
spark筆記之DStream
3.1 什麼是DStream
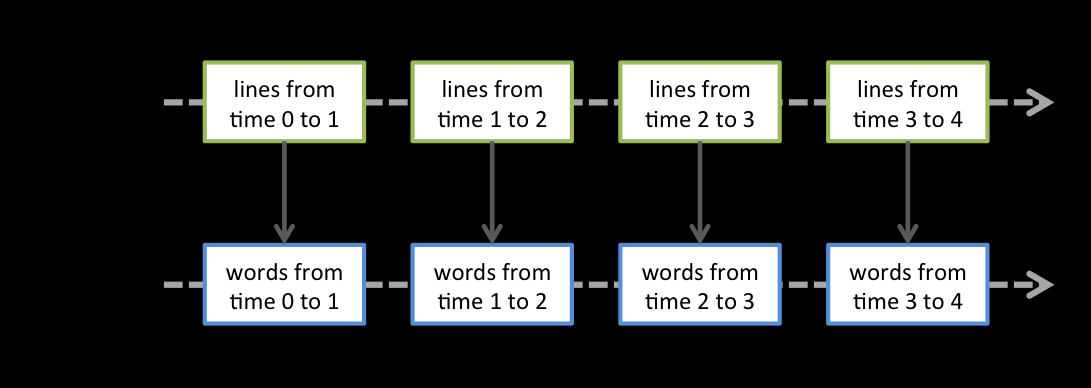
Discretized Stream是Spark Streaming的基礎抽象,代表持續性的資料流和經過各種Spark運算元操作後的結果資料流。在內部實現上,DStream是一系列連續的RDD來表示。每個RDD含有一段時間間隔內的資料,如下圖:

對資料的操作也是按照RDD為單位來進行的
Spark Streaming使用資料來源產生的資料流建立DStream,也可以在已有的DStream上使用一些操作來建立新的DStream。
它的工作流程像下面的圖所示一樣,接受到實時資料後,給資料分批次,然後傳給Spark Engine處理最後生成該批次的結果。

相關推薦
spark筆記之DStream
3.1 什麼是DStream Discretized Stream是Spark Streaming的基礎抽象,代表持續性的資料流和經過各種Spark運算元操作後的結果資料流。在內部實現上,DStream是一系列連續的RDD來表示。每個RDD含有一段時間間隔內的資料,如下圖:
spark筆記之數組、映射、元組、集合
轉變 mmu 寫法 構建 -o ipa 一個數 不包含 lec 1.1. 數組1.1.1. 定長數組和變長數組(1)定長數組定義格式:val arr=new ArrayT(2)變長數組定義格式:val arr = ArrayBuffer[T]()註意需要導包:import
spark筆記之模式匹配和樣例類
數組 object c spa 協調 一個 數據 好的 處理 zookeepe 階有一個十分強大的模式匹配機制,可以應用到很多場合:如開關語句,類型檢查等並且階還提供了樣例類,對模式匹配進行了優化,可以快速進行匹配。1.1。匹配字符串 package cn.itcast.c
spark筆記之Scala中的上下界
sca 有時 上下 park 允許 子類 類型 調用父類 使用 1.1. 上界、下界介紹在指定泛型類型時,有時需要界定泛型類型的範圍,而不是接收任意類型。比如,要求某個泛型類型,必須是某個類的子類,這樣在程序中就可以放心的調用父類的方法,程序才能正常的使用與運行。此時,就可
spark筆記之Scala演員並發編程
obj submit for 什麽 資源競爭 運用 art http 線程 1.1. 課程目標1.1.1. 目標一:熟悉Scala Actor並發編程1.1.2. 目標二:為學習Akka做準備註:Scala Actor是scala 2.10.x版本及以前版本的Actor。S
Spark筆記之Catalog
const lap 分享 stc rar 類型 保存 基本 params 一、什麽是Catalog Spark SQL提供了執行sql語句的支持,sql語句是以表的方式組織使用數據的,而表本身是如何組織存儲的呢,肯定是存在一些元數據之類的東西了,Catalog就是Spa
spark筆記之RDD的緩存
process color RoCE 就是 發現 mark 其他 動作 blog Spark速度非常快的原因之一,就是在不同操作中可以在內存中持久化或者緩存數據集。當持久化某個RDD後,每一個節點都將把計算分區結果保存在內存中,對此RDD或衍生出的RDD進行的其他動作中重用
spark筆記之DAG的生成
roc alt 開始 color part tex art RoCE shuff 8.1什麽是DAGDAG(Directed Acyclic Graph)叫做有向無環圖,原始的RDD通過一系列的轉換就形成了DAG,根據RDD之間依賴關系的不同將DAG劃分成不同的Stage(
spark筆記之Spark任務調度
fda 調度 water 周期 taskset 完成 構建 任務 shadow 9.1 任務調度流程圖各個RDD之間存在著依賴關系,這些依賴關系就形成有向無環圖DAG,DAGScheduler對這些依賴關系形成的DAG進行Stage劃分,劃分的規則很簡單,從後往前回溯,遇到
spark筆記之RDD容錯機制之checkpoint
原理 chain for 機制 方式 方法 相對 例如 contex 10.checkpoint是什麽(1)、Spark 在生產環境下經常會面臨transformation的RDD非常多(例如一個Job中包含1萬個RDD)或者具體transformation的RDD本身計算
spark筆記之Spark運行架構
示意圖 exe 使用 sta yarn 釋放 構建 遠程 work Spark運行基本流程Spark運行基本流程參見下面示意圖:1) 構建Spark Application的運行環境(啟動SparkContext),SparkContext向資源管理器(可以是Stand
Spark筆記之累加器(Accumulator)
apach inf color main nts lin uil long cat 一、累加器簡介 在Spark中如果想在Task計算的時候統計某些事件的數量,使用filter/reduce也可以,但是使用累加器是一種更方便的方式,累加器一個比較經典的應用場景是用來在S
spark筆記之Spark Streaming整合flume實戰
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.
spark筆記之Spark Streaming整合kafka實戰
kafka作為一個實時的分散式訊息佇列,實時的生產和消費訊息,這裡我們可以利用SparkStreaming實時地讀取kafka中的資料,然後進行相關計算。 在Spark1.3版本後,KafkaUtils裡面提供了兩個建立dstream的方法,一種為KafkaUtils.cr
spark筆記之陣列、對映、元組、集合
001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019
Spark 學習筆記之 MONGODB SPARK CONNECTOR 插入性能測試
log font span 技術 strong mongos str server 學習 MONGODB SPARK CONNECTOR 測試數據量: 測試結果: 116萬數據通過4個表的join,從SQL Server查出,耗時1分多。MongoSp
Spark 學習筆記之 Standalone與Yarn啟動和運行時間測試
span ima 上傳 運行 yarn erl 技術分享 word wordcount Standalone與Yarn啟動和運行時間測試: 寫一個簡單的wordcount: 打包上傳運行: Standalone啟動: 運行時間:
Spark 學習筆記之 Streaming Window
min .cn spa pan tex def rec mas clas Streaming Window: 上圖意思:每隔2秒統計前3秒的數據 slideDuration: 2 windowDuration: 3 例子: import org.apach
spark筆記2之spark粗略執行流程
目錄 一、Spark粗略的執行流程 二、程式碼流程 1、建立一個SparkConf 2、建立一個上下文物件SparkContext 3、建立一個RDD 4、使用transformations類運算元進行各種各樣的資料轉換 5、使用Action類運算元觸發執行 6、關閉
Spark學習筆記:DStream基本工作原理
DStream基本工作原理 DStream是Spark Streaming提供的一種高階抽象,英文全稱為Discretized Stream,中文翻譯為離散流,它代表了一個持續不斷的資料流。DStream可以通過輸入資料來源(比如從Flume、Kafka中)來建立,也可以通