
計算機視覺系列-2-影象分類
給定一張輸入影象,影象分類的任務是判斷該影象屬於哪類, 如果是多工分類, 可以用於分類該影象包含哪個類別。
深度學習作為機器學習中非常重要的分支, 在影象領域中應用非常廣泛. 在影象分類任務中, 通常採用卷積層(CNN)提取特徵, 加上全連線層進行分類, 目前最常見的基於CNN的模型有以下幾種:
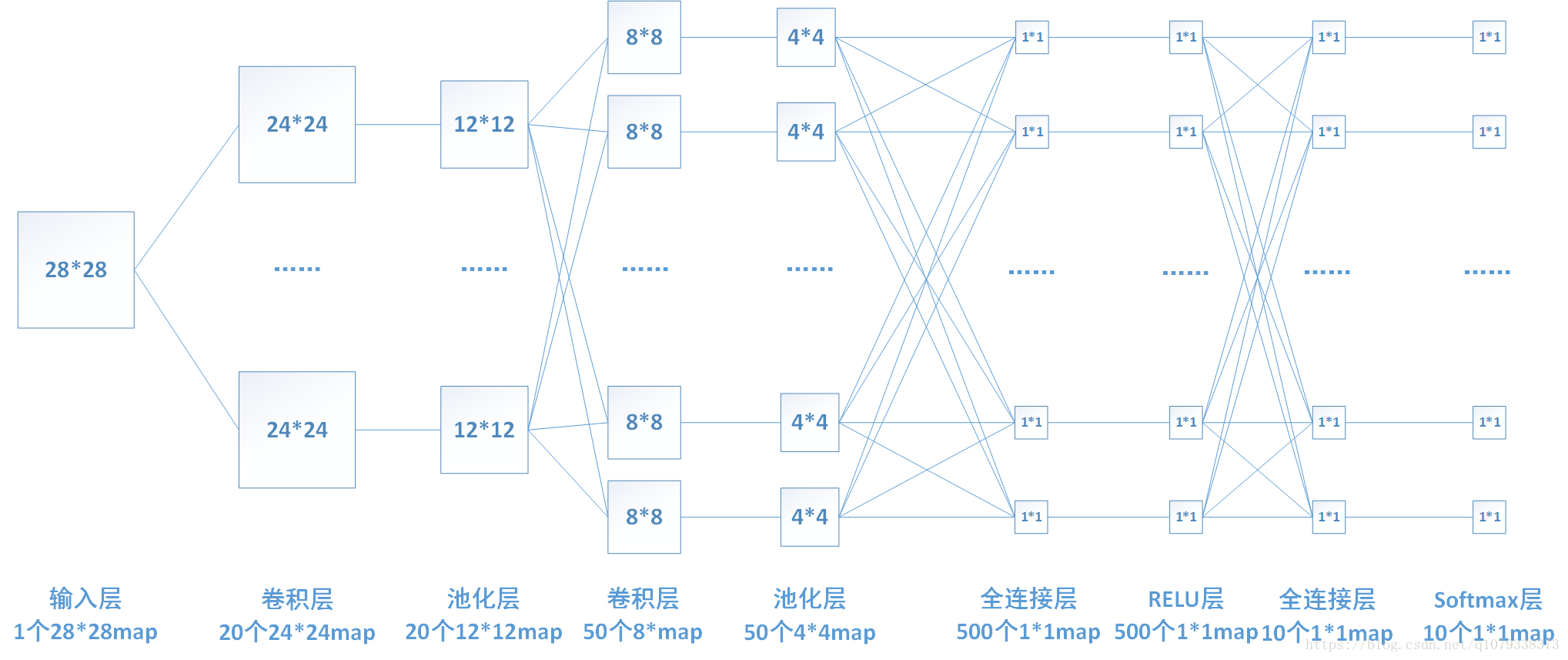
1: LeNet。
卷積網路的第一個成功應用是由Yann LeCun於1990年代開發的。其中最著名的是LeNet架構,用於讀取郵政編碼,數字等。
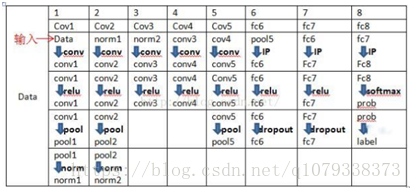
2: AlexNet。
該推廣卷積網路計算機視覺中的第一部作品是AlexNet,由亞歷克斯·克里維斯基,伊利亞·薩茨基弗和吉奧夫·欣頓發展。AlexNet在2012年被提交給ImageNet ILSVRC挑戰,明顯優於第二名(與亞軍相比,前5名錯誤為16%,26%的錯誤)。該網路與LeNet具有非常相似的體系結構,但是更深入,更大和更具特色的卷積層疊在彼此之上(以前通常只有一個CONV層緊隨著一個POOL層)。
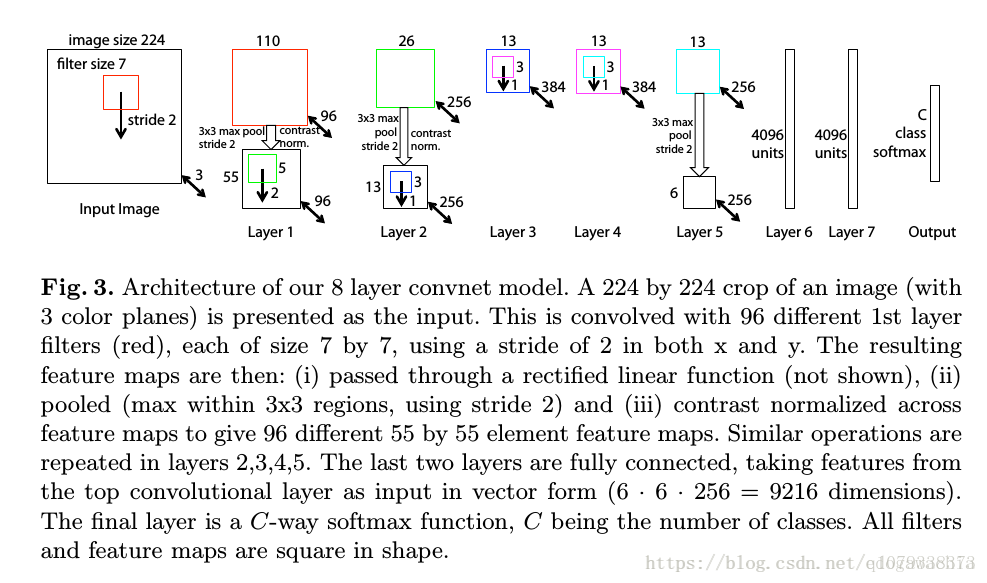
3: ZFNet。
ILSVRC 2013獲獎者是Matthew Zeiler和Rob Fergus的卷積網路。它被稱為ZFNet(Zeiler&Fergus Net的縮寫)。通過調整架構超引數,特別是通過擴充套件中間卷積層的大小,使第一層的步幅和過濾器尺寸更小,這是對AlexNet的改進。
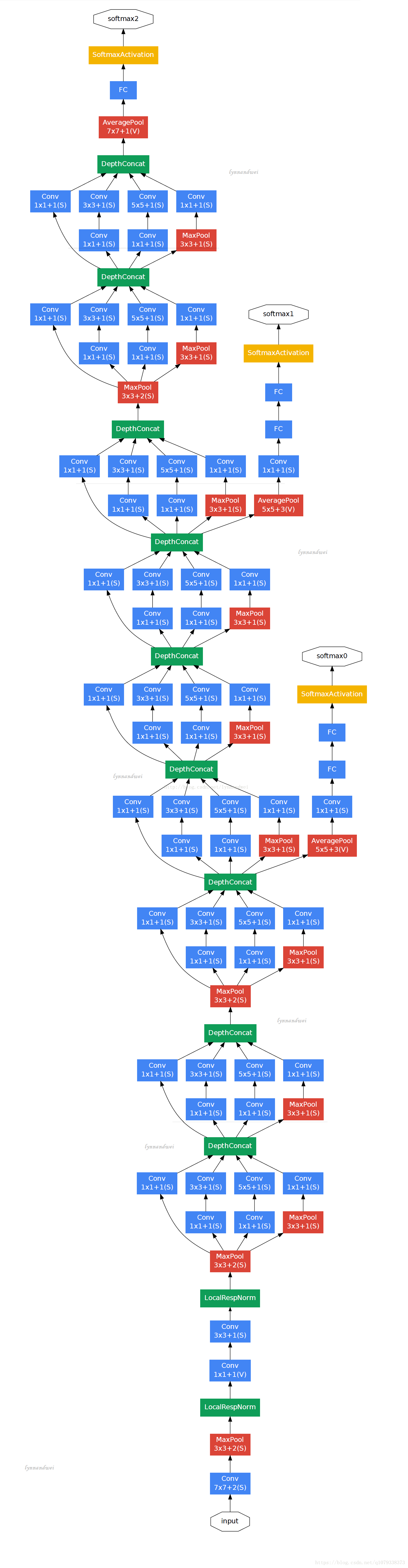
4: GoogleNet。
ILSVRC 2014獲獎者是Szegedy等人的卷積網路。來自Google。其主要貢獻是開發一個初始模組,大大減少了網路中的引數數量(4M,與AlexNet的60M相比)。此外,本文使用ConvNet頂部的“平均池”而不是“完全連線”層,從而消除了大量似乎並不重要的引數。
5: VGGNet。
VGG是Visual Geometry Group, Department of Engineering Science, University of Oxford的縮寫。他們組參加ILSVRC 2014時候組名叫VGG,所以提交的那種網路結構也叫VGG,或者叫VGGNet。VGG和GoogleNet同在2014年參賽,影象分類任務中GoogLeNet第一,VGG第二,它們都是重要的網路結構。
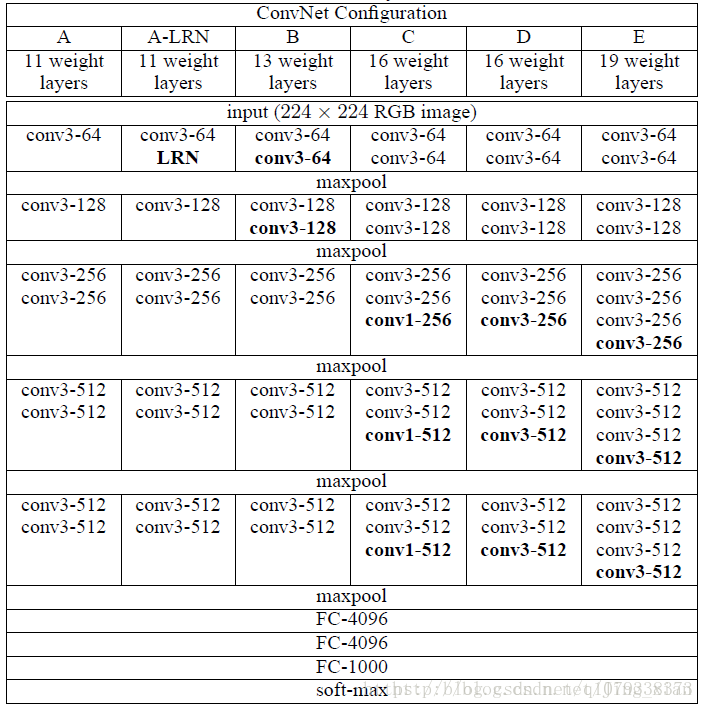
各種VGG的網路結構如下: 它的主要貢獻在於表明網路的深度是良好效能的關鍵組成部分。他們最終的最佳網路包含16個CONV / FC層,並且吸引人的是,具有非常均勻的架構,從始至終只能執行3x3卷積和2x2池。VGGNet的缺點是評估和使用更多的記憶體和引數(140M)是更昂貴的。這些引數中的大多數都在第一個全連線層中,因此發現可以在不降低效能的情況下去掉一些全連線層.
6: ResNet。
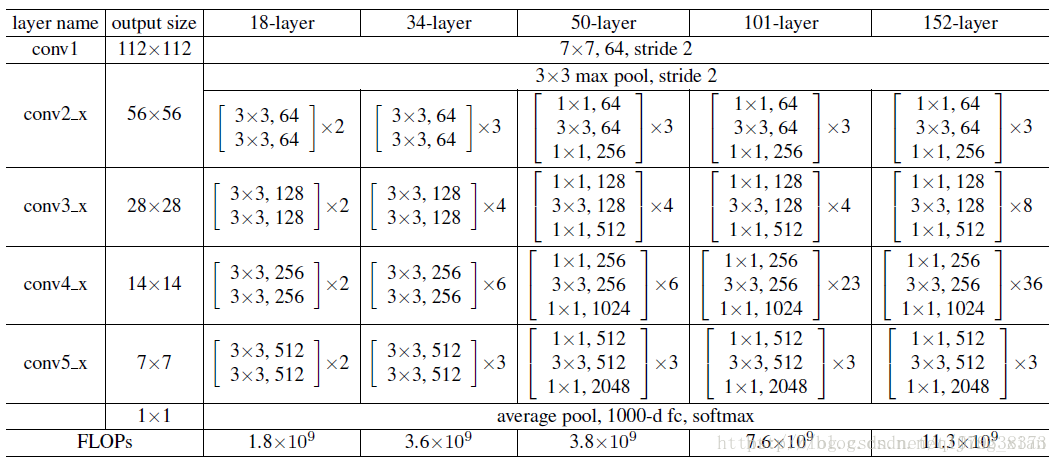
Kaiming He等人開發的殘留網路 是ILSVRC 2015的獲勝者。它具有特殊的跳過連線和批量歸一化的大量使用。該架構在網路末端也缺少完全連線的層。ResNets目前是迄今為止最先進的卷積神經網路模型.
以上就是最常用的卷積神經網路模型了. 現在github上有以上網路模型的實現, 並有在各種大型影象資料集,如imagenet中的訓練的權重可供下載, 然後用於提取特徵或微調. 當然自己也可以使用模型重新訓練權重, 當然自己也可以寫網路模型.深度學習框架中, tensorflow非常主流, 但是它構建模型的程式碼較為麻煩, 每一層的權重還要指定shape; keras框架是對tensorflow的常用功能進行了封裝, 所以寫網路結構特別簡單; 至於pytorch聽說寫網路結構也很簡單, 暫時沒用過, 不多說.