
TensorFlow實現模型斷點訓練,checkpoint模型載入
阿新 • • 發佈:2018-12-06
深度學習中,模型訓練一般都需要很長的時間,由於很多原因,導致模型中斷訓練,下面介紹繼續斷點訓練的方法。
方法一:載入模型時,不必指定迭代次數,一般預設最新
# 儲存模型 saver = tf.train.Saver(max_to_keep=1) # 最多保留最新的模型 # 開啟會話 with tf.Session() as sess: # saver.restore(sess, './log/' + "model_savemodel.cpkt-" + str(20000)) sess.run(tf.global_variables_initializer()) ckpt = tf.train.get_checkpoint_state('./log/') # 注意此處是checkpoint存在的目錄,千萬不要寫成‘./log’ if ckpt and ckpt.model_checkpoint_path: saver.restore(sess,ckpt.model_checkpoint_path) # 自動恢復model_checkpoint_path儲存模型一般是最新 print("Model restored...") else: print('No Model')
方法二:載入時,指定想要載入模型的迭代次數
需要到Log資料夾中,檢視當前迭代的次數,如下:此時為111000次。
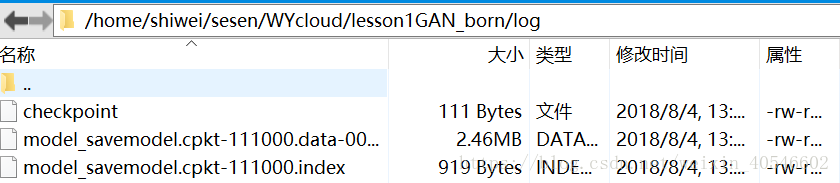
# 儲存模型
saver = tf.train.Saver(max_to_keep=1)
# 開啟會話
with tf.Session() as sess:
saver.restore(sess, './log/' + "model_savemodel.cpkt-" + str(111000))
sess.run(tf.global_variables_initializer())載入模型後,會繼續端點處的變數繼續訓練,那麼是否可以減小剩餘的需要的迭代次數?
模型斷點訓練效果展示:
訓練到167000次後,載入模型重新訓練。設定迭代次數為10000次,(d_step=1000)。原始設定的迭代的次數為1000000,已經訓練了167000次。
Model restored... Iter:0, D_loss:0.5139875411987305, G_loss:2.8023970127105713 Iter:1000, D_loss:0.4400891065597534, G_loss:2.781547784805298 Iter:2000, D_loss:0.5169454216957092, G_loss:2.58009934425354 Iter:3000, D_loss:0.4507023096084595, G_loss:2.584151268005371 Iter:4000, D_loss:0.5746167898178101, G_loss:2.5365757942199707 Iter:5000, D_loss:0.5288565158843994, G_loss:2.426676034927368 Iter:6000, D_loss:0.549595057964325, G_loss:2.820535659790039 Iter:7000, D_loss:0.32620012760162354, G_loss:2.540236473083496 Iter:8000, D_loss:0.4363398551940918, G_loss:2.5880446434020996 Iter:9000, D_loss:0.569464921951294, G_loss:2.5133447647094727 done!
儲存的圖片仍然從頭開始編號,會覆蓋掉之前的圖片。

以前對應編號的取樣圖片為:

若有朋友有高見,還請不吝賜教。