
聚類演算法評估
1、調整蘭德指數(Adjusted Rand Index)
蘭德指數需要給定類別資訊C,假設K是聚類結果,蘭德指數表示式如下
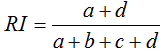
a為在C中為同一類且在K中也為同一類別的資料點對數
b為在C中為同一類但在K中卻隸屬於不同類別的資料點對數
c為在C中不在同一類但在K中為同一類別的資料點對數
d為在C中不在同一類且在K中也不屬於同一類別的資料點對數
RI的取值範圍為[0,1],值越大意味著聚類結果與真實情況越匹配,調整蘭德指數需要資料標記。
調整蘭德指數解決對於兩個隨機的劃分,其蘭德係數值不是一個接近於0的常數, 表示式如下
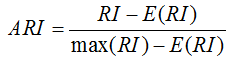
ARI的取值範圍為[-1,1],值越大意味著聚類結果與真實情況越匹配。可用於聚類演算法之間的比較。
sklearn介面:metrics.adjusted_rand_score(labels_true, labels_pred)
2、調整互資訊(Adjusted Mutual Information)
互資訊的表示式如下
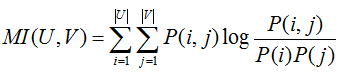
其中
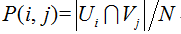
標準化互資訊
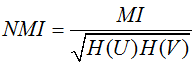
其中
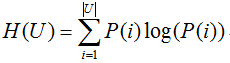
調整互資訊
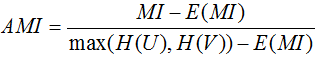
MI和NMI的取值範圍為[0,1],AMI的取值範圍為[-1,1],值越大意味著聚類結果與真實情況越匹配,調整互資訊需要資料標記。
sklearn介面:metrics.adjusted_mutual_info_score(labels_true, labels_pred)
3、同質性Homogeneity、完整性completeness、調和平均V-measure
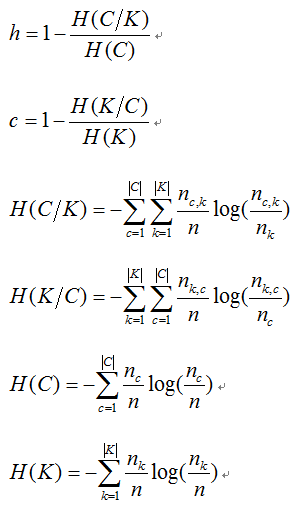
其中,n是樣本總數,nc和nk分別屬於類c和類k的樣本數,而nc,k是從類c劃分到類k的樣本數量。
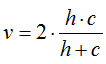
取值範圍為[0,1],完全隨機標籤並不總是產生相同的完整性和均勻性的值,所得調和平均值V-measure也不相同
sklearn介面:metrics.homogeneity_score(labels_true, labels_pred)
sklearn介面:metrics.completeness_score(labels_true, labels_pred)
sklearn介面:metrics.v_measure_score(labels_true, labels_pred)
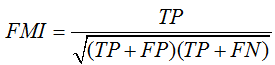
sklearn介面:metrics.fowlkes_mallows_score(labels_true, labels_pred)
5、輪廓係數(Silhouette Coefficient)
輪廓係數適用於實際類別資訊未知的情況。對於單個樣本,設a是與它同類別中其他樣本的平均距離,b是與它距離最近不同類別中樣本的平均距離,其輪廓係數為: 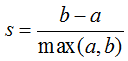
對於一個樣本集合,它的輪廓係數是所有樣本輪廓係數的平均值。輪廓係數的取值範圍是[-1,1],同類別樣本距離越相近不同類別樣本距離越遠,分數越高。
sklearn介面:metrics.silhouette_score(X, labels, metric=‘euclidean’)
前四種方法要求資料有標記,輪廓係數不要求資料有標記
寫部落格的目的是學習的總結和知識的共享,如有侵權,請與我聯絡,我將盡快處理