
re模組:核心函式與方法
1.group和groups的區別:
n.group(N)返回第N組括號匹配的字元
n.group()==n.group(0)==返回所有匹配的字元
n.groups() 返回所有括號匹配的字元,以元組格式,沒有子組的時候將返回 空元組
示例:


具體可見:https://blog.csdn.net/dingding_12345/article/details/52317476
2.re.match() :返回匹配的match物件,預設從給定字串的開頭開始匹配,即使正則表示式沒有用^宣告
match的屬性:
.string 待匹配的文字
.re 匹配使用的pattern 物件
.pos 正則表示式搜尋文字的結束位置
.endpos 正則表示式搜尋文字的結束位置
具體見:https://blog.csdn.net/mmp591/article/details/78585244
3.re.search():返回匹配的match物件
search和match的區別:match函式是隻檢測re是不是在string的開始位置匹配,search會掃描整個string查詢匹配,會掃描整個字串,並返回第一個成功的匹配
4.注意點號 . 是不匹配換行符號\n 和非字元的,在確實要匹配. 號的時候,要使用\進行轉義
5.簡單的電子郵件的正則表示式: \[email protected]
6.匹配邊界:\b \B 可以以border來記憶
舉例:
\b 可以匹配單詞邊界,例如 'er\b' 可以匹配 nerver中的er。但是不能匹配 verb中的er
\B 匹配非單詞邊界。例如 'er\B' 可以匹配 verb中的er,但是不能匹配nerver中的er
7.findall()返回列表。如果findall沒有找到匹配的部分就返回一個空列表,但是如果匹配成功。列表將包含所有成功的匹配部分
8.\s 是指空白,包括空格,換行,tab縮排等所有空白,而\S相反
9.findall和finditer
具體見:https://blog.csdn.net/wali_wang/article/details/50623991
10.sub和subn 實現搜尋和替換的功能
其語法: re.sub(pattern, repl,string[, count])使用repl替換string中每一個匹配的子串後返回替換後的字串,count用於指定最多替換次數,不指定時全部替換
re.subn(pattern,repl,string[, count])
其返回的是 sub(pattern, repl,string[, count]),替換次數
11.split()分割字串
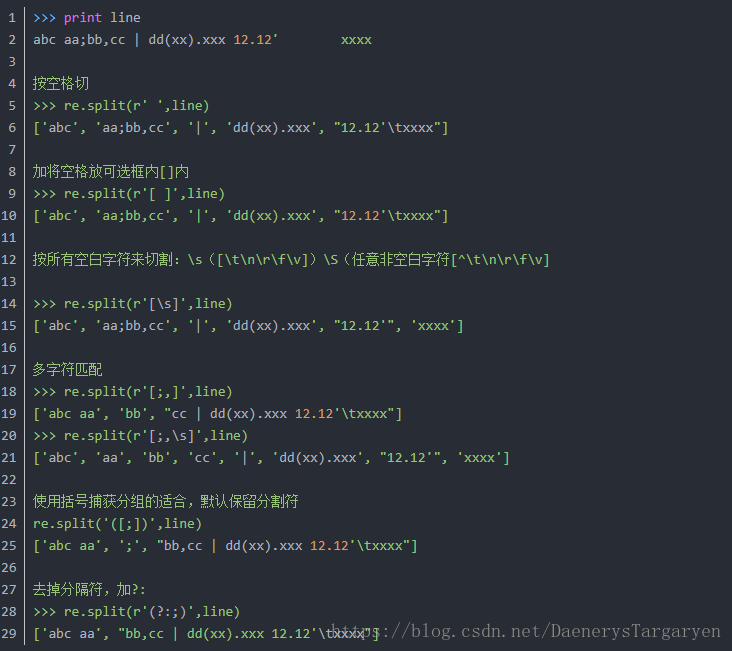
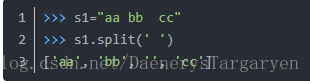
str.split()不支援正則和多個切割符號,不感知空格數量
12.擴充套件符號
具體見:https://blog.csdn.net/oliverkingli/article/details/78990912
13. \s\s+ :表示的是至少擁有兩個以上的空白符