
TensorFlow筆記-06-神經網路優化-損失函式,自定義損失函式,交叉熵
TensorFlow筆記-06-神經網路優化-損失函式,自定義損失函式
- **神經元模型:用數學公式比表示為:f(Σi xi*wi + b), f為啟用函式**
- 神經網路 是以神經元為基本單位構成的
- 啟用函式:引入非線性啟用因素,提高模型的表達能力 常用的啟用函式有relu、sigmoid、tanh等
- (1)啟用函式relu:在Tensorflow中,用tf.nn.relu()表示
- (2)啟用函式sigmoid:在Tensorflow中,用tf.nn.sigmoid()表示
- (3)啟用函式tanh:在Tensorflow中,用tf.nn.tanh()表示
- 神經網路的複雜度:可用神經網路的的層數和神經網路中待優化引數個數表示
- 神經網路的層數:一般不計入輸入層,層數 = n個隱藏層 + 1個輸入層
- 神經網路待優化的引數:神經網路中所有引數w的個數 + 所有引數b的個數
- 例如:
在該神經網路中,包含1個輸入層,1個隱藏層和1個輸出層,該神經網路的引數為2層 在該神經網路中,引數的個數是所有引數w的個數加上所有引數b的總數,第一層引數用三行四列的二階張量表示(即12個線上的權重w)再加上4個偏置b;第二層引數是四行二列的二階張量(即8個線上的權重w)再加上2個偏置b 總引數 = 34+4 + 42+2 = 26



損失函式
- 損失函式(loss):用來表示預測(y)與已知答案(y_)的差距。在訓練神經網路時,通過不斷改變神經網路中所有引數,使損失函式不斷減小,從而訓練出更高準確率的神經網路模型
- 常用的損失函式有均方誤差,自定義和交叉熵等
- 均方誤差mse:n個樣本的預測值(y)與(y_)的差距。在訓練神經網路時,通過不斷的改變神經網路中的所有引數,使損失函式不斷減小,從而訓練出更高準確率的神經網路模型
- 在Tensorflow中用loss_mse = tf.reduce_mean(tf.square(y_-y))
- 例如:
- 預測酸奶日銷量y,x1和x2是兩個影響日銷量的因素
- 應提前採集的資料有:一段時間內,每日的x1因素、x2因素和銷量y_。且資料儘量多
- 在本例子中用銷量預測產量,最優的產量應該等於銷量,由於目前沒有資料集,所以擬造了一套資料集。利用Tensorflow中函式隨機生成x1、x2,製造標準答案y_ = x1 + x2,為了真實,求和後還加了正負0.05的隨機噪聲
- 我們把這套自制的資料集喂入神經網路,構建一個一層的神經網路,擬合預測酸奶日銷量的函式
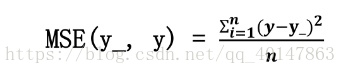
# coding:utf-8
# 預測多或者預測少的影響一樣
# 匯入模組,生成資料集
import tensorflow as tf
import numpy as np
# 一次喂入神經網路8組資料,數值不可以過大
BATCH_SIZE = 8
SEED = 23455
# 基於seed產生隨機數
rdm = np.random.RandomState(SEED)
# 隨機數返回32行2列的矩陣 表示32組 體積和重量 作為輸入資料集
X = rdm.rand(32, 2)
Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
print("X:\n", X)
print("Y:\n", Y_)
# 定義神經網路的輸入,引數和輸出,定義前向傳播過程
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# w1為2行1列
w1 = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1)
# 定義損失函式及反向傳播方法
# 定義損失函式為MSE,反向傳播方法為梯度下降
loss_mse = tf.reduce_mean(tf.square(y_-y))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
# 其他優化方法
# train_step = tf.train.GMomentumOptimizer(0.001, 0.9).minimize(loss_mse)
# train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse)
# 生成會話,訓練STEPS輪
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 訓練模型20000輪
STEPS = 20000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
# 沒500輪列印一次loss值
if i % 1000 == 0:
total_loss = sess.run(loss_mse, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss on all data is %g" %(i, total_loss))
print(sess.run(w1),"\n")
print("Final w1 is: \n", sess.run(w1))執行結果
結果分析
有上述程式碼可知,本例中神經網路預測模型為y = w1x1 + w2x2,損失函式採用均方誤差。通過使損失函式值(loss)不斷降低,神經網路模型得到最終引數w1 = 0.98,w2 = 1.02,銷量預測結果為y = 0.98x1 + 1.02x2。由於在生成資料集時,標準答案為y = x1 + x2,因此,銷量預測結果和標準答案已經非常接近,說明該神經網路預測酸奶日銷量正確
自定義損失函式
- 自定義損失函式:根據問題的實際情況,定製合理的損失函式
- 例如:
- 對於預測酸奶日銷量問題,如果預測銷量大於實際銷量則會損失成本;如果預測銷量小於實際銷量則會損失利潤。在實際生活中,往往製造一盒酸奶的成本和銷售一盒酸奶的利潤不是等價的。因此,需要使用符合該問題的自定義損失函式
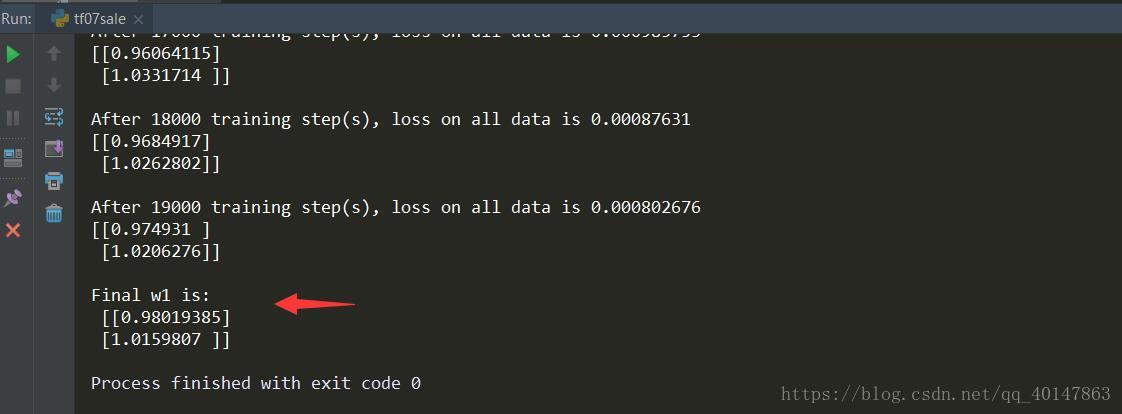
- 自定義損失函式為:loss = Σnf(y_, y)
- 其中,損失函式成分段函式:
- 損失函式表示
- 若預測結果y小於標準答案y_,損失函式為利潤乘以預測結果y與標準答案之差
- 若預測結果y大於標準答案y_,損失函式為成本乘以預測結果y與標準答案之差
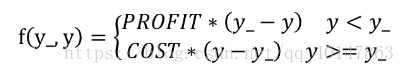
用Tensorflow函式表示為:
- loss = tf.reduce_sum(tf.where(tf.greater(y, y_), COST(y-y_), PROFIT(y_-y)))
(1)第1種情況:若酸奶成本為1元,酸奶銷售利潤為9元,則製造成本小於酸奶利潤,因此希望預測結果y多一些。採用上述的自定義損失函式,訓練神經網路模型
# 第一種情況:酸奶成本1元,酸奶利潤9元
# 預測少了損失大,故不要預測少,故生成的模型會多預測一些
# 匯入模組,生成資料集
import tensorflow as tf
import numpy as np
# 一次喂入神經網路8組資料,數值不可以過大
BATCH_SIZE = 8
SEED = 23455
COST = 1
PROFIT = 9
# 基於seed產生隨機數
rdm = np.random.RandomState(SEED)
# 隨機數返回32行2列的矩陣 表示32組 體積和重量 作為輸入資料集
X = rdm.rand(32, 2)
Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
# 定義神經網路的輸入,引數和輸出,定義前向傳播過程
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# w1為2行1列
w1 = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1)
# 定義損失函式及反向傳播方法
# 定義損失函式使得預測少了的損失大,於是模型應該偏向多的放心預測
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), COST*(y-y_), PROFIT*(y_-y)))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
# 其他優化方法
# train_step = tf.train.GMomentumOptimizer(0.001, 0.9).minimize(loss)
# train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
# 生成會話,訓練STEPS輪
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 訓練模型20000輪
STEPS = 20000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
# 沒500輪列印一次loss值
if i % 1000 == 0:
total_loss = sess.run(loss, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss on all data is %g" %(i, total_loss))
print(sess.run(w1),"\n")
print("Final w1 is: \n", sess.run(w1))執行結果
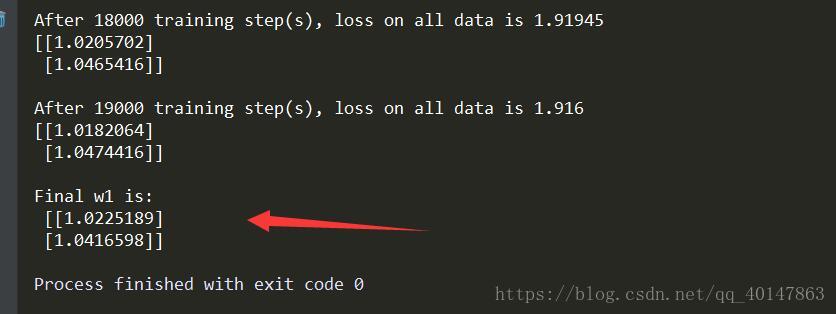
執行結果分析
由程式碼執行結果可知,神經網路最終引數為w1=1.03,w2=1.05,銷量預測結果為y = 1.03x1 + 1.05x2。由此可見,採用自定義損失函式預測的結果大於採用均方誤差的結果,更符合實際需求
(2)第2種情況:若酸奶成本為9元,酸奶銷售利潤為1元,則製造利潤小於酸奶成本,因此希望預測結果y小一些。採用上述的自定義損失函式,訓練神經網路模型
# 第二種情況:酸奶成本9元,酸奶利潤1元
# 預測多了損失大,故不要預測多,故生成的模型會少預測一些
# 匯入模組,生成資料集
import tensorflow as tf
import numpy as np
# 一次喂入神經網路8組資料,數值不可以過大
BATCH_SIZE = 8
SEED = 23455
COST = 9
PROFIT = 1
# 基於seed產生隨機數
rdm = np.random.RandomState(SEED)
# 隨機數返回32行2列的矩陣 表示32組 體積和重量 作為輸入資料集
X = rdm.rand(32, 2)
Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
# 定義神經網路的輸入,引數和輸出,定義前向傳播過程
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# w1為2行1列
w1 = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1)
# 定義損失函式及反向傳播方法
# 重新定義損失函式使得預測多了的損失大,於是模型應該偏向少的方向預測
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), COST*(y-y_), PROFIT*(y_-y)))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
# 其他優化方法
# train_step = tf.train.GMomentumOptimizer(0.001, 0.9).minimize(loss)
# train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
# 生成會話,訓練STEPS輪
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 訓練模型20000輪
STEPS = 20000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
# 沒500輪列印一次loss值
if i % 1000 == 0:
total_loss = sess.run(loss, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss on all data is %g" %(i, total_loss))
print(sess.run(w1),"\n")
print("Final w1 is: \n", sess.run(w1))執行結果
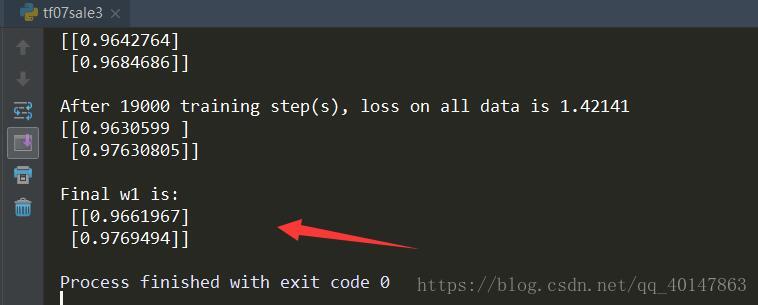
執行結果分析
由執行結果可知,神經網路最終引數為w1 = 0.96,w2 = 0.97,銷量預測結果為y = 0.96+x1 + 0.7*x2。 因此,採用自定義損失函式預測的結果小於採用均方誤差預測得結果,更符合實際需求
交叉熵
- 交叉熵(Cross Entropy):表示兩個概率分佈之間的距離,交叉熵越大,兩個概率分佈距離越遠,兩個概率分佈越相異;交叉熵越小,兩個概率分佈距離越近,兩個概率分佈越相似
- 交叉熵計算公式:H(y_, y) = -Σy_ * log y
用 Tensorflow 函式表示
ce = -tf.reduce_mean(y_*tf.clip_by_value(y, le-12, 1.0)))
- 例如: 兩個神經網路模型解決二分類問題中,已知標準答案為 y_ = (1, 0),第一個神經網路模型預測結果為 y1 = (0.6, 0.4),第二個神經網路模型預測結果為 y2 = (0.8, 0.2),判斷哪個神經網路模型預測得結果更接近標準答案
根據交叉熵的計算公式得:
H(1, 0), (0.6, 0.4) = -(1 * log0.6 + 0log0.4) ≈ -(-0.222 + 0) = 0.222 H(1, 0), (0.8, 0.2) = -(1 log0.8 + 0*log0.2) ≈ -(-0.097 + 0) = 0.097
softmax 函式
- softmax 函式:將 n 分類中的 n 個輸出(y1, y2...yn)變為滿足以下概率分佈要求的函式: ∀x = P(X = x) ∈ [0, 1]
- softmax 函式表示為:
- softmax 函式應用:在 n 分類中,模型會有 n 個輸出,即 y1,y2 ... n, 其中yi表示第 i 中情況出現的可能性大小。將 n 個輸出經過 softmax 函式,可得到符合概率分佈的分類結果
在 Tensorflow 中,一般讓模型的輸出經過 softmax 函式,以獲得輸出分類的概率分佈再與標準答案對比,求出交叉熵,得到損失函式,用如下函式實現:
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, 1)) cem = tf.reduce_mean(ce)
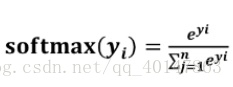
- 本筆記不允許任何個人和組織轉載