
REAL-WORD MACHINE LEANING(翻譯本--第一章 什麼是機器學習)
本章內容概要:
- 機器學習基礎
- 相比傳統方法機器學習的優勢
- 機器學習流程概覽
- 模型效能優化方法綜述
1959年,IBM工程師Arthur Samuel 編寫了一個玩跳棋的程式。他為棋盤上的每一個格子都根據獲勝的概率賦予一定的分數。其中,分數是根據一些因素計算出來的,例如,可以根據雙方的棋子數、國王的數量。儘管這個反方很有效果,但是Samuel 讓程式進行了上千場的自我博弈,並利用結果進行重新定義分數。20世紀中期,該程式的能力已經達到了一個高階業餘棋手的水平。
Samuel 通過讓程式進行自我學習提高機器下棋的水平,這既是機器學習。本書的目的不是詳細闡述機器學習演算法的細節。相反,本書的目的是將機器學習更好的融入現實生活中。首先在第一章中展現了真實的商業例子-貸款申請審查,並與傳統的方法進行對比以展現機器學習的優勢。
理解機器是如何學習的
當我們討論到人類學習的時候,會談到機械學習、死記硬背甚至是智商。儘管記憶一些電話號碼或指令可以稱為學習,但是學習通常不止這些。
當小孩們一起玩耍的時候,他們會觀測其他人對自己行為的反應。這些學習觀察會對他們未來的行為產生影響。因此,學習不僅是指知識的收集,也是孩子們建立社會洞察力的過程。
試想一下,在通過卡片教小孩區別貓和狗的時候,你展示一張卡片,小孩做出選擇,然後根據小孩的選擇將選擇正確和錯誤的卡片分開放置。隨著孩子的不斷練習,區分貓和狗的能力越來越強。有趣的是,該過程並沒有實現交給孩子什麼是貓和狗。人類的認知能力中內建分類功能,在小孩熟悉卡片上的貓狗之後,他不僅可以對卡片上的圖片進行識別,同時也可對其他地方的貓狗進行分類。這種通過學習已知知識並泛化到未學習的領域,這是人類和機器學習的關鍵特徵。
當然,人類的學習過程遠比現有高階演算法複雜的多。但是,計算機有更強大的“記憶”、“回憶”、“處理”能力,可以利用本書介紹的技術從歷史資料中學習到知識。
人類學習和機器學習之間的類比會讓人聯想到人工智慧(AI)這個術語。一個顯而易見的問題是,AI和機器學習的區別是什麼?對於這個問題,目前還沒有明確的共識,大多數的觀點是:ML是人工智慧的一種形式,人工智慧是涵蓋機器人、自然語言處理、計算機視覺等領域更廣泛的學科。目前,機器學習也被廣泛的應用於這些相近的人工智慧領域。也可以說,機器學習指的是一個特定的知識體和相關技術的組合。對於什麼是機器學習,什麼不是機器學習可以有很明確的判定,但是對於什麼是人工智慧就不能這樣理解,就像Tom Mitchell經常引用的定義所說:“人工智慧就是一組完成特定任務的計算機程式,並且會隨著經驗的增加而提高效能”。
就像Kaggle上的貓狗識別大賽,參賽者根據比賽方提供的12500張已知類別的圖片進行模型訓練,並用12500張無標籤資料對模型進行測試。
當我們像被人介紹kaggle的貓狗識別大賽的時候,人們通常會想到去尋找可能適用於區分貓狗的規則,比如貓的耳朵是三角形的,而且是豎起來的,而狗的耳朵則是耷拉的。但是,這些規則在很多情況下並不成立。試想一下,一個從未見過貓狗的人是如何辨別貓狗的?
人們可以使用包括形狀、顏色、紋理以及比例等特徵進行學習,並從例項中進行一定的推廣。機器學習亦是如此,利用各種規則策略的組合完成既定任務的學習。
這些策略可以由進幾十年來發展的統計學、電腦科學、機器人學以及相關演算法中體現,並廣泛的應用於線上搜尋、娛樂、數字廣告、語言翻譯等場景中。不同的策略各有特點,有的用於分類任務,而有的是用於預測一個數值,還有一些則是用於度量例項之間的異同(人,貓,狗,過程,機器等)。而這些策略(演算法)也就是從這些例項中學習到知識,並將學習到的知識用於未知的例項。
在貓狗識別大賽中,參賽者在模型訓練階段,嘗試各種演算法以提高模型的分類效能。演算法在迭代過程中不斷的執行分類計算,結果驗證,模型調整以不斷的提高模型的效能。大賽的獲勝者以測試資料分類準確98.914%的準確率高居榜首。考慮到人眼識別的誤差在7%左右,這個結果是相當不錯的。圖1.1為整個識別流程,通過對有標籤的資料進行分析,並利用機器學習方法構建模型,實現沒有標籤資料的預測。圖中有一隻貓是誤分類的。
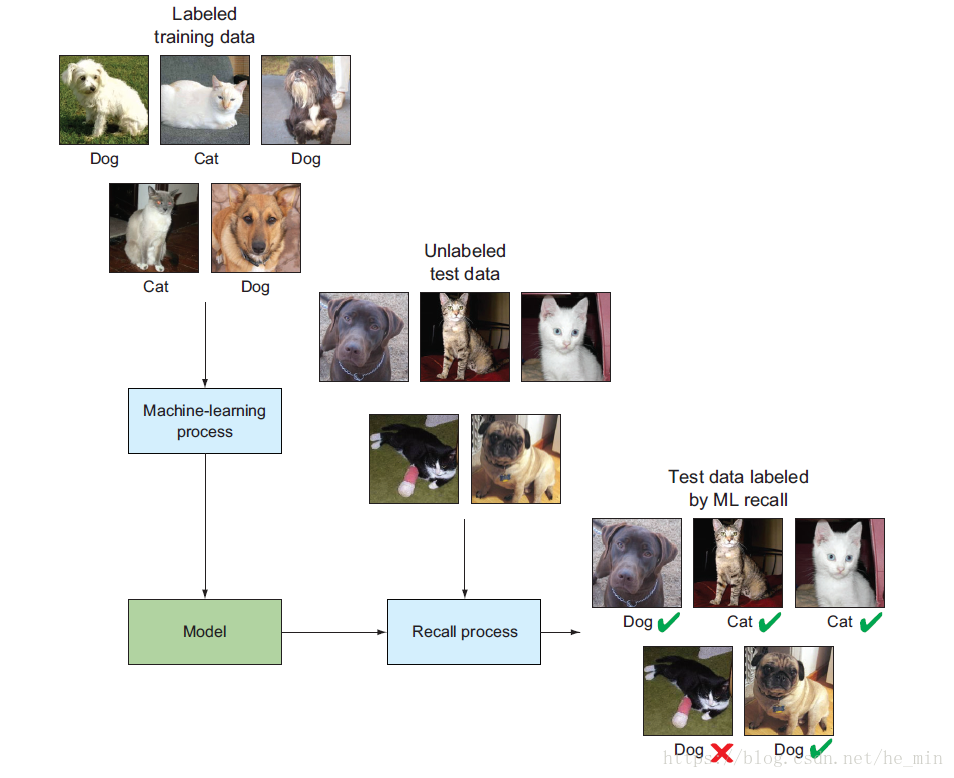
圖1-1 機器學習在貓狗識別中的流程
這裡需要注意的是,該流程僅為機器學習中的一種—監督學習,其他的方式將會在後續章節中進行介紹。
機器學習可以被廣泛的應用於商業領域,從欺詐檢測到客戶定位與個性化產品推薦,從實時工業檢測到情感分析與醫療診斷。機器學習可以處理那些因為資料量太大,人工無法合理分析的問題,當資料量很大的時候,機器學習會分析資料之間的關係,並將這些“弱”的關係組合起來形成強有力的預測因子。
從資料中學習知識,並將知識應用於未知資料上,是非常強大的,事實上,機器學習也正在迅速成為推動資料驅動經濟的引擎。
表1-1描述了廣泛應用於有監督機器學習的技術以及例項。
| 問題 | 描述 | 案例 |
|---|---|---|
| 分類 | 根據輸入資料確定每個樣本所屬的類別 | 垃圾郵件過濾、情感分析、欺詐檢測、客戶廣告定位、客戶流失預測、支援案例標記、內容個性化、製造缺陷檢測、客戶細分、事件發現、基因組學、藥物功效 |
| 迴歸 | 根據輸入資料對每個樣本進行連續值預測 | 股票預測,價格估計,需求預測,風險管理,天氣預報,體育預測 |
| 推薦 | 在候選內容中選擇更合適的 | 商品推薦,招聘,線上約會內容推薦 |
| 補值 | 對缺失值進行填補 | 病人病歷資料不完整,客戶資料缺失,人口資料普查 |
利用資料作出決策
如下例子是現實生活中真實的受益於機器學習的商業例子,並與其他方法進行對比以展示ML的優勢。
如果你負責一家小額信貸公司,想對一些社群中陷入困難但想創辦企業的人提供貸款,早期的時候,每週僅有幾個申請,你可以親自閱讀這些申請,並對每位申請者進行背景調查,以此來決定是否放貸。整個流程如圖1.2所示,你的客戶因為你的審理週期短,以及周到的服務感到滿意,公司的名譽遠播四方。
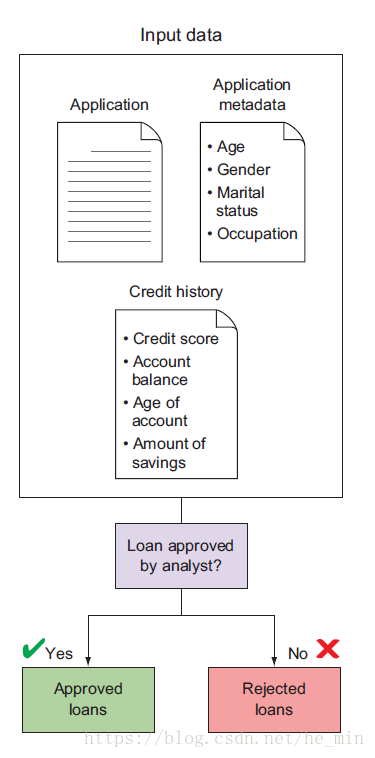
圖1-2 小額貸款審批流程
隨著公司聲譽的傳播,申請貸款的數量開始增加,你每週將會收到數百份申請書,你試圖通過加班來對這些申請進行稽核,但是申請書卻在不斷的積累,那些申請人厭倦了等待,並尋找競爭對手尋求貸款。很顯然,手動對每個申請進行處理並不是很好的可持續發展戰略。
那麼我們該怎麼辦呢?在下面的章節中,你將對一些可以促進業績的方法進行探索。
傳統方法
我們對兩種傳統稽核方法進行探討:(1)手工分析;(2)業務規則。對於每種方法,我們均介紹其實現過程,並對它無法實現業務的擴充套件進行闡述。
- 僱傭更多的分析師
你決定僱一個分析師幫你進行申請稽核,你不得不把部分利潤分給新員工。使用第二個人進行申請稽核,可以將你的稽核速度提升一倍,這樣你可以在一週內減少一定的積壓量。在前兩週,兩個人一起工作仍然不能滿足業務的增長,然而申請的數量依然在翻番的增長。為了趕上業務的增長速度,你不得不僱傭更多的人,試想一下未來,這種模式並不是可持續發展的。你從新的貸款申請者中獲取的利潤會直接分配給你的僱員,而不是信貸業務的發展。隨著業務需求的增長,僱傭更多的員工會阻礙你業務的增長,此外你還會發現,招聘分析師的過程成本高昂。而且隨著團隊的擴大,新員工在處理類似事件的經驗不比老員工,團隊管理的壓力也會變的更大。
處理增加成本這一明顯缺陷之外,人們在決策過程中也會有一定的偏見,為了確保決策的一致性,你可以製作審批處理流程,併為分析師提供培訓,然而不僅會增加成本且並不能完全消除偏見。
- 制定分析規則
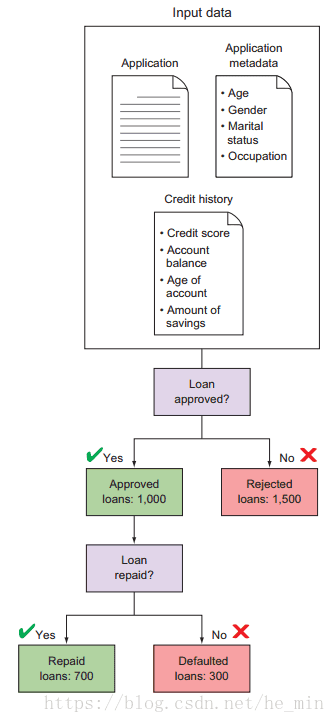
試想一下,1000個貸款已經逾期,僅有70%的貸款能及時的償還,由圖1-3所示:
圖1-3 幾個月後,有2500個貸款申請,其中1000個是批准的,其中700個可以按時還款,剩餘300個則逾期,這些觀測資訊對以後的自動化操作有至關重要的作用
目前你在尋找申請資料和貸款償還率之間的關係,實際上,你正在一大堆資料裡尋找一個過濾規則,從而找到那些可以及時償還的貸款。通過人工分析上百份的申請資訊,你可以獲得判別申請好壞的經驗,並通過自我反省與反饋測試,你在信貸背景下的資料中找到了一些規律。
- 信用額度超過$7500的申請者大多拖欠貸款
- 大多數不能及時還款的借款人沒有支票賬戶
現在你可以設計上述過濾機制來削掉不滿足上述規則的申請者。
你的第一條規則自動拒絕了很多信用額度超過$7500的申請者,通過觀測歷史資料,你發現,86個申請中有44個申請者的信用額度超過了 $7500 大約有51%具有高額信用額度的申請者逾期,28%歸還,這條規則看起來是條不錯的規則來排除一些高風險的申請者。但是,你意識到僅有8.6%(1000中的86個)的申請者具有如此高的額度,意味著你還得手動處理90%的申請,你需要做更多的過濾工作來使得你的工作量下降。
你的第二條規則自動的批准那些沒有支票的申請者,這看起來是條不錯的規則,但是在394個申請者中有348個沒有支票賬戶(88%)這兩條判斷規則。根據這兩條新制定的規則,可以自動的接受或者拒絕45%的申請,因此,你需要手工分析一半的申請資訊,圖1-4可以詳細的看出這兩條過濾規則。
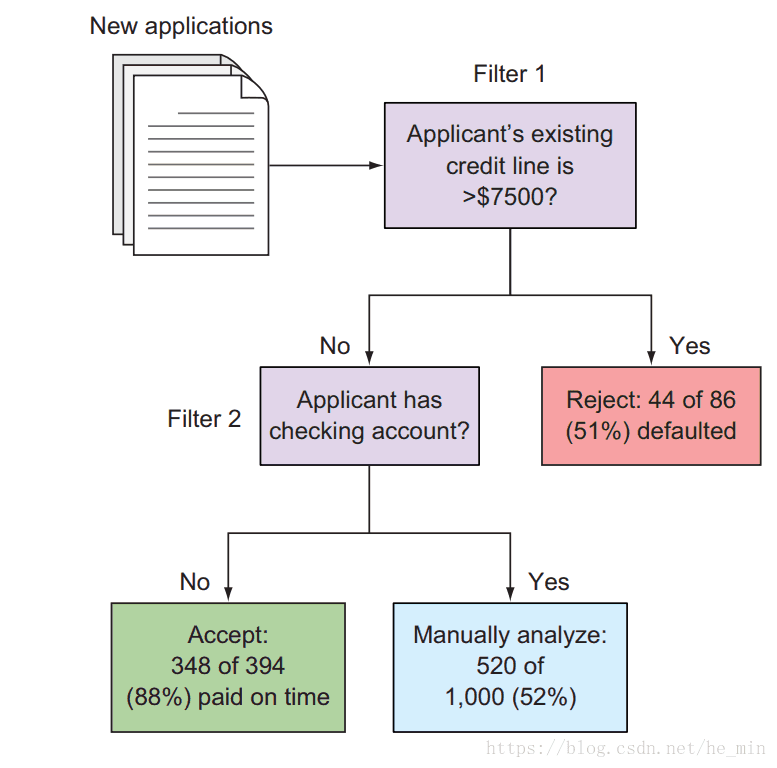
圖1-4 根據兩條規則,還有52%的申請資訊需要手工處理
根據這兩條規則,你不但不需要僱分析師,還可以將生意擴大兩倍,因為你僅需手工判斷52%的申請者。除此之外,在知道這1000人的結果之後,你期望你的過濾機制可以達到4.2%的假陰率和4.6的假陽率。
隨著業務的擴大,你期望你的系統可以在沒有增加錯誤率的前提下,自動的接受或者拒絕大量的申請。為此,你需要新增更多的規則。但是你很快發現了一些問題:
- 人工發現規則是越來越難,如果不是不可能,系統會越來越複雜
- 商業規則變得如此複雜和不透明,以至於除錯和分裂這些規則變得不現實
- 你構造的規則並沒有嚴格的統計,雖然你認為這些規則可以有效的,但是並不能得到有效的證明
- 隨著時間的改變,信貸模式可能發生改變,系統也需要隨著進行改變。
所有的這些缺點都可以歸結為虛弱的商業規則方法。
資料驅動模型,從簡單的統計學習模型到更復雜的機器學習工作流都可以克服上述的問題。