list: # Item物件用來儲存資料的 item = ItcastItem() # name, extract() 將匹配出來的結果轉換為Unicode字串 # 不加extract() 結果為xpath匹配物件 name = each.xpath('./h3/text()').extract() # title title = each.xpath('./h4/text()').extract() # info info = each.xpath('./p/text()').extract() item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] yield item
(3)pipelines.py
資料儲存到本地
# -*- coding: utf-8 -*- import json class ItcastPipeline(object): # __init__方法是可選的,做為類的初始化方法 def __init__(self): # 建立了一個檔案 self.filename = open("teacher.json", "w") # process_item方法是必須寫的,用來處理item資料 def process_item(self, item, spider): jsontext = json.dumps(dict(item), ensure_ascii = False) + "\n" self.filename.write(jsontext.encode("utf-8")) return item # close_spider方法是可選的,結束時呼叫這個方法 def close_spider(self, spider): self.filename.close()
(4)items.py
# -*- coding: utf-8 -*- import scrapy class ItcastItem(scrapy.Item): name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()