
人工智慧第二課:認知服務和機器人框架探祕
人工智慧第二課:認知服務和機器人框架探祕
這是《人工智慧系列筆記》的第二篇,我利用週六下午完成課程學習。這一方面是因為內容屬於入門級,並且之前我已經對認知服務和機器人框架比較熟悉。
但是學習這門課程還是很有收穫,這篇筆記時特別加了"探祕"兩個字,這是因為他不僅僅是介紹了微軟的認知服務和機器人框架及其如何快速開始工作,更重要的是也做了很多鋪墊,例如在講文字分析服務(Text Analytics)之前,課程用了相當長的篇幅介紹了文字處理的一些技術原理,畢竟無論是微軟的認知服務,還是其他廠商的服務,或者你自己嘗試去實現,其內部的原理都是類似的。
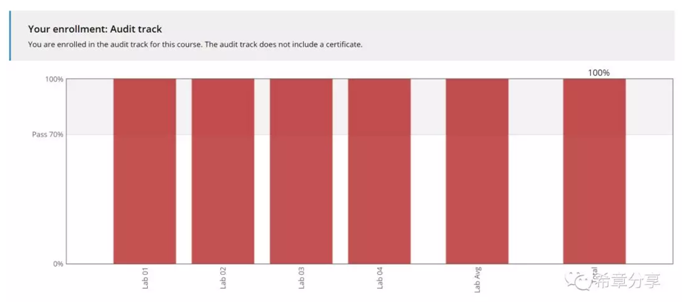
我將給大家分享三個部分的內容
-
文字理解和溝通
-
計算機視覺
-
對話機器人
第一部分:文字理解和溝通
現在人工智慧很火,花樣也很多,可能大家不會想到,很早之前人類對於機器智慧的研究,最主要就是在文字理解和處理這個部分,科學家們想要實現的場景主要如下

這跟人類本身的學習及成長是類似的,一旦機器掌握這些能力,其實就相當於具備了"聽說讀寫"的能力。我據說微軟二十年前創立研究院之處,主要的研究範圍也是在這個領域,二十年過去了還在繼續投資,不斷優化這方面的能力,可見其作為人工智慧的重要性。
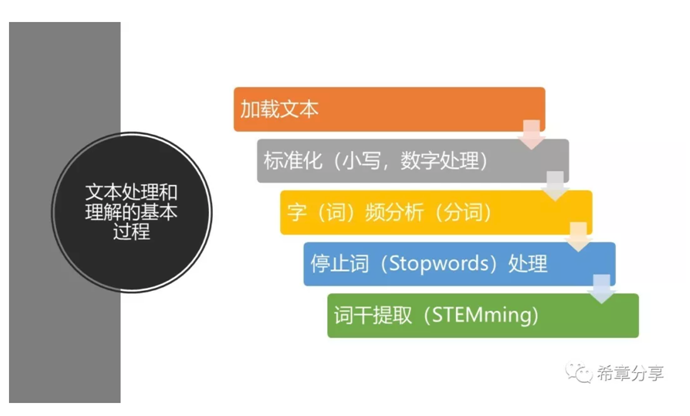
其實這裡提到的大部分過程,可以理解為通常意義上的自然語言處理(Natual Language Processing——NLP)的研究範疇。

本次課程中使用python進行講解,提到了一個關鍵的package:NLTK(Natual Language Toolkit),以及它的幾個更加具體的庫:freqdist 用來做字(詞)頻分析,stem用來做詞幹提取等等。
下面是一些基本的用法
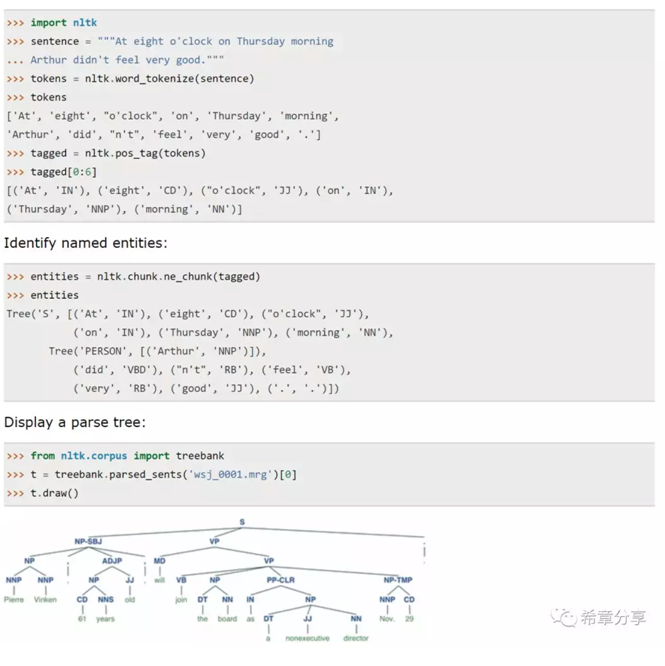
也就是說,其實你用NLTK能做出絕大部分文字理解和處理的場景,當然如果你用微軟的認知服務(Cognitive Service),則可以省去很多基礎性的工作,而是直接專注在業務問題上。
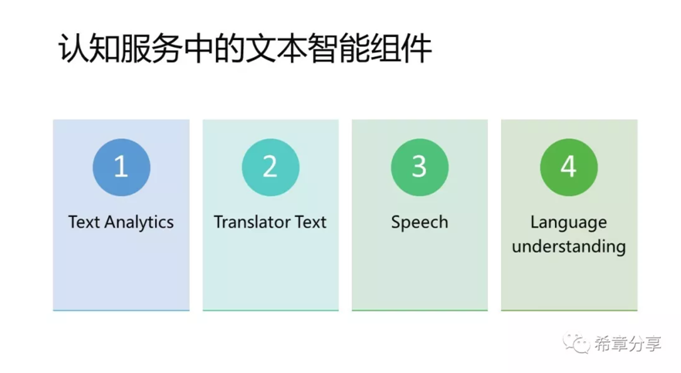
前面三種服務都相對簡單,通常你只需要開通,並且呼叫相關的API 即可,例如 Text Analytics 可用來檢測文字語言,識別其中的實體,關鍵資訊,以及情感分析。
而Language understanding 則相對更加複雜一點,它的全稱是Language understanding intelligence service (Luis),是有一套完整的定義、訓練、釋出的流程。換言之,Luis允許你自定義模型,而前面三者則是利用微軟已經訓練好的模型立即開始工作。申請Luis服務是在Azure的門戶中完成的,而要進行模型定義和訓練,則需要通過 https://luis.ai 這個網站來完成。
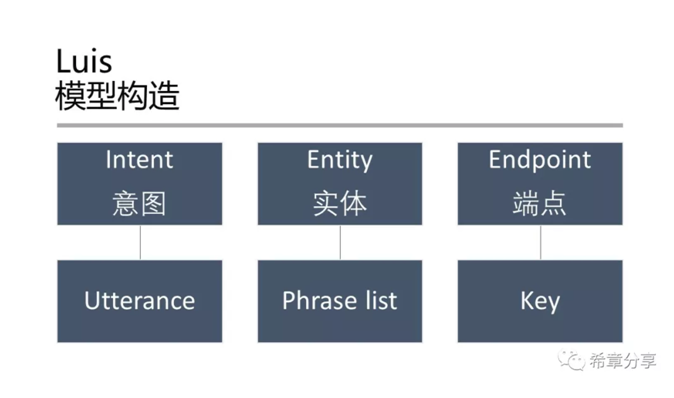
下面是我用來測試的一個模型的其中一個Intent (Luis能同時支援多種語言,甚至也能做到中英文混合文字的理解)
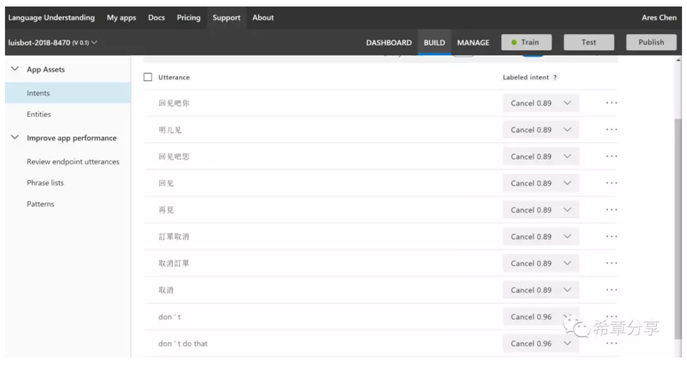
Luis最大的一個使用場合可能是結合本文最後面提到的對話機器人來實現智慧問答。
第二部分:計算機視覺
如果說文字智慧是嘗試學習人類的"聽說讀寫"的能力,那麼計算機視覺則是嘗試模擬人類的眼睛,來實現"看"的能力。

影象分析其實就是好比人類看到一個物體(或者其影像),腦電波反射過來訊號,使得你意識到你看到的是什麼。

這個能力用到了預先訓練好的模型。這個可以通過認知服務中的Computer Vision這個元件實現。
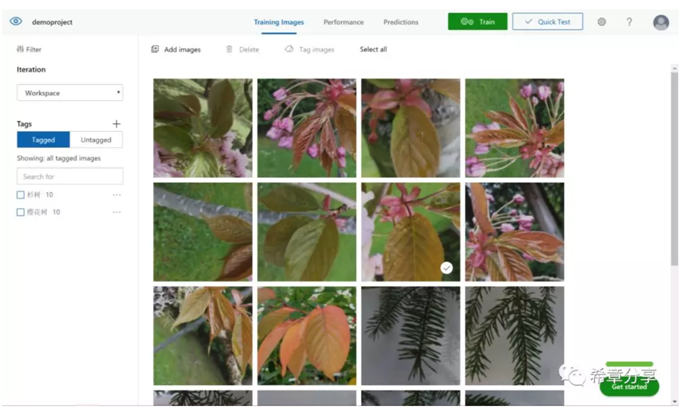
但是,即便是上面的模型已經包含了數以百萬計的照片,但相對而言還是很小的一個集合。所以,如果你想實現自己的影象識別,可以使用認知服務中提供的Custom vision這個能力來實現。
Custom vision擁有一個同樣很酷的主頁:https://customvision.ai/ ,通過這個網站,你可以上傳你預先收集好的照片,並且為其進行標記,通常情況下,每個標記至少需要5張照片,然後通過訓練即可釋出你的服務,並且用於後續的影象識別檢測(例如某個影象是不是汽車,或者香蕉之類的)。
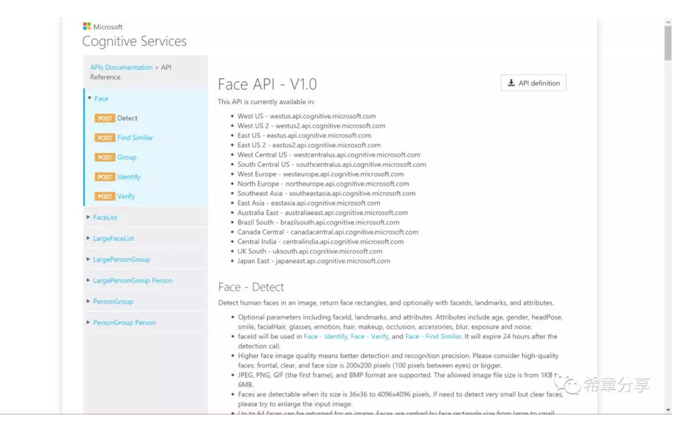
人臉識別,則是特定領域的影象識別,這個應用也是目前在人工智慧領域最火的一個,而也因為臉是如此重要,所以在認知服務中,有一個專門的API,叫Face API。
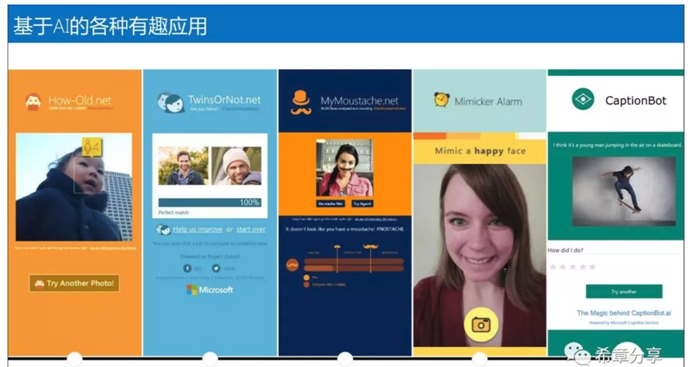
使用這套API,可以做出來很有意思的應用,例如
從技術上說,影象(Image)是由一個一個有顏色的資料點構成的,這些資料點通常用RGB值表示。而視訊(Video)則是由一幅一幅的影象(Image,此時稱為幀)構成的。所以,計算機視覺既然能做到影象的識別和理解(雖然可能會有偏差),那麼從技術上說,它也就具備了對視訊進行識別和理解的能力,如果再加上之前提到的文字智慧,它就能至少實現如下的場景:
-
識別視訊中出現的人臉,以及他們出現的時間軸。如果是名人,也會自動識別出來,如果不是,支援標記,下次也能識別出來。
-
識別視訊中的情感,例如從人臉看出來的高興還是悲傷,以及歡呼聲等環境音。
-
文字識別(OCR)——根據影象生成文字。
-
自動生成字幕,並支援翻譯成其他語言。

第三部分:對話機器人
我記得是在2016年的Build大會上,微軟CEO Sayta 提出了一個新的概念:Conversation as a Platform, 簡稱CaaP,其具體的表現形式就是聊天機器人(chatbot)。
當時的報道,請參考 https://www.businessinsider.sg/microsoft-ceo-satya-nadella-on-conversations-as-a-platform-and-chatbots-2016-3/?r=US&IR=T

對話機器人這個單元,講的就是這塊內容。與人臉識別技術類似,機器人這個技術在這幾年得到了長足的發展和廣泛的應用,甚至到了婦孺皆知的地步。這裡談到的機器人,特指通過對話形式與使用者進行互動,並且提供服務的一類機器人,廣泛地應用於智慧客服、聊天與陪伴、常見問題解答等場合。
建立一個對話機器人真的很簡單,如果你有一個Azure訂閱的話。微軟在早些時候已經將機器人框架(Bot Framework)完全地整合到了Azure平臺。

做一個機器人(Bot)其實真的不難,但要真的實現比較智慧的體驗,還真的要下一番功夫。目前比較常見的做法是,前端用Bot Framework定義和開發Bot(用來與使用者互動),後臺會連線Luis服務或QnA maker服務來實現智慧體驗,如下圖所示。
我在11月份的Microsoft 365 DevDays(開發者大會)上面專門講解了機器人開發,有興趣可以參考 https://github.com/chenxizhang/devdays2018-beijing 的資料。
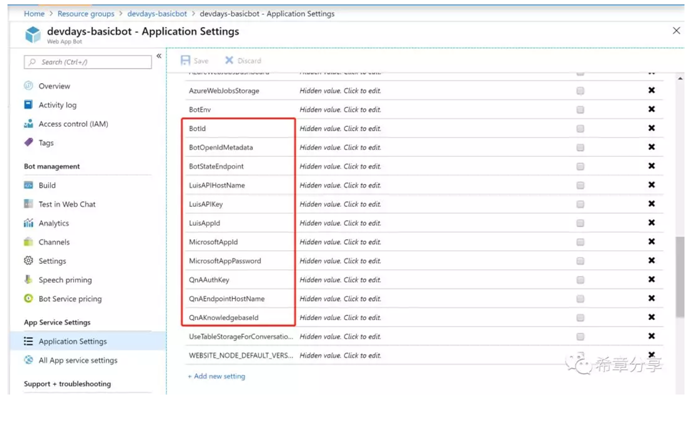
機器人框架 (Bot Framework)的一個強大之處在於,你可以實現編寫一次,處處執行,它通過頻道(Channel)來分發服務。目前支援的頻道至少有16種。
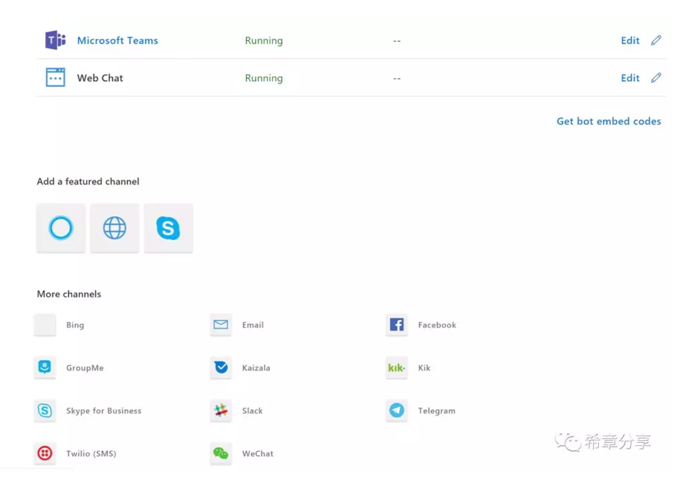
我自己之前用過Web Chat,Microsoft Teams,以及Direct Line和Skype for Business等四種。一直對Cortana這個場景比較感興趣,這次通過學習,終於把這個做成功了,還是挺有意思的。
這項功能,還有一個名稱:Cortana Skills,目前需要用Microsoft Account註冊這個Bot)。
