
論文筆記 《Fast R-CNN》
轉載自http://zhangliliang.com/2015/05/17/paper-note-fast-rcnn/
R-CNN的進化版,0.3s一張圖片,VOC07有70的mAP,可謂又快又強。 而且rbg的程式碼一般寫得很好看,應該會是個很值得學習的專案。
動機
為何有了R-CNN和SPP-Net之後還要提出Fast RCNN(簡稱FRCN)?因為前者有三個缺點
- 訓練的時候,pipeline是隔離的,先提proposal,然後CNN提取特徵,之後用SVM分類器,最後再做bbox regression。FRCN實現了end-to-end的joint training(提proposal階段除外)。
- 訓練時間和空間開銷大。RCNN中ROI-centric的運算開銷大,所以FRCN用了image-centric的訓練方式來通過卷積的share特性來降低運算開銷;RCNN提取特徵給SVM訓練時候需要中間要大量的磁碟空間存放特徵,FRCN去掉了SVM這一步,所有的特徵都暫存在視訊記憶體中,就不需要額外的磁碟空間了。
- 測試時間開銷大。依然是因為ROI-centric的原因,這點SPP-Net已經改進,然後FRCN進一步通過single scale testing和SVD分解全連線來提速。
整體框架
整體框架如Figure 1,如果以AlexNet(5個卷積和3個全連線)為例,大致的訓練過程可以理解為:
- selective search在一張圖片中得到約2k個object proposal(這裡稱為RoI)
- 縮放圖片的scale得到圖片金字塔,FP得到conv5的特徵金字塔。
- 對於每個scale的每個ROI,求取對映關係,在conv5中crop出對應的patch。並用一個單層的SPP layer(這裡稱為Rol pooling layer)來統一到一樣的尺度(對於AlexNet是6x6)。
- 繼續經過兩個全連線得到特徵,這特徵有分別share到兩個新的全連線,連線上兩個優化目標。第一個優化目標是分類,使用softmax,第二個優化目標是bbox regression,使用了一個smooth的L1-loss.
除了1,上面的2-4是joint training的。 測試時候,在4之後做一個NMS即可。
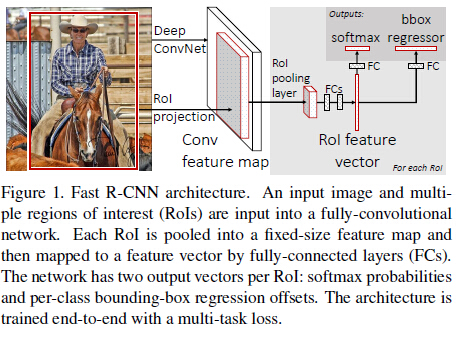

整體框架大致如上述所示了,對比回來SPP-Net,可以看出FRCN大致就是一個joint training版本的SPP-Net,改進如下:
- SPP-Net在實現上無法同時tuning在SPP layer兩邊的卷積層和全連線層。
- SPP-Net後面的需要將第二層FC的特徵放到硬碟上訓練SVM,之後再額外訓練bbox regressor。
接下來會介紹FRCN裡面的一些細節的motivation和效果。
Rol pooling layer
Rol pooling layer的作用主要有兩個,一個是將image中的rol定位到feature map中對應patch,另一個是用一個單層的SPP layer將這個feature map patch下采樣為大小固定的feature再傳入全連線層。 這裡有幾個細節。
- 對於某個rol,怎麼求取對應的feature map patch?這個論文沒有提及,筆者也還沒有仔細去摳,覺得這個問題可以到程式碼中尋找。:)
- 為何只是一層的SPP layer?多層的SPP layer不會更好嗎?對於這個問題,筆者認為是因為需要讀取pretrain model來finetuning的原因,比如VGG就release了一個19層的model,如果是使用多層的SPP layer就不能夠直接使用這個model的parameters,而需要重新訓練了。
Multi-task loss
FRCN有兩個loss,以下分別介紹。 對於分類loss,是一個N+1路的softmax輸出,其中的N是類別個數,1是背景。為何不用SVM做分類器了?在5.4作者討論了softmax效果比SVM好,因為它引入了類間競爭。(筆者覺得這個理由略牽強,估計還是實驗效果驗證了softmax的performance好吧 ^_^) 對於迴歸loss,是一個4xN路輸出的regressor,也就是說對於每個類別都會訓練一個單獨的regressor的意思,比較有意思的是,這裡regressor的loss不是L2的,而是一個平滑的L1,形式如下:

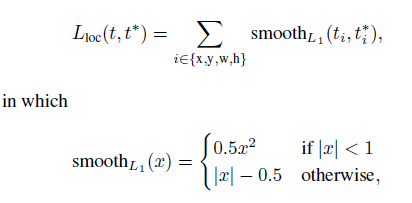
Scale invariance
這裡討論object的scale問題,就是網路對於object的scale應該是要不敏感的。這裡還是引用了SPP的方法,有兩種。
- brute force (single scale),也就是簡單認為object不需要預先resize到類似的scale再傳入網路,直接將image定死為某種scale,直接輸入網路來訓練就好了,然後期望網路自己能夠學習到scale-invariance的表達。
- image pyramids (multi scale),也就是要生成一個金字塔,然後對於object,在金字塔上找到一個大小比較接近227x227的投影版本,然後用這個版本去訓練網路。
可以看出,2應該比1更加好,作者也在5.2討論了,2的表現確實比1好,但是好的不算太多,大概是1個mAP左右,但是時間要慢不少,所以作者實際採用的是第一個策略,也就是single scale。 這裡,FRCN測試之所以比SPP快,很大原因是因為這裡,因為SPP用了2,而FRCN用了1。
SVD on fc layers
對應文中3.1,這段筆者沒細看。大致意思是說全連線層耗時很多,如果能夠簡化全連線層的計算,那麼能夠提升速度。 具體來說,作者對全連線層的矩陣做了一個SVD分解,mAP幾乎不怎麼降(0.3%),但速度提速30%
Which layers to finetune?
對應文中4.5,作者的觀察有2點
- 對於較深的網路,比如VGG,卷積層和全連線層是否一起tuning有很大的差別(66.9 vs 61.4)
- 有沒有必要tuning所有的卷積層?答案是沒有。如果留著淺層的卷積層不tuning,可以減少訓練時間,而且mAP基本沒有差別。
Data augment
在訓練期間,作者做過的唯一一個數據增量的方式是水平翻轉。 作者也試過將VOC12的資料也作為拓展資料加入到finetune的資料中,結果VOC07的mAP從66.9到了70.0,說明對於網路來說,資料越多就是越好的。
Are more proposals always better?
對應文章的5.5,答案是NO。 作者將proposal的方法粗略地分成了sparse(比如selective search)和dense(sliding windows)。
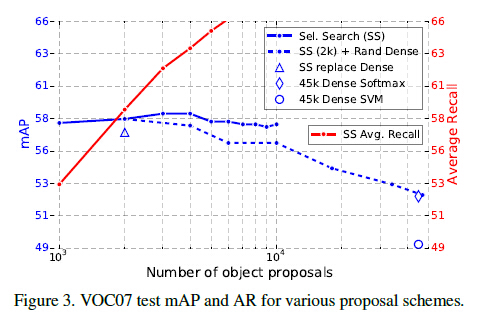
作者引用了文獻11的一句話來說明:““[sparse proposals] may improve detection quality by reducing spurious false positives.”
然後筆者搜尋了一下,發現文獻11被TPAMI15錄取了,看來也是要看一下啊。。