Lucene(一):概述
以下圖片均來自極客學院視訊截圖:https://www.jikexueyuan.com/course/937_3.html?ss=2
一、全文檢索概述
1.1 資料分類
資料分類可以分為:
結構化資料:具有固定格式或有限長度的資料(例如資料庫中的表)
非結構化資料:不定長度或無固定格式的資料(例如郵件、word文件、網頁這些型別的資料)
半結構化資料:介於結構化與非結構化之間(例如xml、json格式的資料)
對於想資料庫這種結構化資料我們通常使用sql語句來進行檢索,對於非結構化的資料我們通常有“順序掃描”和“全文檢索”的方式來檢索資料。
順序掃描:從第一條一直檢索到最後一條,然後把符合檢索要求的結果返回,可想而知這種方式無論是從時間上還是資源上都會有很大的浪費。
全文檢索的過程如下圖。左邊是把結構化資料與非結構化資料以及半結構化資料通過lucene來創建出索引檔案,右邊是通過獲取使用者檢索的關鍵字去檢索索引庫然後把結果返回給使用者。這幅圖中起到關鍵作用的就是“索引”。

索引的含義:下圖的意思是,“Lucene”這個這個詞在第1篇文件與第3篇文件出現過,“Hadoop”這個詞在第3、5、7、8、9這五篇文件中出現過,這幅圖的左側就好比“新華字典”的拼音檢索或部首檢索,圖的右邊稱為“倒排表”。對於下圖這一個整體的功能我們稱為“反向索引”-----這種由字串到檔案的對映是檔案到字串對映的反向過程。

1.2 全文索引過程
1.2.1 建立索引
建立索引的三部曲可以總結為以下三步
- 需要檢索的資料(Documents)
- 分詞技術(Analyzer)
- 索引建立(indexer)

例如:
a. 需要檢索的資料Documents為(極客學院課程、Lucene案例開發、Lucene實時搜尋)
b. 分詞技術(這裡是標準分詞,標準分詞就是把中文分成一個個獨立的單詞,對英文就是轉換成詞根)
極|客|學|院|課|程
Lucene|案|例|開|發
Lucene|實|時|搜|索
c. 建立索引檔案

因為lucene這個詞在第2、3兩篇文件中都出現過,把它合併成如下圖(Lucene這個詞的首字母L程式設計小寫是分詞技術的作用)

1.3 全文檢索例項
上面的所以表以及建立好了,那麼如何基於這個所以表進行檢索呢?
檢索步驟可以總結為下圖:
- 搜尋的關鍵字(keywords)
- 分詞技術(Analyzer),注意這裡的分成技術要與建立索引時使用的分詞技術儘量相同
- 檢索索引(Search)
- 返回結果

例如:
a. 獲得使用者搜尋的關鍵字(Lucene案例)
b. 分詞技術
lucene|案|例
c. 檢索索引
通過索引檔案可以知道,lucene這個詞在第2、3篇文章裡出現過,“案”字和“例”字都在第2篇文章出現過

d. 返回結果是第2篇文章
二、Lucene數學模型
通過1.2 我們瞭解了全文檢索的過程,瞭解了全文檢索的過程再學習Lucene的全文檢索,在學習Lucene的全文檢索之前,我們先學習一下Lucene的數學模型。
2.1 什麼是文件、域、詞元 以及他們三者之間的關係
2.1.1 文件
文件是Lucene索引和搜尋的原子單位,文件為包含一個或多個域的容器,而“域”則依次包含“真正的”被搜尋的內容(指的是詞元),域值通過分詞技術處理,得到多個詞元。
2.1.2 文件、域、詞元之間的關係
例如:一篇小說資訊可以稱為一個文件,小說資訊又包含多個域,比如標題、作者、簡介等,對標題這個域採用分詞技術,又可以得到一個或多個詞元(詞元是真正被搜尋的內容)。
2.2 詞元權重計算
權重:詞元對文件的重要程度。
Term Frequency(tf):即此term在文件中出現的次數,tf越大,說明該詞元越重要。
Document Frequency(df):即有多少文件包含此term,df越大,說明該詞元越不重要。
計算公式:
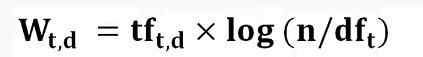
Wt,d 詞元t在文件d中的權重
tft,d 詞元t在文件d中出現的次數
n 索引中文件的總數
dft 有多少篇文件包含詞元t
在上面我們可以知道一篇文件可以分解為多個詞元,再根據此公式我們就可以把詞元轉換成權重,也就是說一篇文件可以表示成詞元的權重,因此就可以把文件表示成權重的向量,也就是下面所說的空間向量模型。
2.3 空間向量模型
把文件表示成向量,把向量放到空間模型中。這個空間向量模型分為N個維度,每一個維度代表一個詞元,N代表所有的文件分成的詞元總數,這樣一篇文件就可以在這個N維空間中表示成一個向量。假如一篇文件它不包含term2,那麼他在term2上的權重就是0。

2.4 索引檢索
如何基於2.3的空間向量模型去檢索
對於搜尋關鍵字採用同樣的分詞技術把關鍵字分成N個詞元,依次計算詞元的權重,把搜尋關鍵字表示在這個N維空間向量模型中,這樣我們就可以用詞元原文件之間的夾角來表示它們之間的相似度,這裡我們使用夾角的餘弦值作為相關性的打分標準,夾角越小,餘弦值越大,打分越高,相關性越大。對於這樣一個空間向量模型它不僅僅可以用於全文檢索,它還能用於“輿情分析領域”的語句情感分析,在“資料探勘領域”的文字分類演算法。
三、Lucene檔案結構
前面接收了lucene的數學模型,瞭解了lucene是基於什麼樣的原理來完成全文檢索的。lunce是如何儲存上面所說的空間向量資訊,在計算機中以什麼樣的形式存在。
3.1 層次結構
- 索引(Index):一個索引放在一個資料夾中
- 段(Segment):一個索引可以有很多段,段與端之間是獨立的,新增新的文件可能產生新的段,不同的段可以合併成一個新段。
- 文件(Document):文件是建立索引的基本單位,不同的文件儲存在不同的段中,一個端可以包含多個文件。
- 域(Field):一個文件包含不同型別的資訊,可以拆分開索引。
- 詞(Term):詞是索引的最小單位,是經過詞發分析和語言處理後的資料。
可以結合上面2.1.2進行理解。這裡再介紹一下索引、段 和 文件、域、詞元之間的關係,為了方便理解,以我們熟悉的資料庫進行舉例
索引相當於資料庫中的表,當表中的記錄達到一定的程度我們需要對錶做分割槽處理,這裡的段也就相當於表中的分割槽,因此也就說索引可以分成多個段,資料表中的記錄又儲存在不同的分割槽中,這裡的段和資料表中的分割槽有一個明顯的區別,就是不同的段可以合併成一個新段,資料表中的分割槽又包含了不同的文件,這裡也是一樣,不同的文件儲存在不同的段中,因此這五個名稱之間的關係也就是:一個索引可以包含一個或多個段,每個段中又儲存了不同的文件,每一篇文件又可以包含不同型別的資訊(也就是域),對於域值我們採用詞法分析和語言處理可以把域值拆分成多個詞元。
3.2 正向資訊
在lucene索引中,儲存了索引到詞的這種關係我們把它稱之為“正向資訊”,準確的說正向資訊就是按層次儲存了索引一直到詞的包含關係。索引–>段–>文件–>域–>詞
3.3 反向資訊
索引中不僅儲存了“索引–>詞”這種正向資訊,同時也儲存了“詞–>索引”這種反向資訊。
反向資訊儲存了詞典的倒排表對映:詞–>文件
3.4 示例
這裡的索引檔案都在index目錄下,可以看到我們在個索引裡只包含一個段segment_1

通過lukeall這個工具可以檢視索引

四、Lucene開發環境的搭建
第一步:建立一個基於maven的web程式
第二步:引入lucene依賴,案例中使用的是4.3.1版本