
GoogLeNet & Inception 系列
文章目錄
論文資訊
[v1] Going Deeper withConvolutions, 6.67% test error,2014.9
論文地址:http://arxiv.org/abs/1409.4842
[v2] Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error,2015.2
論文地址:http://arxiv.org/abs/1502.03167
[v3] Rethinking theInception Architecture for Computer Vision, 3.5%test error,2015.12
論文地址:http://arxiv.org/abs/1512.00567
[v4] Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error,2016.2
論文地址:http://arxiv.org/abs/1602.07261
提高深度神經網路效能,最直接的方式是增加它們的尺寸:
-
不僅包括增加深度:網路層次的數目
-
也包括增加它的寬度:每一層的單元數目。
但是這個簡單方案有兩個主要的缺點:
-
更大的尺寸通常意味著更多的引數,這會使增大的網路更容易過擬合,尤其是在訓練集的標註樣本有限的情況下。
-
另一個缺點是計算資源使用的顯著增加。例如,在一個深度視覺網路中,如果兩個卷積層相連,它們的濾波器數目的任何均勻增加都會引起計算量平方式的增加。如果增加的能力使用時效率低下(例如,如果大多數權重結束時接近於0),那麼會浪費大量的計算能力。
解決這兩個問題的一個基本的方式就是引入稀疏性並將全連線層替換為稀疏的全連線層,甚至是卷積層。遺憾的是,切換到稀疏矩陣並不可行。當碰到在非均勻的稀疏資料結構上進行數值計算時,現在的計算架構效率非常低下。即使演算法運算的數量減少100倍,查詢和快取丟失上的開銷仍占主導地位。
Inception架構,嘗試利用濾波器水平的稀疏性,通過密集矩陣計算來提高硬體計算效率。
Inception 架構細節
Inception 架構,使用不同尺寸的卷積核,在同一層提取不同的特徵:
-
一個 block 就包含 卷積, 卷積, 卷積, 池化。 使用這樣的尺寸不是必需的,可以根據需要進行調整。
-
這樣,網路中每一層都能學習到“稀疏”( 、 )或“不稀疏”( )的特徵,既增加了網路的寬度,也增加了網路對尺度的適應性。
-
通過deep concat 合成 block 的特徵集合,獲得非線性屬性。
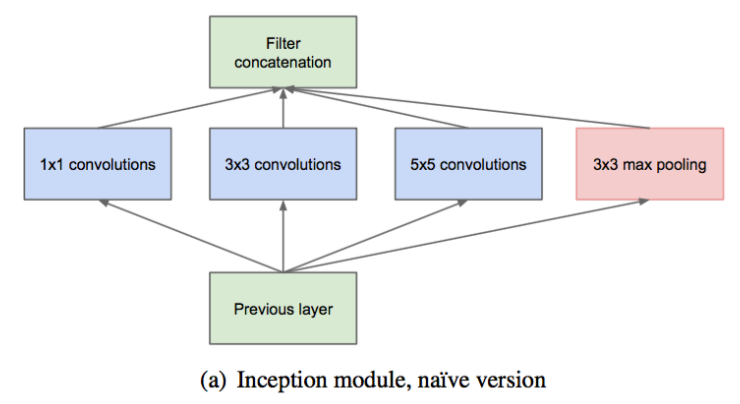
在具有大量濾波器的卷積層之上,即使適量的 卷積也可能是非常昂貴的。池化層輸出和卷積層輸出的合併,會導致輸出數量不可避免的增加。雖然這種架構可能會覆蓋最優稀疏結構,但它會非常低效,導致在幾個階段內計算量爆炸。
這導致了Inception架構的第二個想法:在昂貴的 和 卷積之前,用 卷積,在降維的同時,增加了ReLU(線性修正)單元。改進後的結構圖如下:

通常,Inception網路是一個由上述型別的模組互相堆疊組成的網路,偶爾會有步長為2的最大池化層將網路解析度減半。
GoogLeNet 網路結構 (Inception-v1)
GoogLeNet 網路層次結構:檢視
-
所有的卷積都使用了ReLU(修正線性啟用),包括Inception模組內部的卷積,網路有22個引數層。
-
作者將全連線層變為平均池化,提高了 top-1 大約 的準確率。即使移除了全連線層, 的使用仍是必須的。
-
作者通過在中間層中新增輔助分類器,在提供正則化的同時克服梯度消失問題。在訓練期間,它們的損失以 的權重比例,加到網路的整個損失上。在預測時,不使用輔助分類器。作者後面的控制實驗表明,輔助網路的影響相對較小(約 ),只需要其中一個就能取得同樣的效果。
包括輔助分類器在內的附加網路的具體結構如下:
-
一個濾波器大小為 ,步長為 的平均池化層。
-
具有128個濾波器的 卷積,用於降維和修正線性啟用。
-
一個全連線層,具有 個單元和修正線性啟用。
-
丟棄70%輸出的丟棄層。
-
使用帶有 softmax 損失的線性層作為分類器(作為主分類器預測同樣的1000類,但在預測時移除)。

GoogLeNet 與 VGG 對比
VGG 繼承了 LeNet 以及 AlexNet 的一些框架結構,而 GoogLeNet 則做了更加大膽的網路結構嘗試,雖然深度只有 層,但大小卻比 AlexNet 和 VGG 小很多:
-
GoogLeNet 引數為 萬個
-
AlexNet 引數個數是 GoogLeNet 的 倍
-
VGG 引數又是 AlexNet 的 倍
因此在記憶體或計算資源有限時,GoogLeNet 是比較好的選擇;從模型結果來看,GoogLeNet 的效能卻更加優越。
但 GoogLeNet 也有自身的問題:
-
GoogLeNet 為了防止梯度消失,在前面的層增加了兩個損失函式,softmax0 和 softmax1,正是這兩個損失函式導致了 GoogLeNet 的可拓展性沒有 VGG 那麼強
-
Inception 架構的複雜性使得更難以對網路進行更改。如果單純地放大架構,大部分的計算收益可能會立即丟失。
但是即便如此,GoogLeNet 在分類領域還是非常好用的。
Inception-v2
Inception-v2 的結構,在 v1 的基礎之上主要做了以下改進:
-
輸入從 變為 。
-
使用 BN 層 (Batch-normalized),將每一層的輸出都規範化到一個 的正態分佈,這將有助於訓練,因為下一層不必學習輸入資料中的偏移,可以專注與如何更好地組合特徵。
BN 層在 Inception-v2 中的優化效果,使其幾乎成為深度網路的必備
-
使用 個 的卷積代替 的卷積,這樣既可以獲得相同的視野,在減少引數量的同時,還間接增加了網路的深度。網路結構如下:
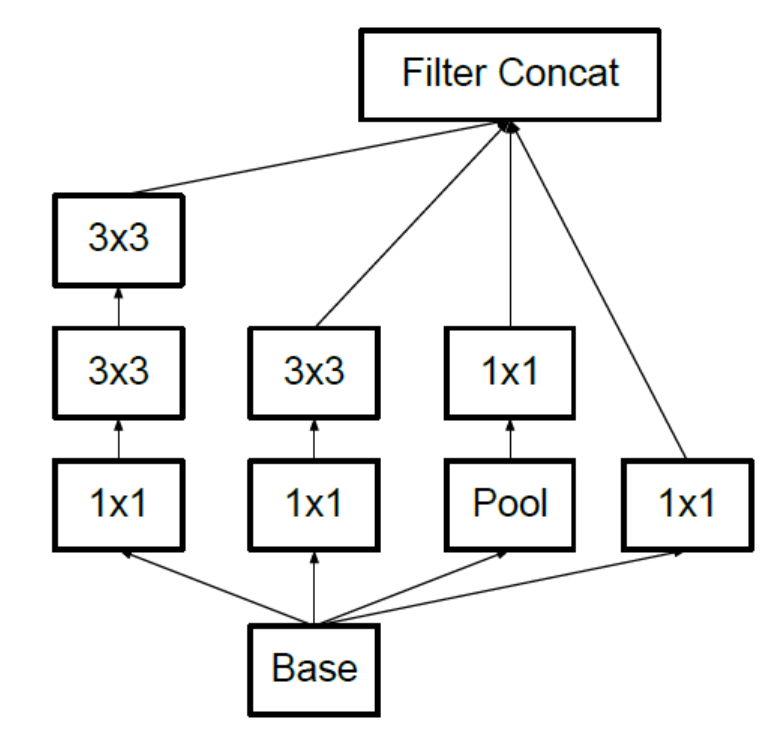
-
在理論上,可以通過非對稱卷積( 卷積,後面接一個 卷積)來替換任何 的對稱卷積。
-
在特徵圖大小為12~20的中間層,通過使用 卷積,後接 卷積可以獲得非常好的結果。網路結構如下:

- 在特徵圖大小為 的高維特徵上,可以增加多維濾波器輸出,以此來產生高維的稀疏特徵:

在 Imagenet 資料集上,Inception-v2 與 Inception-v1 相比,分類錯誤率由29%降為23.4%。
Inception-v3
Inception 模組之間特徵圖的縮小,主要有下面兩種方式:
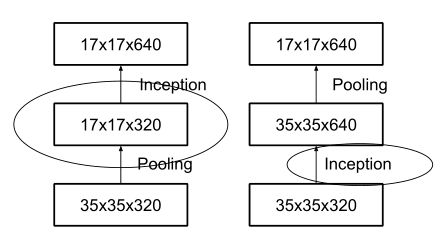
-
Inception-v2 採用左圖的方式,即在不同的 Inception 塊之間(35/17/8的特徵圖大小)先用Pooling進行下采樣,再進行 Inception 操作。
這種操作會造成表達瓶頸問題,也就是說特徵圖的大小不應該出現急劇的衰減(只經過一層就驟降)。如果出現急劇縮減,將會丟失大量的資訊,對模型的訓練造成困難。
-
右圖是先進行 Inception 操作,再進行 Pooling 下采樣,但是這樣引數量明顯多於左圖。
-
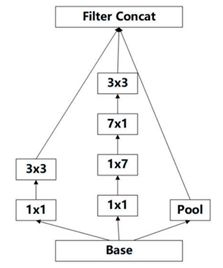
因此,Inception-v3 採用一種並行的降維結構。35/17 之間的特徵圖尺寸減小方式:

- 17/8 之間的特徵圖尺寸縮小方式:
Inception-v3 微調
Inception-v3 權重檔案下載: 地址
Inception-v3 微調:
import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
# 資料引數
MODEL_DIR = 'inception_dec_2015/' # inception-v3模型的資料夾
MODEL_FILE = 'tensorflow_inception_graph.pb' # inception-v3模型檔名
CACHE_DIR = 'tmp/bottleneck' # 影象的特徵向量儲存地址
INPUT_DATA = './citySpace/outData/train' # 圖片資料資料夾
VALIDATION_PERCENTAGE = 10 # 驗證資料的百分比
TEST_PERCENTAGE = 10 # 測試資料的百分比
# inception-v3模型引數
BOTTLENECK_TENSOR_SIZE = 2048 # inception-v3模型瓶頸層的節點個數
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0' # inception-v3模型中代表瓶頸層結果的張量名稱
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0' # 影象輸入張量對應的名稱
# 神經網路的訓練引數
LEARNING_RATE = 0.01
STEPS = 1000
BATCH = 100
CHECKPOINT_EVERY = 100
NUM_CHECKPOINTS = 5
# 從資料資料夾中讀取所有的圖片列表並按訓練、驗證、測試分開
def create_image_lists(validation_percentage, test_percentage):
result = {} # 儲存所有影象。key為類別名稱。value也是字典,儲存了所有的圖片名稱
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)] # 獲取所有子目錄
is_root_dir = True # 第一個目錄為當前目錄,需要忽略
# 分別對每個子目錄進行操作
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
# 獲取當前目錄下的所有有效圖片
extensions = {'PNG', 'png'}
file_list = [] # 儲存所有影象
dir_name = os.path.basename(sub_dir) # 獲取路徑的最後一個目錄名字
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension)
file_list.extend(glob.glob(file_glob))
if not file_list:
continue
# 將當前類別的圖片隨機分為訓練資料集、測試資料集、驗證資料集
label_name = dir_name.lower() # 通過目錄名獲取類別的名稱
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name) # 獲取該圖片的名稱
chance = np.random.randint(100) # 隨機產生100個數代表百分比
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (validation_percentage + test_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
# 將當前類別的資料集放入結果字典
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images
}
# 返回整理好的所有資料
return result
# 通過類別名稱、所屬資料集、圖片編號獲取一張圖片的地址
def get_image_path(image_lists, image_dir, label_name, index, category):
label_lists = image_lists[label_name] # 獲取給定類別中的所有圖片
category_list = label_lists[category] # 根據所屬資料集的名稱獲取該集合中的全部圖片
mod_index = index % len(category_list) # 規範圖片的索引
base_name = category_list[mod_index] # 獲取圖片的檔名
sub_dir = label_lists['dir'] # 獲取當前類別的目錄名
full_path = os.path.join(image_dir, sub_dir, base_name) # 圖片的絕對路徑
return full_path
# 通過類別名稱、所屬資料集、圖片編號獲取特徵向量值的地址
def get_bottleneck_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index,
category) + '.txt'
# 使用inception-v3處理圖片獲取特徵向量
def run_bottleneck_on_image(sess, image_data, image_data_tensor,
bottleneck_tensor):
bottleneck_values = sess.run(bottleneck_tensor,
{image_data_tensor: image_data})
bottleneck_values = np.squeeze(bottleneck_values) # 將四維陣列壓縮成一維陣列
return bottleneck_values
# 獲取一張圖片經過inception-v3模型處理後的特徵向量
def get_or_create_bottleneck(sess, image_lists, label_name, index, category,
jpeg_data_tensor, bottleneck_tensor):
# 獲取一張圖片對應的特徵向量檔案的路徑
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir)
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
bottleneck_path = get_bottleneck_path(image_lists, label_name, index,
category)
# 如果該特徵向量檔案不存在,則通過inception-v3模型計算並儲存
if not os.path.exists(bottleneck_path):
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index,
category) # 獲取圖片原始路徑
image_data = gfile.FastGFile(image_path, 'rb').read() # 獲取圖片內容
bottleneck_values = run_bottleneck_on_image(
sess, image_data, jpeg_data_tensor,
bottleneck_tensor) # 通過inception-v3計算特徵向量
# 將特徵向量存入檔案
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# 否則直接從檔案中獲取圖片的特徵向量
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
# 返回得到的特徵向量
return bottleneck_values
# 隨機獲取一個batch圖片作為訓練資料
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many,
category, jpeg_data_tensor,
bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
# 隨機一個類別和圖片編號加入當前的訓練資料
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65535)
bottleneck = get_or_create_bottleneck(
sess, image_lists, label_name, image_index, category,
jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
# 獲取全部的測試資料
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor,
bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys())
# 列舉所有的類別和每個類別中的測試圖片
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
for index, unused_base_name
相關推薦
GoogLeNet & Inception 系列
文章目錄
論文資訊
Inception 架構動機
Inception 架構細節
GoogLeNet 網路結構 (Inception-v1)
GoogLeNet 與 VGG 對比
Inception-v2
Ince
解讀ASP.NET 5 & MVC6 ---- 系列文章
vcop fig out omx conf htm ati 特性 clas
本系列的大部分內容來自於微軟源碼的閱讀和網絡,大部分測試代碼都是基於VS RC版本進行測試的。
解讀ASP.NET 5 & MVC6系列(1):ASP.NET 5簡介
解讀ASP.N
深度解讀GoogleNet之Inception V1
能力 翻轉 浪費 對齊 並行運算 bubuko AD 好的 減少 GoogleNet設計的目的
GoogleNet設計的初衷是為了提高在網絡裏面的計算資源的利用率。
Motivation
網絡越大,意味著網絡的參數較多,尤其當數據集很小的時候,網絡更容易發生過擬合。網絡越大
Inception 系列學習小記
參考很多,僅為個人學習記錄使用
Inception 系列網路是 Google 提出的網路結構
InceptionV1(GoogLeNet)發表於 2014 年並獲得了 ILSVRC 2014 的冠軍;test error: 6.67%
InceptionV2,提出了
網路結構解讀之inception系列四:Inception V3
Inception V3根據前面兩篇結構的經驗和新設計的結構的實驗,總結了一套可借鑑的網路結構設計的原則。理解這些原則的背後隱藏的動機比單純知道這個操作更有意義。
Rethinking the Inception Architecture for Computer Vision
主題:如何
網路結構解讀之inception系列五:Inception V4
在殘差逐漸當道時,google開始研究inception和殘差網路的效能差異以及結合的可能性,並且給出了實驗結構。
本文思想闡述不多,主要是三個結構的網路和實驗效能對比。
Inception-v4, Inception-ResNet and
the Impact of Residual
GoogLeNet 之 Inception v1 v2 v3 v4
論文地址
Inception V1 :Going Deeper with Convolutions
Inception-v2 :Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate
I
Inception系列和ResNet的成長之路
小總結一下Inception v1——Inception v4的發展歷程
1.Inception V1
通過設計一個係數網路結構,但是能夠產生稠密的資料,既能增加神經網路的表現,又能保證計算資源的使用效率。
通過Split-Merge包含了1 * 1,3 * 3,5 * 5的
Inception系列解讀
Inception-v1
思想: 加寬;多種不同卷積都用上
Inception module 的提出主要考慮多個不同 size 的卷積核能夠增強網路的適應力,paper 中分別使用1*1、3*3、5*5卷積核,同時加入3*3 max pooling。
每一層 Inception
Deep Learning-TensorFlow (13) CNN卷積神經網路_ GoogLeNet 之 Inception(V1-V4)
環境:Win8.1 TensorFlow1.0.1
軟體:Anaconda3 (整合Python3及開發環境)
TensorFlow安裝:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
GoogLeNet 之 Inception-v1 解讀
本篇部落格的目的是展示 GoogLeNet 的 Inception-v1 中的結構,順便溫習裡面涉及的思想。
1 版本主要思想詳述
1.1 Inception v1
Inception V1 在ILSVRC 2014的比賽中,以較大優勢取得了第一名,
影象分類丨Inception家族進化史「GoogleNet、Inception、Xception」
引言
Google提出的Inception系列是分類任務中的代表性工作,不同於VGG簡單地堆疊卷積層,Inception重視網路的拓撲結構。本文關注Inception系列方法的演變,並加入了Xception作為對比。
PS1:這裡有一篇blog,作者Bharath Raj簡潔明瞭地介紹這系列的工作:htt
Inception系列理解
部落格:[部落格園](https://www.cnblogs.com/shine-lee/) | [CSDN](https://blog.csdn.net/blogshinelee) | [blog](https://blog.shinelee.me/)
[TOC]
# 寫在前面
Inception 家
Docker & Kubenetes 系列四:叢集,擴容,升級,回滾
> 本篇將會講解應用部署到Kubenetes叢集,叢集副本集檢視,叢集自愈能力演示,叢集擴容,滾動升級,以及回滾。
本篇是Docker&Kubenetes系列的第四篇,在前面的篇幅中,我們向Kubenetes中部署了單個應用例項。如果單個節點故障了,那麼服務就不可用了,這在實際環境中是不能接受的。在實際的正
【深度學習】GoogLeNet系列解讀 —— Inception v4
目錄
GoogLeNet系列解讀
Inception v1
Inception v2
Inception v3
Inception v4
簡介
在介紹Inception v4之前,首先說明一下Inception v4沒有使用殘差學習的思想。大部分小夥伴對Inc
【深度學習】GoogLeNet系列解讀 —— Inception v3
目錄
GoogLeNet系列解讀
Inception v1
Inception v2
Inception v3
Inception v4
Inception v3
Inception v3整體上採用了Inception v2的網路結構,並在優化演算法、正則化等
【深度學習】GoogLeNet系列解讀 —— Inception v2
目錄
GoogLeNet系列解讀
Inception v1
Inception v2
Inception v3
Inception v4
簡介
GoogLeNet憑藉其優秀的表現,得到了很多研究人員的學習和使用,因此Google又對其進行了改進,產生了Goog
實戰c++中的vector系列--對vector&lt;自己定義類&gt;使用std::find 和 std::find_if 算法
++ pac price key fadein 輸出 var getitem mod
之前博客講了一些關於std::find和std::find_ if的一些使用方法。可是沒有講述對於vector中存儲的是自己定義的類。那麽怎麽樣使用std::find和
實戰c++中的vector系列--vector&lt;unique_ptr&lt;&gt;&gt;初始化(全部權轉移)
down pop namespace tor each ring space spa hid
C++11為我們提供了智能指針,給我們帶來了非常多便利的地方。
那麽假設把unique_ptr作為vector容器的元素呢?
形式如出一轍:vector&l
UWP 手繪視頻創作工具技術分享系列 - Ink & Surface Dial
而且 技術 -i 作者 執行 不難 存在 顏色加深 修改 本篇作為技術分享系列的第四篇,詳細講一下手繪視頻中 Surface Pen 和 Surface Dial 的使用場景。
先放一張微軟官方商城的圖,Surface 的使用中結合了 Surface Pen 和 Surf