
第一節 自然語言處理概論
Bill Manaris關於自然語言處理提出:
研究在人與人交際中以及在人與計算機交際中的語言問題的一門學科。自然語言處理要研製表示語言能力和語言應用的模型,建立計算框架來實現這樣的模型,提出相應的方法來不斷完善這樣的語言模型,根據這樣的語言模型設計各種使用系統,並探討這些實用系統的評測技術。
研究自然語言處理的意義:
從科學研究的角度,探尋人類通過語言來互動資訊的奧祕,更好地理解語言本身的內在規律。
兩類不同的語言處理模型:
能力模型:(Noam Chomsky-美國語言學家,轉換-生成語法創始人)基於語言學規則的模型,假設人腦中先天就存在語法通則,這種先天的存在能夠通過人類遺傳給後代,總之與生俱來,所以構建這種模型只需把人腦的這種語法通則構造出來即可理解語言。
應用模型:根據不同的語言處理應用而建立的特定語言模型,通常是基於統計的模型。又稱“經驗主義的”語言模型。其建模步驟為:通過大規模真實語料庫,獲得語言各級語言單位上的統計資訊;依據較低階語言單位上的統計資訊,運用相關的統計推理技術計算較高階語言單位上的的統計資訊。
規則與統計相結合——解決相應問題
評測技術是自然語言處理的重要研究專題之一,是國際公認的自然語言處理研究的競技場。
自然語言處理:人工智慧和語言學的交叉學科,研究自然語言的自動生成與理解。(定義不嚴謹)——注意引用權威文獻
自然語言處理是人工智慧和應用語言學的重要分支,與其相關的學科有:語言學、電腦科學、數學、認知心理學、資訊理論、聲學(語音識別、語音合成)、……
自然語言處理相關術語:中文資訊處理、中文語言處理、計算語言學、自然語言理解、智慧化人機介面、……
自然語言處理的知識內容:基礎、應用、資源、評測;
自然語言處理的基礎內容:音位學->形態學->詞彙學->句法學<-語用學<-語義學
音位學:描述音位的結合規律,說明音位怎樣形成語素;"delete file x"-->"dilet'#fail#eks"(音解串)
形態學:研究語素的結合規律,說明語素怎樣形成單詞;"dilet'#fail#eks"-->"delete" "file" "x"(單詞)
詞彙學:描述詞彙系統的規律,說明單詞本身固有的語義特性和語法特性;"delete" "file" "x"-->("delete" VERB)("file" NOUN)("x" ID)(加註了詞性——語法特性)
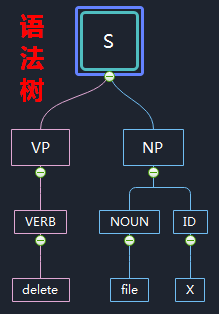
句法學:描述單詞或片語之間的結構規則,說明單詞或片語怎樣構成句子;("delete" VERB)("file" NOUN)("x" ID)-->句法樹(見下圖)
語義學:描述句子中各個成分之間的語義關係,以及怎樣從構成句子的各個成分推匯出整個句子的語義。句法樹(見下圖)-->"delete-file('x')"
語用學:
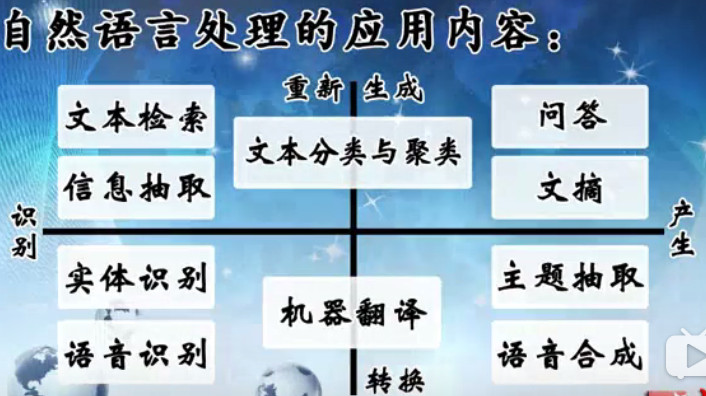
自然語言處理的應用內容:(如上圖所示)
自然語言處理的資源內容:(常用的中文資源有)
北京大學人民日報語料庫(經過精確的詞性標註的語料庫--中文研究比較完備的語料庫);
《現代漢語語法資訊詞典》-北京大學計算語言研究所(5-6萬的漢語常用詞彙逐個給出了其語法的相關標註,以及相關的文法規則);
概念層次網路:中科院資訊所的獨創的純正中國風格的概念層次網路理論;
知網:計算機應用的大型的中文語義詞典
***提出新理論:①能夠被大家所理解;②說清楚它和其他理論的關係。
自然語言處理的評測內容:對自然語言處理的各方面應用作出合理評價,其組成部分有:
評測方法:各個領域有其特有的評測方法;
評測物件:評測的是什麼,速度、精度、適用範圍;
評測量度:精確度、召回率、綜合反映精確度和召回率的f量度、平均準確率、平均準確噪數。
中文語言處理的發展概況:
從漢字資訊處理到漢語資訊處理;如漢字排版系統(漢字資訊處理)
漢語資訊處理:
詞處理:研究內容包括(分詞、詞性標註、名實體識別、詞義消歧);
語句處理:研究內容包括(句法分析,語義分析等)、應用包括(音字轉換、文字校對、語音合成、機器翻譯);
篇章處理:研究內容包括(文摘等的應用,如單文件文摘、多文件文摘等等)。
資訊抽取、問答系統等
統計與規則結合的漢語詞法分析技術,也涉及到語法分析部分內容
從單機資訊處理到網路資訊處理。
中文的主要特點:(與英語相比較)
漢語是大字符集的意音文字;
漢語詞與詞之間沒有空格;
漢語的同義、同音詞比較多;(大挑戰)
漢語沒有形態變化。
中文語言處理髮展的主要困難:
漢語的語法研究尚未規範化;
漢語的語言學知識的量化與形式化的工作滯後;
中文語言處理研究力量分散;
科學的評測機制尚未建立;
自然語言處理的主要課題:
基礎理論:概率與統計理論、統計機器學習理論、人工智慧基本理論、認知科學理論;
人工智慧理論:組合優化演算法,邏輯相關方法;
認知科學理論:
詞法分析主要研究課題:分詞、詞性標註、命名實體識別、新詞發現;
句法分析主要研究課題:上下文無關文法(概率);
語義分析主要研究課題:語義表示、概念語義網路、詞義消歧;
語用分析主要研究課題:自然語言生成、語段分析/對話、機器翻譯;
自然語言處理的主要應用:
語音識別、資訊檢索、文摘、問答、對話機器人、機器翻譯、文字校對、生物資訊學