啟用函式 activation function
啟用函式 activation function
啟用函式的角色是引入非線性(non-linearity),否則不管網路有多深,整個網路都可以直接替換為一個相應的仿射變換(affine transformation),即線性變換(linear transformation),比如旋轉、伸縮、偏斜、平移(translation)。
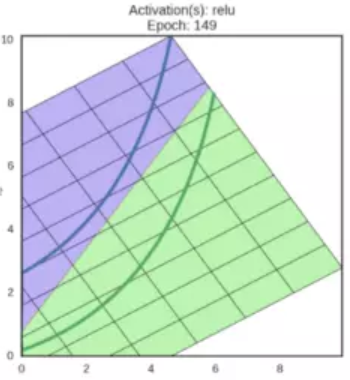
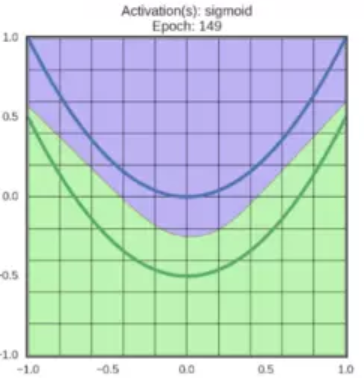
例如,在二維特徵空間上,藍線表示負面情形 ,綠線表示正面情形 :

如果不使用啟用函式,神經網路最好的分類效果如下:
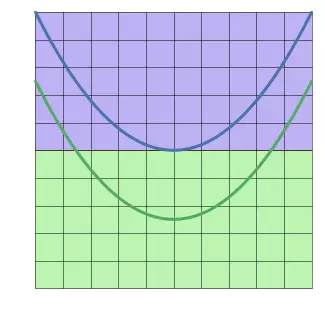
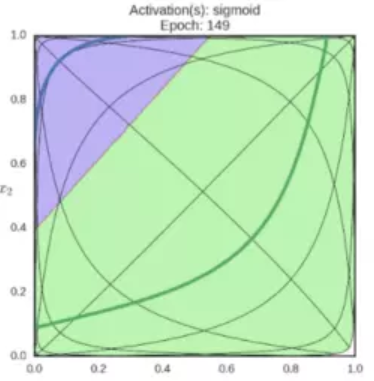
在仿射變換的結果上應用啟用函式,可以對特徵空間進行扭曲翻轉,最後得到一條線性可分的邊界。運轉中的sigmoid啟用函式:
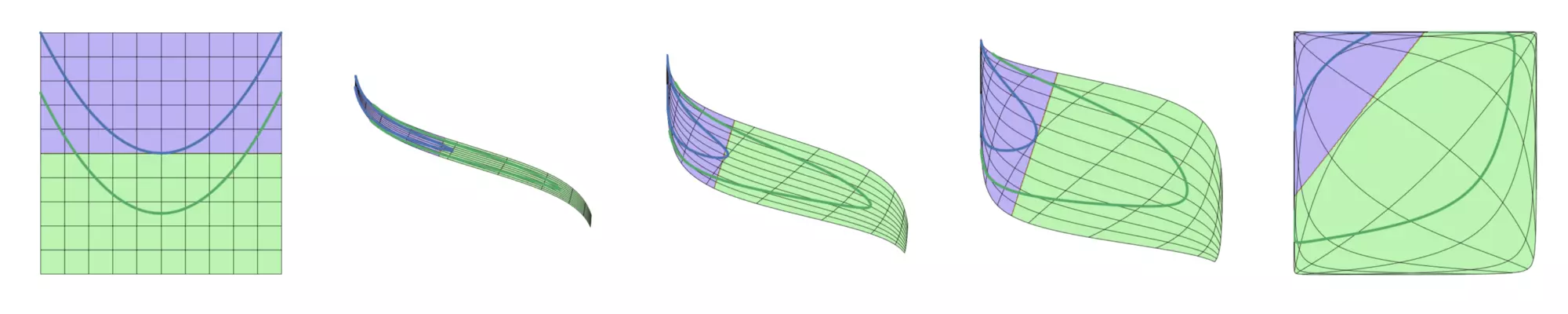
在同一個網路中混合使用不同型別的神經元是非常少見的,雖然沒有什麼根本性問題來禁止這樣做。
Sigmoid

sigmoid 非線性函式的數學公式是:
函式影象如上圖所示,它將輸入的值“擠壓”到 範圍內,很大的負數變成0,很大的正數變成1。
在歷史上,sigmoid 函式非常常用,這是因為它對於神經元的啟用頻率有良好的解釋:從完全不啟用(0)到在求和後的最大頻率處的完全飽和(saturated)的啟用(1)。
然而現在sigmoid函式已經很少使用了,這是因為它有兩個主要缺點:
-
Sigmoid函式飽和使梯度消失:
sigmoid神經元有一個不好的特性,就是當神經元的啟用在接近0或1處時會飽和:在這些區域,梯度幾乎為0。在反向傳播的時候,這個(區域性)梯度將會與整個損失函式關於該門單元輸出的梯度相乘。因此,如果區域性梯度非常小,那麼相乘的結果也會接近零,這會有效地“殺死”梯度,幾乎就有沒有訊號通過神經元傳到權重再到資料了。
同時,為了防止飽和,必須對於權重矩陣初始化特別留意。比如,如果初始化權重過大,那麼大多數神經元將會飽和,導致網路就幾乎不學習了。
-
Sigmoid函式的輸出不是零中心的:
這個性質並不是我們想要的,因為在神經網路後面層中的神經元得到的資料將不是零中心的,這一情況將影響梯度下降的運作,因為如果輸入神經元的資料總是正數(比如在 中每個元素都 ),那麼關於 的梯度在反向傳播的過程中,將會要麼全部是正數,要麼全部是負數(具體依整個表示式f而定)。這將會導致梯度下降權重更新時出現 字型的下降。
然而,由於整個批量的資料的梯度被加起來後,對於權重的最終更新將會有不同的正負,這樣就從一定程度上減輕了這個問題。因此,該問題相對於上面的神經元飽和問題來說只是個小麻煩,沒有那麼嚴重。
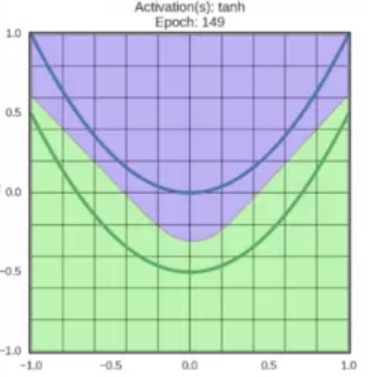
啟用變換效果:
Tanh
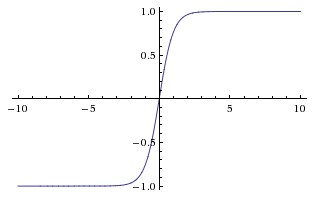
tanh神經元是一個簡單放大的sigmoid神經元。
tanh非線性函式的數學公式是 ,影象如上圖所示。它將實數值壓縮到 之間。和sigmoid神經元一樣,它也存在飽和問題,但是和sigmoid神經元不同的是,它的輸出是零中心的。因此,在實際操作中,tanh非線性函式比sigmoid非線性函式更受歡迎。

ReLU
ReLU(校正線性單元:Rectified Linear Unit)啟用函式,當 時函式值為0。當 函式的斜率為1。使用 ReLU 比使用 tanh 的收斂快6倍。
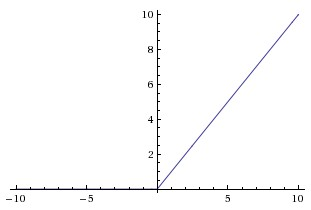
在近些年ReLU變得非常流行,它的函式公式是
ReLU的優點:
-
sigmoid 和 tanh 神經元含有指數運算等耗費計算資源的操作,而ReLU可以簡單地通過對一個矩陣進行閾值計算得到。
-
相較於sigmoid和tanh函式,ReLU對於隨機梯度下降的收斂有巨大的加速作用,據稱這是由它的線性,非飽和的公式導致的。
ReLU的缺點:
-
在訓練的時候,當一個很大的梯度流過 ReLU 的神經元的時候,可能會導致梯度更新到一種特別的狀態,從此,所有流過這個神經元的梯度將都變成0,導致資料多樣化的丟失。
-
如果學習率設定得太高,可能會發現網路中40%的神經元都會死掉(在整個訓練集中這些神經元都不會被啟用)。通過合理設定學習率,這種情況的發生概率會降低。