
GoogLeNet 之 Inception v1 v2 v3 v4
論文地址
Inception V1 :Going Deeper with Convolutions
Inception-v2 :Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate
Inception-v3 :Rethinking the Inception Architecture for Computer Vision
Inception-v4 :Inception-ResNet and the Impact of Residual Connections on Learning
GitHub原始碼
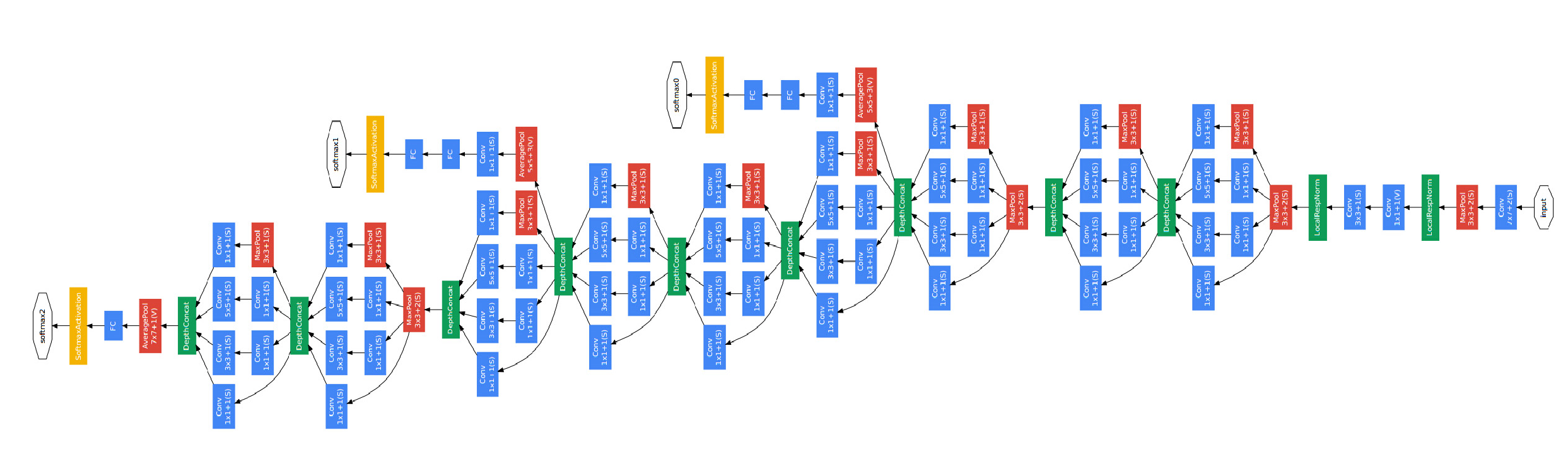

最原始的Google-net結構圖
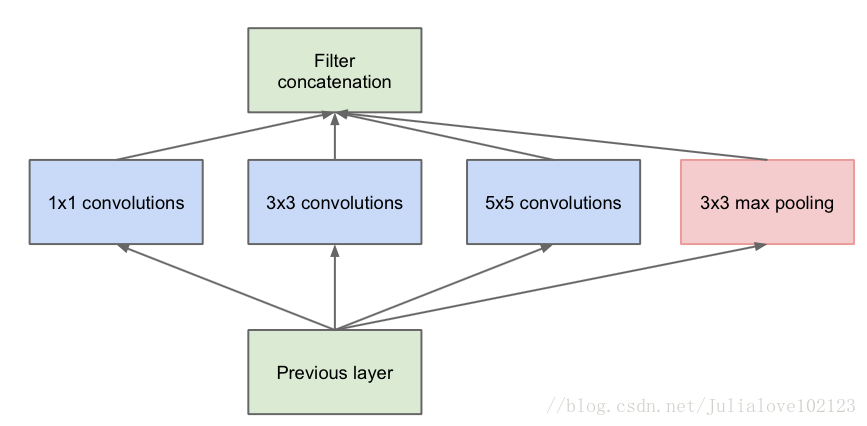
Inception V1
上圖是論文中提出的最原始的版本,所有的卷積核都在上一層的所有輸出上來做,那5×5的卷積核所需的計算量就太大了,造成了特徵圖厚度很大。為了避免這一現象提出的inception具有如下結構,在3x3前,5x5前,max pooling後分別加上了1x1的卷積核起到了降低特徵圖厚度的作用,也就是Inception v1的網路結構。
Google Inception Net首次出現在ILSVRC 2014的比賽中(和VGGNet同年),就以較大優勢取得了第一名。那屆比賽中的Inception Net通常被稱為Inception V1.
它最大的特點是控制了計算量和引數量的同時,獲得了非常好的分類效能——top-5錯誤率6.67%,只有AlexNet的一半不到。Inception V1有22層深,比AlexNet的8層或者VGGNet的19層還要更深。但其計算量只有15億次浮點運算,同時只有500萬的引數量,僅為AlexNet引數量(6000萬)的1/12,卻可以達到遠勝於AlexNet的準確率,可以說是非常優秀並且非常實用的模型。
Inception V1降低引數量的目的有兩點:
第一,引數越多模型越龐大,需要供模型學習的資料量就越大,而目前高質量的資料非常昂貴;
第二,引數越多,耗費的計算資源也會更大。
Inception V1引數少但效果好的原因除了模型層數更深、表達能力更強外,還有兩點:
一、用全域性平均池化層(即將圖片尺寸變為1´1)來取代最後的全連線層。全連線層幾乎佔據了AlexNet或VGGNet中90%的引數量,而且會引起過擬合,去除全連線層後模型訓練更快並且減輕了過擬合。用全域性平均池化層取代全連線層的做法借鑑了Network In Network(以下簡稱NIN)論文。
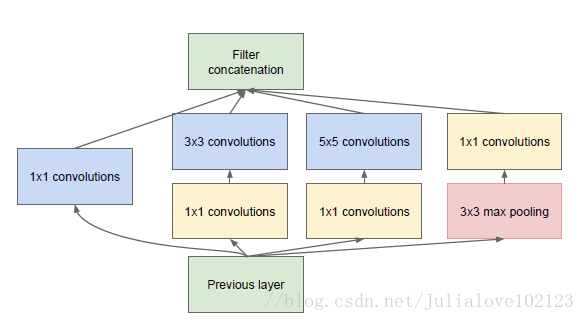
二、Inception V1中精心設計的Inception Module提高了引數的利用效率,其結構如圖1所示。這一部分也借鑑了NIN的思想,形象的解釋就是Inception Module本身如同大網路中的一個小網路,其結構可以反覆堆疊在一起形成大網路。不過Inception V1比NIN更進一步的是增加了分支網路,NIN則主要是級聯的卷積層和MLPConv層。一般來說卷積層要提升表達能力,主要依靠增加輸出通道數,但副作用是計算量增大和過擬合。每一個輸出通道對應一個濾波器,同一個濾波器共享引數,只能提取一類特徵,因此一個輸出通道只能做一種特徵處理。而NIN中的MLPConv則擁有更強大的能力,允許在輸出通道之間組合資訊,因此效果明顯。可以說,MLPConv基本等效於普通卷積層後再連線1´1的卷積和ReLU啟用函式。
Inception Module的基本結構有4個分支:
第一個分支對輸入進行1´1的卷積,這其實也是NIN中提出的一個重要結構。1´1的卷積是一個非常優秀的結構,它可以跨通道組織資訊,提高網路的表達能力,同時可以對輸出通道升維和降維。可以看到Inception Module的4個分支都用到了1´1卷積,來進行低成本(計算量比3´3小很多)的跨通道的特徵變換。
第二個分支先使用了1´1卷積,然後連線3´3卷積,相當於進行了兩次特徵變換。
第三個分支先是1´1的卷積,然後連線5´5卷積。
第四個分支則是3´3最大池化後直接使用1´1卷積。我們可以發現,有的分支只使用1´1卷積,有的分支使用了其他尺寸的卷積時也會再使用1´1卷積,這是因為1´1卷積的價效比很高,用很小的計算量就能增加一層特徵變換和非線性化。Inception Module的4個分支在最後通過一個聚合操作合併(在輸出通道數這個維度上聚合)。Inception Module中包含了3種不同尺寸的卷積和1個最大池化,增加了網路對不同尺度的適應性,這一部分和Multi-Scale的思想類似。早期計算機視覺的研究中,受靈長類神經視覺系統的啟發,Serre使用不同尺寸的Gabor濾波器處理不同尺寸的圖片,Inception V1借鑑了這種思想。Inception V1的論文中指出,Inception Module可以讓網路的深度和寬度高效率地擴充,提升準確率且不致於過擬合。
Inception Module結構圖
人腦神經元的連線是稀疏的,因此研究者認為大型神經網路的合理的連線方式應該也是稀疏的。稀疏結構是非常適合神經網路的一種結構,尤其是對非常大型、非常深的神經網路,可以減輕過擬合併降低計算量,例如卷積神經網路就是稀疏的連線。Inception Net的主要目標就是找到最優的稀疏結構單元(即Inception Module),論文中提到其稀疏結構基於Hebbian原理。
這裡簡單解釋一下Hebbian原理:
神經反射活動的持續與重複會導致神經元連線穩定性的持久提升,當兩個神經元細胞A和B距離很近,並且A參與了對B重複、持續的興奮,那麼某些代謝變化會導致A將作為能使B興奮的細胞。總結一下即“一起發射的神經元會連在一起”(Cells that fire together, wire together),學習過程中的刺激會使神經元間的突觸強度增加。
受Hebbian原理啟發,另一篇文章Provable Bounds for Learning Some Deep Representations提出,如果資料集的概率分佈可以被一個很大很稀疏的神經網路所表達,那麼構築這個網路的最佳方法是逐層構築網路:將上一層高度相關(correlated)的節點聚類,並將聚類出來的每一個小簇(cluster)連線到一起,如圖11所示。這個相關性高的節點應該被連線在一起的結論,即是從神經網路的角度對Hebbian原理有效性的證明。
將高度相關的節點連線在一起,形成稀疏網路 如下圖: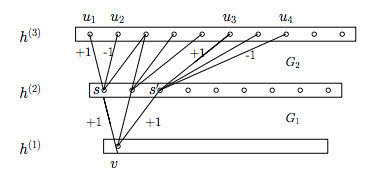
因此一個“好”的稀疏結構,應該是符合Hebbian原理的,我們應該把相關性高的一簇神經元節點連線在一起。在普通的資料集中,這可能需要對神經元節點聚類,但是在圖片資料中,天然的就是臨近區域的資料相關性高,因此相鄰的畫素點被卷積操作連線在一起。而我們可能有多個卷積核,在同一空間位置但在不同通道的卷積核的輸出結果相關性極高。因此,一個1´1的卷積就可以很自然地把這些相關性很高的、在同一個空間位置但是不同通道的特徵連線在一起,這就是為什麼1´1卷積這麼頻繁地被應用到Inception Net中的原因。1´1卷積所連線的節點的相關性是最高的,而稍微大一點尺寸的卷積,比如3´3、5´5的卷積所連線的節點相關性也很高,因此也可以適當地使用一些大尺寸的卷積,增加多樣性(diversity)。最後Inception Module通過4個分支中不同尺寸的1´1、3´3、5´5等小型卷積將相關性很高的節點連線在一起,就完成了其設計初衷,構建出了很高效的符合Hebbian原理的稀疏結構。
在Inception Module中,通常1´1卷積的比例(輸出通道數佔比)最高,3´3卷積和5´5卷積稍低。而在整個網路中,會有多個堆疊的Inception Module,我們希望靠後的Inception Module可以捕捉更高階的抽象特徵,因此靠後的Inception Module的卷積的空間集中度應該逐漸降低,這樣可以捕獲更大面積的特徵。因此,越靠後的Inception Module中,3´3和5´5這兩個大面積的卷積核的佔比(輸出通道數)應該更多。
Inception Net有22層深,除了最後一層的輸出,其中間節點的分類效果也很好。因此在Inception Net中,還使用到了輔助分類節點(auxiliary classifiers),即將中間某一層的輸出用作分類,並按一個較小的權重(0.3)加到最終分類結果中。這樣相當於做了模型融合,同時給網路增加了反向傳播的梯度訊號,也提供了額外的正則化,對於整個Inception Net的訓練很有裨益。
當年的Inception V1還是跑在TensorFlow的前輩DistBelief上的,並且只執行在CPU上。當時使用了非同步的SGD訓練,學習速率每迭代8個epoch降低4%。同時,Inception V1也使用了Multi-Scale、Multi-Crop等資料增強方法,並在不同的取樣資料上訓練了7個模型進行融合,得到了最後的ILSVRC 2014的比賽成績——top-5錯誤率6.67%。
Inception V2:
加入了BN層,減少了Internal Covariate Shift(內部neuron的資料分佈發生變化),使每一層的輸出都規範化到一個N(0, 1)的高斯; 學習VGG用2個3x3的conv替代inception模組中的5x5,既降低了引數數量,也加速計算;使用3×3的已經很小了,那麼更小的2×2呢?2×2雖然能使得引數進一步降低,但是不如另一種方式更加有效,那就是Asymmetric方式,即使用1×3和3×1兩種來代替3×3的卷積核。這種結構在前幾層效果不太好,但對特徵圖大小為12~20的中間層效果明顯。
Christian 和他的團隊都是非常高產的研究人員。2015 年 2 月,Batch-normalized Inception 被引入作為 Inception V2。
Batch-normalization 在一層的輸出上計算所有特徵對映的均值和標準差,並且使用這些值規範化它們的響應。這相當於資料「增白(whitening)」,因此使得所有神經圖(neural maps)在同樣範圍有響應,而且是零均值。在下一層不需要從輸入資料中學習 offset 時,這有助於訓練,還能重點關注如何最好的結合這些特徵。
Inception V2學習了VGGNet,用兩個3´3的卷積代替5´5的大卷積(用以降低引數量並減輕過擬合),還提出了著名的Batch Normalization(以下簡稱BN)方法。BN是一個非常有效的正則化方法,可以讓大型卷積網路的訓練速度加快很多倍,同時收斂後的分類準確率也可以得到大幅提高。BN在用於神經網路某層時,會對每一個mini-batch資料的內部進行標準化(normalization)處理,使輸出規範化到N(0,1)的正態分佈,減少了Internal Covariate Shift(內部神經元分佈的改變)。
BN的論文指出,傳統的深度神經網路在訓練時,每一層的輸入的分佈都在變化,導致訓練變得困難,我們只能使用一個很小的學習速率解決這個問題。而對每一層使用BN之後,我們就可以有效地解決這個問題,學習速率可以增大很多倍,達到之前的準確率所需要的迭代次數只有1/14,訓練時間大大縮短。而達到之前的準確率後,可以繼續訓練,並最終取得遠超於Inception V1模型的效能——top-5錯誤率4.8%,已經優於人眼水平。因為BN某種意義上還起到了正則化的作用,所以可以減少或者取消Dropout,簡化網路結構。
當然,只是單純地使用BN獲得的增益還不明顯,還需要一些相應的調整:增大學習速率並加快學習衰減速度以適用BN規範化後的資料;去除Dropout並減輕L2正則(因BN已起到正則化的作用);去除LRN;更徹底地對訓練樣本進行shuffle;減少資料增強過程中對資料的光學畸變(因為BN訓練更快,每個樣本被訓練的次數更少,因此更真實的樣本對訓練更有幫助)。在使用了這些措施後,Inception V2在訓練達到Inception V1的準確率時快了14倍,並且模型在收斂時的準確率上限更高。
Inception-V3:
v3一個最重要的改進是分解(Factorization),將7x7分解成兩個一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),這樣的好處,既可以加速計算(多餘的計算能力可以用來加深網路),又可以將1個conv拆成2個conv,使得網路深度進一步增加,增加了網路的非線性,還有值得注意的地方是網路輸入從224x224變為了299x299,更加精細設計了35x35/17x17/8x8的模組。
2015 年 12 月,該團隊釋出 Inception 模組和類似架構的一個新版本V3。該論文更好地解釋了原始的 GoogLeNet 架構,在設計選擇上給出了更多的細節。原始思路如下:
通過謹慎建築網路,平衡深度與寬度,從而最大化進入網路的資訊流。在每次池化之前,增加特徵對映。
當深度增加時,網路層的深度或者特徵的數量也系統性的增加。
使用每一層深度增加在下一層之前增加特徵的結合。
而Inception V3網路則主要有兩方面的改造:
一、引入了Factorization into small convolutions的思想,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將7´7卷積拆成1´7卷積和7´1卷積,或者將3´3卷積拆成1´3卷積和3´1卷積,如圖2所示。
一方面節約了大量引數,加速運算並減輕了過擬合(比將7´7卷積拆成1´7卷積和7´1卷積,比拆成3個3´3卷積更節約引數),
一方面增加了一層非線性擴充套件模型表達能力。論文中指出,這種非對稱的卷積結構拆分,其結果比對稱地拆為幾個相同的小卷積核效果更明顯,可以處理更多、更豐富的空間特徵,增加特徵多樣性。
將一個3´3卷積拆成1´3卷積和3´1卷積 如下圖:
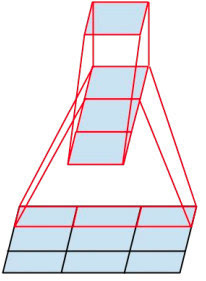
只使用 3×3 的卷積,可能的情況下給定的 5×5 和 7×7 過濾器能分成多個 3×3。
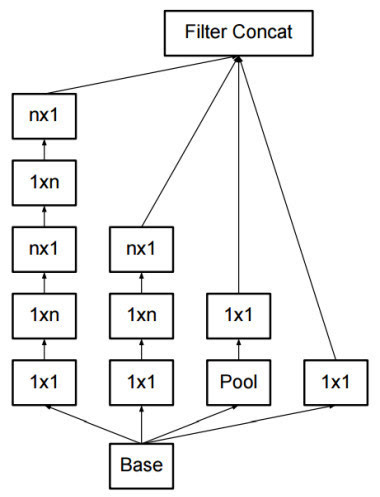
二、Inception V3優化了Inception Module的結構,現在Inception Module有35´35、17´17和8´8三種不同結構,如圖3所示。這些Inception Module只在網路的後部出現,前部還是普通的卷積層。並且Inception V3除了在Inception Module中使用分支,還在分支中使用了分支(8´8的結構中),可以說是Network In Network In Network。
Inception V3中三種結構的Inception Module圖
在進行 inception 計算的同時,Inception 模組也能通過提供池化降低資料的大小。這基本類似於在執行一個卷積的時候並行一個簡單的池化層:

Inception 也使用一個池化層和 softmax 作為最後的分類器。
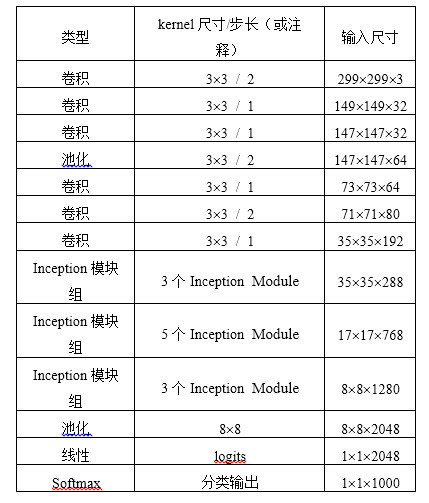
Inception V3網路結構
Inception V4:
v4研究了Inception模組結合Residual Connection能不能有改進?發現ResNet的結構可以極大地加速訓練,同時效能也有提升,得到一個Inception-ResNet v2網路,同時還設計了一個更深更優化的Inception v4模型,能達到與Inception-ResNet v2相媲美的效能。
Inception V4相比V3主要是結合了微軟的ResNet.
inception v4 網路結構圖
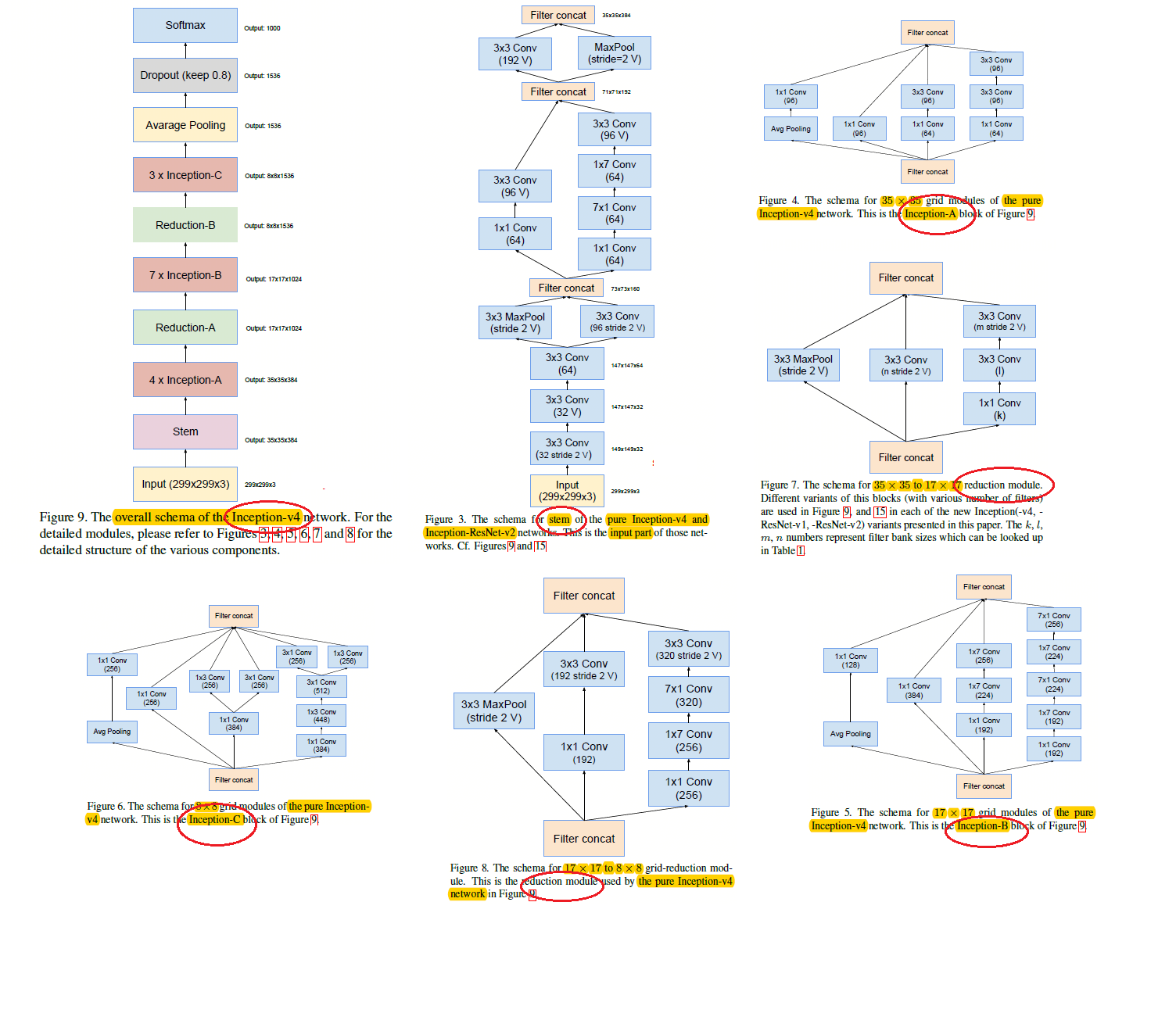
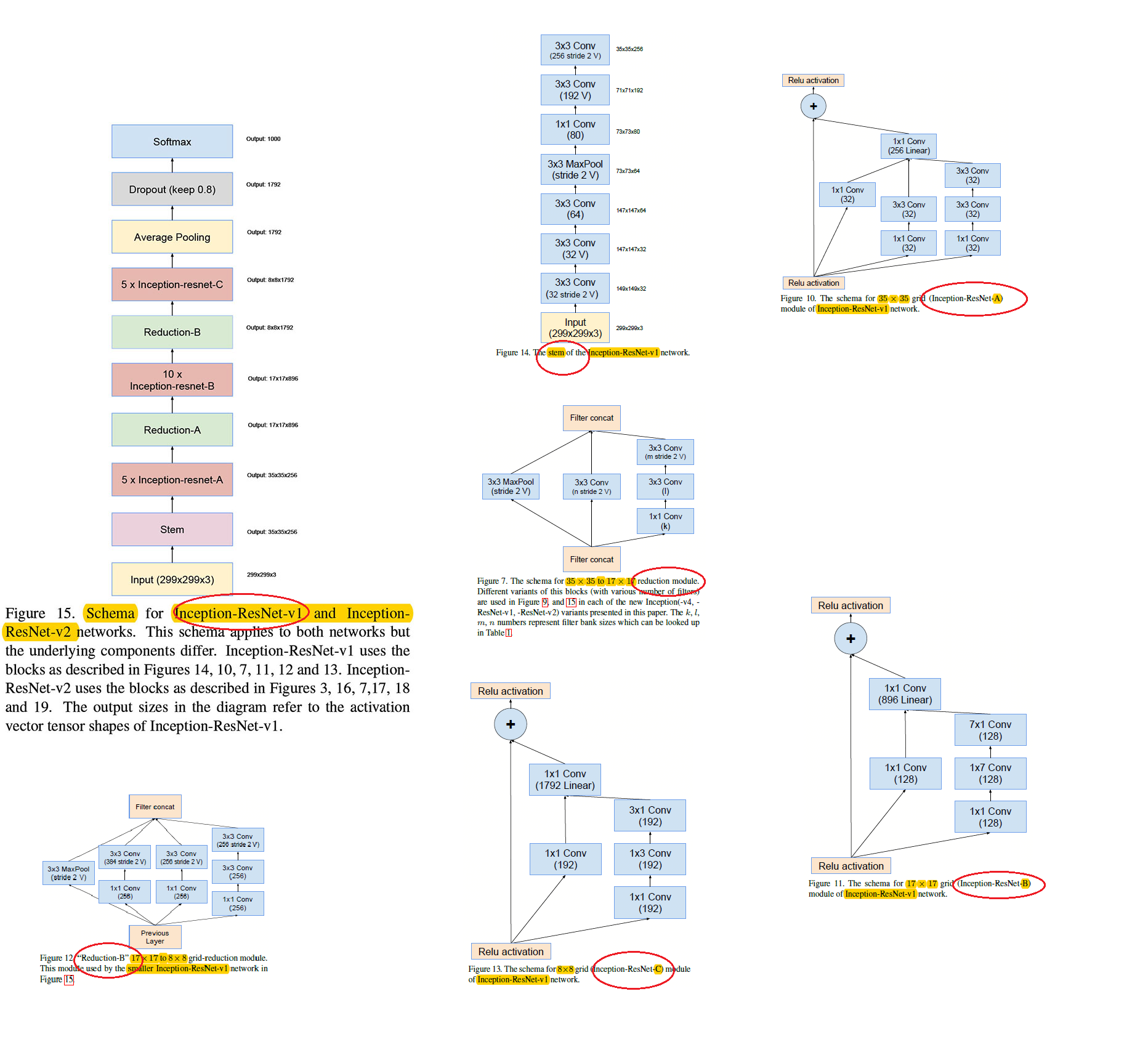
Inception-resnet-v1的結構圖
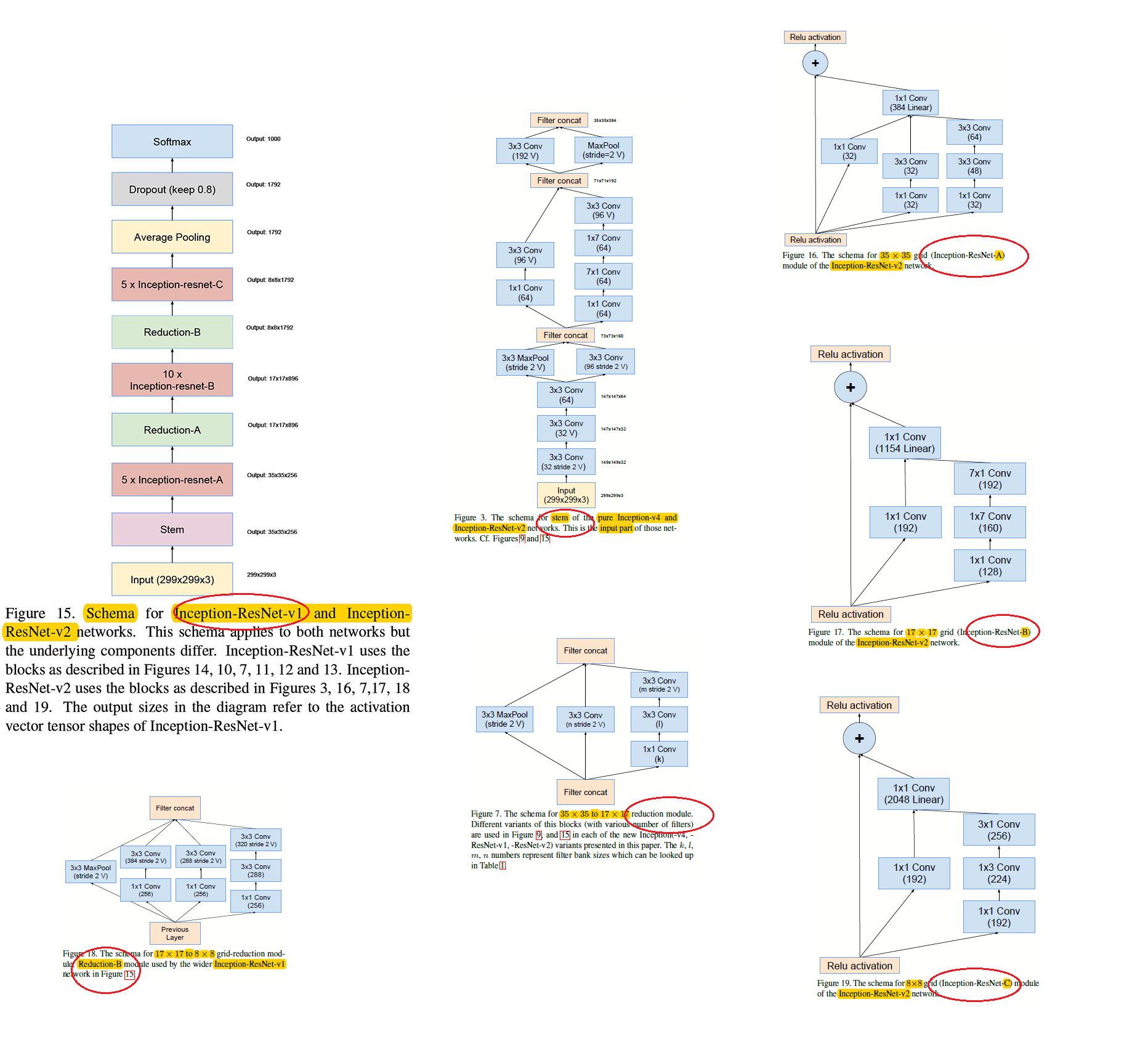
Inception-resnet-v2的結構圖
參考:https://blog.csdn.net/julialove102123/article/details/79632721