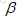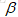機器學習:效能度量指標之查準率和查全率
在很多實際應用中,我們知道僅僅關心正確分類的結果是不夠的,並且,在資料偏斜比較嚴重的情況下,模型準確率可能具有相當程度的誤導性,我們也需要知道資料被錯誤分類的情況,以確認為此需要承擔的分類錯誤的代價。(False Positive假陽性和False Negative假陰性,這兩種情況)
查準率(Precision精度):用於描述所有被正確分類的樣本中真陽性的比值。
查全率(Recall召回率):真陽性樣本的數量與樣本集中所包含的全部陽性樣本的比值。
分類結果混淆矩陣
|
真實情況 |
預測結果 |
|
|
正 |
反 |
|
|
正 |
TP |
FN |
|
反 |
FP |
TN |
如上矩陣所示:
我們將演算法預測的結果分為四種情況:
TP(True Positive):真正例(正確肯定),預測為真,實際為真
FN(False Negative):假反例(錯誤否定),預測為假,實際為真
FP(False Positive):假正例(錯誤肯定),預測為真,實際為假
TN(True Negative):真反例(正確否定),預測為假,實際為假
假設我們想要用機器學習演算法來預測腫瘤是不是惡性的
其中,查準率的定義為:P=TP/(TP+FP)
它表示在所有我們預測有惡性腫瘤的病人中,實際患有惡性腫瘤的病人百分比,比例越高,說明FP越小,查得越準。
召回率定義為:R=TP/TP+FN
它表示在所有實際是惡性的樣例中,預測為惡性的比例。比例越高,說明FN越小,漏掉的惡性的樣例越少,查得越全。
降低閥值,提高Recall
提高閥值,提高Precision
在這塊我們可以看出,查準率和查全率直接是比較矛盾的,要想查準率高,那麼你就要將你最有把握認為是惡性的腫瘤選出來,但這樣就會漏掉一些被誤認為是良性,實際是惡性的腫瘤,使得查全率比較低;相反,要是想要查全率比較高,那麼就要在預測的時候儘可能多的預測一些腫瘤是惡性的,如果是這樣的話,那麼實際上是惡性的腫瘤確實被預測出來了,查全率也確實高了,但相應,查準率也降低了。
那麼在這塊,我們引入F1度量,用它來平衡查準率與查全率
F1 = 2*P*R/(P+R) = 2PR/(樣例總數-TP-TN)
若對查準率/查全率有不同偏好: