
[深度學習] 神經網路中的啟用函式(Activation function)
阿新 • • 發佈:2018-12-12
20180930 在研究調整FCN模型的時候,對啟用函式做更深入地選擇,記錄學習內容
啟用函式(Activation Function),就是在人工神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。
- 線性啟用函式:最簡單的linear function就是f(x) = x,不對輸入進行修改就直接輸出
- 非線性啟用函式:這些函式用於對不可線性分離的資料進行分離,是最常用的啟用函式。非線性方程控制從輸入到輸出的對映。常用的非線性啟用函式的例子是Sigmoid,tanH,ReLU,LReLU,PReLU,Swish等。
使用啟用函式的原因
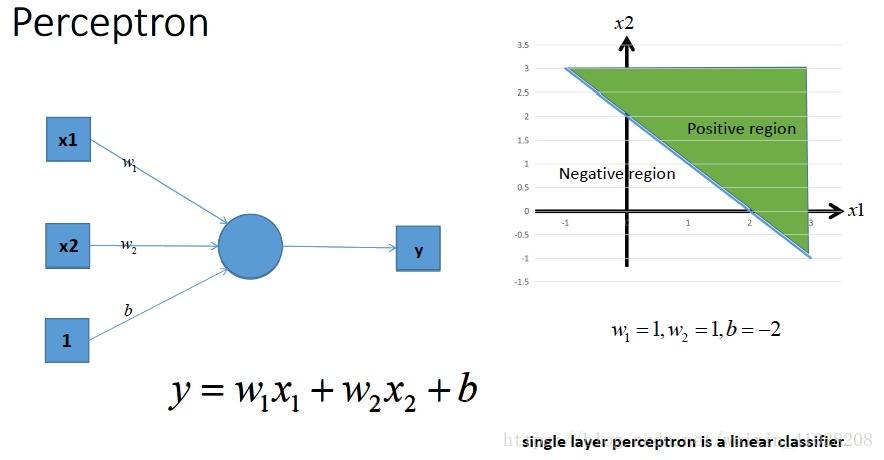
- 單層感知機 Perceptron
這是一個單層的感知機,也是我們最常用的神經網路組成單元,用它可以在平面中劃出一條線,把平面分割開,進行二分類。
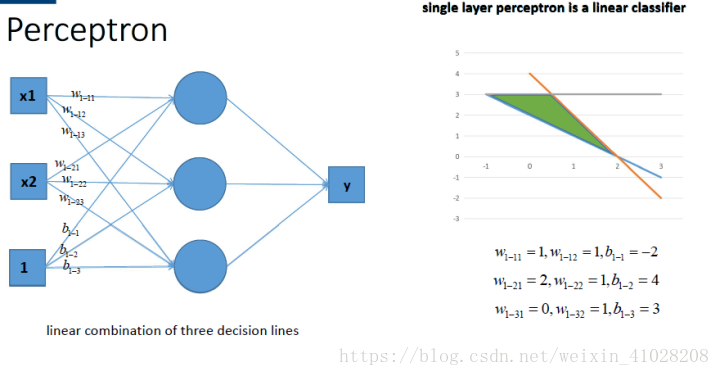
- 多感知機組合 Perceptron
多個感知機組合,能夠在平面中進行更復雜的分割,獲得更強的分類能力。
由感知機的結構來看,如果不用激勵函式,每一層輸出都是上層輸入的線性函式,無論神經網路有多少層,輸出都是輸入的線性組合,無法直接進行非線性分類

所以,我們要加入一種方式來完成非線性分類,這個方法就是啟用函式。
- 單層感知機
- 多層感知機


如果使用的話,啟用函式給神經元引入了非線性因素,使得神經網路可以任意逼近任何非線性函式,這樣神經網路就可以應用到眾多的非線性模型中。
- 使用step啟用函式的線性模型(step下面有介紹)
- 使用其他啟用函式的非線性模型,可能學習出更多的平滑分類


總結,使用啟用函式可以在神經網路中引入非線性分類方式,從而完成線性模型所不能完成的分類,解決真正的實際問題。
常用的啟用函式
-
step
- 圖形
- 圖形
-
Sigmoid
- 圖形
- 導數
- Tensorflow中
tf.sigmoid - 缺點
- Sigmoid有一個非常致命的缺點,當輸入非常大或者非常小的時候(saturation),這些神經元的梯度是接近於0的。如果你的初始值很大的話,神經元可能會停止梯度下降過程,這會導致網路變的無法學習。
- Sigmoid的曲線均值不為0,這會導致後一層的神經元將得到上一層輸出的非0均值的訊號作為輸入。 產生的一個結果就是:如果資料進入神經元的時候是正的,那麼計算出的梯度也會始終都是正的。如果是進行批訓練,訓練過程中會得到不同的訊號,這樣會緩解非0均值帶來的影響。
- 圖形
-
TanH
- 圖形
- 導數
- Tensorflow使用
tf.tanh - 缺點:實際上從根本上是sigmoid函式的變形體,解決了非0均值的問題,但不能解決過大或者過小時候導數接近於0的問題
- 圖形
-
Rectified linear unit (ReLU)
- 圖形
- 導數
- Tensorflow使用
tf.nn.relu(features, name = None) - 缺點:不幸的是,使用ReLU的神經元在訓練期間可能很脆弱並且可能“死亡”。 例如,經過ReLU神經元的梯度過大的下降可能導致權重可能不在更新(因為x<0時,y的值和導數都為0),即神經元將永遠不再在任何資料點上啟用。如果發生這種情況,那麼經過該神經元的梯度將從該點開始永遠為0。 也就是說,ReLU神經元可以在訓練期間不可逆轉地死亡。 例如,如果學習率設定得太高,您可能會發現多達40%的網路可能“死”(即永遠不會在整個訓練資料集中啟用的神經元)。 通過適當設定學習率,這也不是一個問題。
- 圖形
-
Leaky ReLU
- 圖形
- Tensorflow使用
tf.nn.leaky_relu(features, alpha=0.2, name=None),其中alpha為x<0時的斜率 - 解決了ReLU的“死”神經元問題
- 圖形
-
更多啟用函式詳細內容














ReLU應該是現階段使用最多的啟用函式。