
python3 爬蟲實戰:mitmproxy 對接 python 下載抖音小視訊
From:https://blog.csdn.net/Fan_shui/article/details/81461253
一、前言
前面我們已經用 appium 爬取了微信朋友圈,今天我們學習下 mitmproxy,mitmproxy 是幹什麼的呢,它跟 charles 和 fiddler類似,是一個抓包工具,以控制檯的形式顯示,mitmproxy 的重要性在於它可以對接 python,可以通過 python 處理抓包的資料。試想一下我們如果不用 mitmproxy,用 fiddler 抓取抖音的視訊地址,我們可以抓到視訊的地址,這些地址要是可以直接用requests 快取下來就好了,mitmproxy 就派上用場了。
知乎:
GitHub:https://github.com/FanShuixing/git_webspider
二、學習目標
可以根據抖音號和抖音名稱爬取到對應的抖音小視訊
三、學習資料(感謝分享)
崔大的mitmproxy安裝教程:https://cuiqingcai.com/5391.html
抖音教程:https://blog.csdn.net/mp624183768/article/details/80956368
fiddler的使用:
四、mitmproxy的安裝
請先按照崔大的mitmproxy的安裝 進行安裝和證書的配置,如果安卓證書安裝有問題,可以參看下面(華為手機,應該普遍適用):
把檔案複製到手機qq後,可以在檔案管理的下載中檢視qq檔案
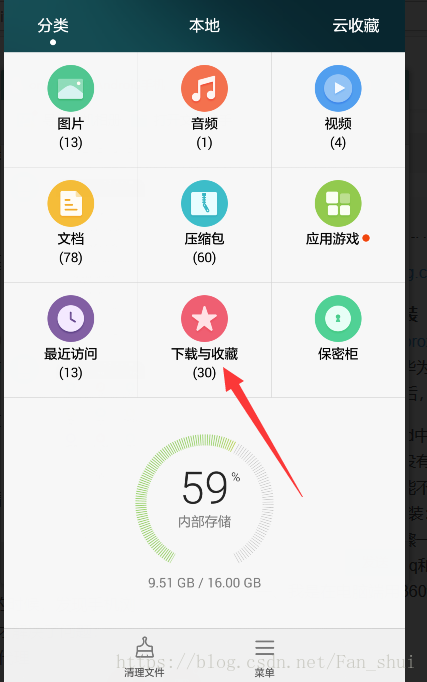
第一個是我們下載的證書,長按後勾上它
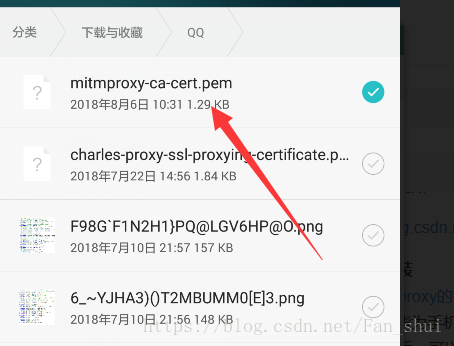
點選下面的選單,檢視詳情,這樣可以看見這個證書的具體位置,一會有用
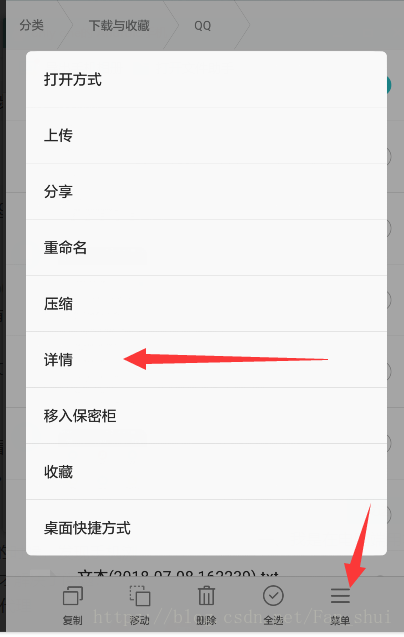
電腦開啟360WiFi後,手機連線上360WiFi,在WiFi裡面的選單
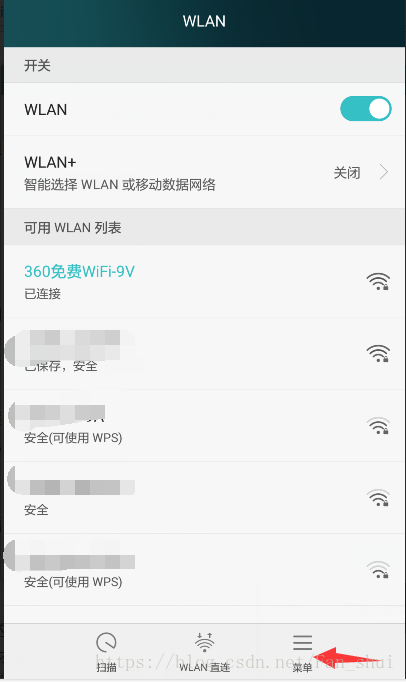
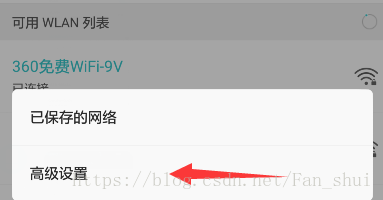
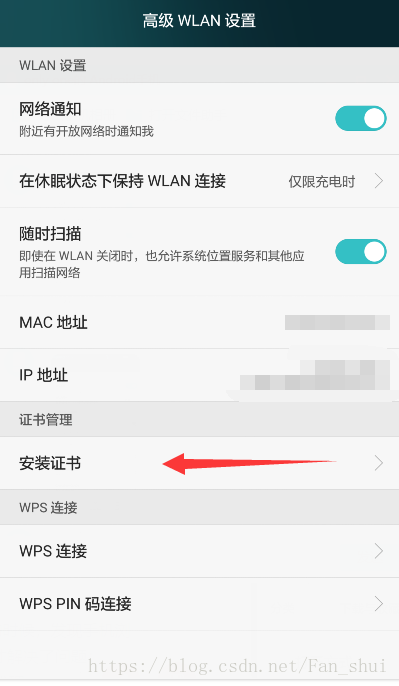
安裝證書就需要找到證書的位置,這樣剛才我們在檔案管理裡面看到的位置就可以在這兒用到,找到證書安裝即可。
配置代理
證書安裝完成後,要配置手機和電腦處在同一個區域網內,我建議用360wifi,其它wifi應該也可以,但是最好不要用自己家路由器的wifi,我家wifi測試的時候沒成功,360WiFi才成功了的。
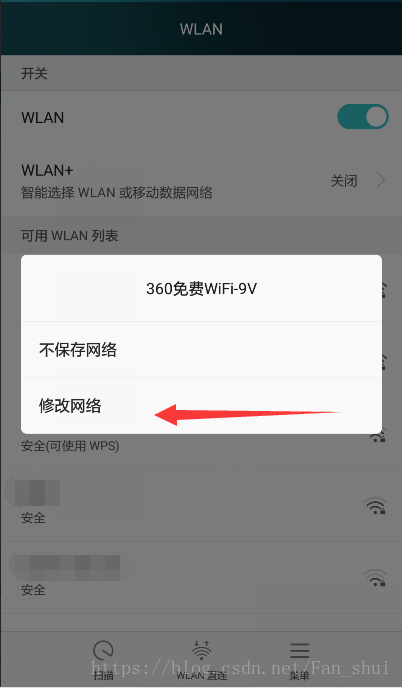
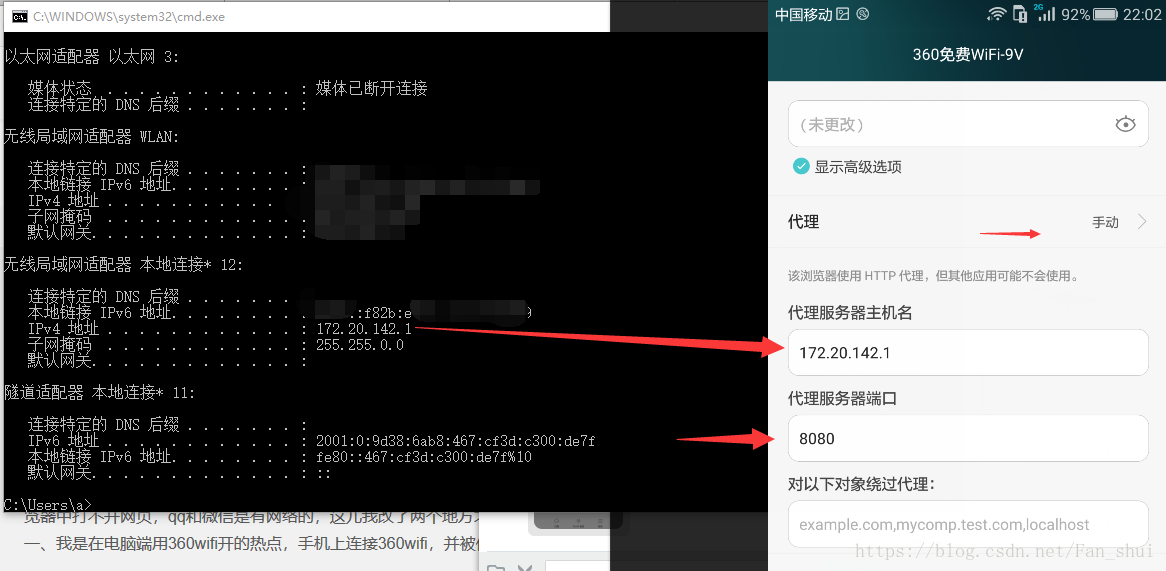
如果弄完之後,在cmd中輸入mitmdump,在手機中開啟瀏覽器看看有沒有網路,看看電腦的控制檯有沒有輸出抓取資訊,如果有,恭喜你安裝成功。如果沒有,憋著急,看看我的辦法能不能幫助你:
建議:弄完後我發現手機瀏覽器中打不開網頁,qq和微信是有網路的,我重新安裝了一下mitmproxy,不過不是用pip安裝,而是直接下載的 安裝檔案:https://github.com/mitmproxy/mitmproxy/releases, 選擇個exe就行
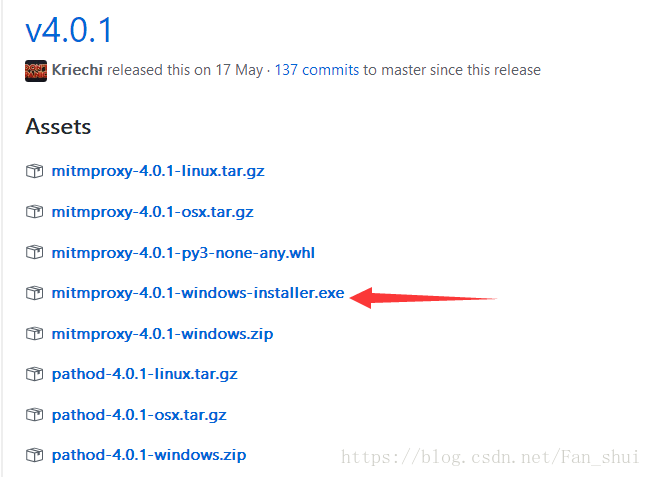
安裝好後,檢視安裝路徑下的bin資料夾,裡面有個mitmdump.exe,雙擊它開啟代理服務,這個時候再在手機上重新整理網頁發現mitmdump有請求輸出。
五、用fiddler分析介面
不知道大家用 fiddler不,我抓包更喜歡用它,方便簡潔,mitmdump 的唯一優勢是可以對接 python,但是我感覺它不好分析呀,所以我是把 fiddler開著,分析下介面,再用mitmdump對接python,fiddler我就不介紹了。
網上教程很多,可以參看:https://blog.csdn.net/c406495762/article/details/76850843(博主大大寫的超棒)
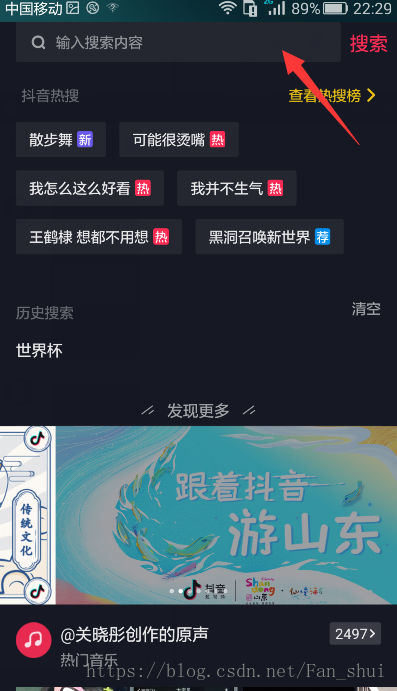
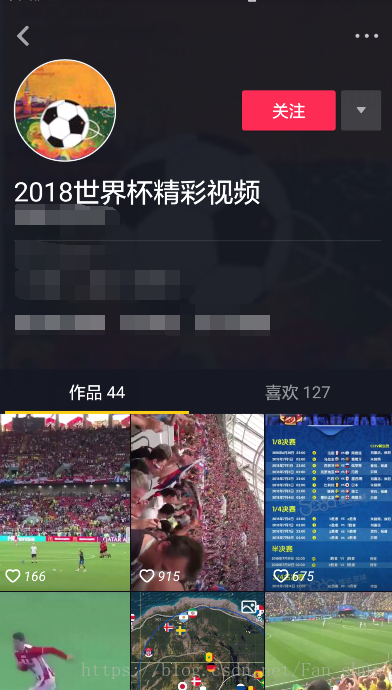
我們在手機中開啟上圖中的頁面後,在fiddler中會發現,有一個這樣的網址被抓取到
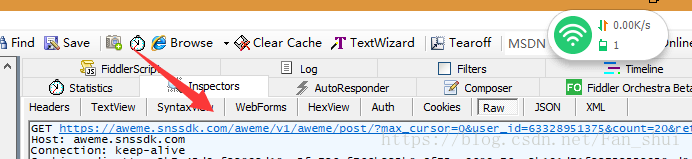
它的json資料中有視訊資訊
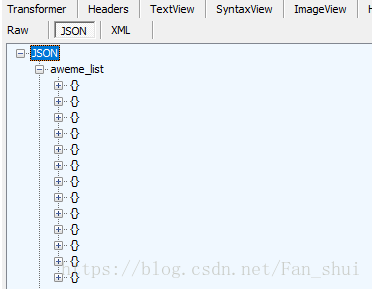
開啟aweme_list中的一個{},裡面是一個視訊的資訊,有對視訊的描述,也有使用者的id,也有video的url
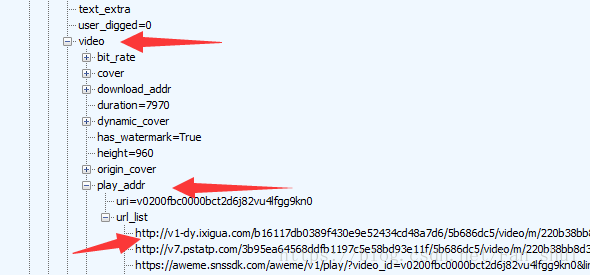
url_list裡面的url就是視訊的url,隨便選一個就是了。
六、對接python
# douyin_t.py
import json
def response(flow):
url = 'https://api.amemv.com/aweme/v1/aweme/post/'
# 篩選出以上面url為開頭的url
if flow.request.url.startswith(url):
text = flow.response.text
# 將已編碼的json字串解碼為python物件
data = json.loads(text)
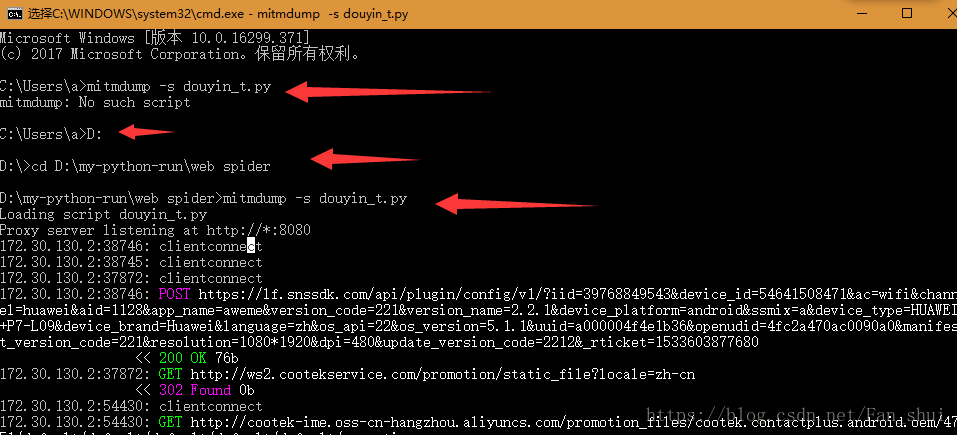
print(data)我把程式碼儲存在了D:\my-python-run\web spider目錄下,所以我得先到這個目錄下,這樣mitmdump才能找到我的python指令碼,然後執行命令 mitmdump -s douyin_t.py
在手機上開啟抖音,搜尋到你想下載的使用者的抖音主頁
可以發現mitmdump有資料輸出
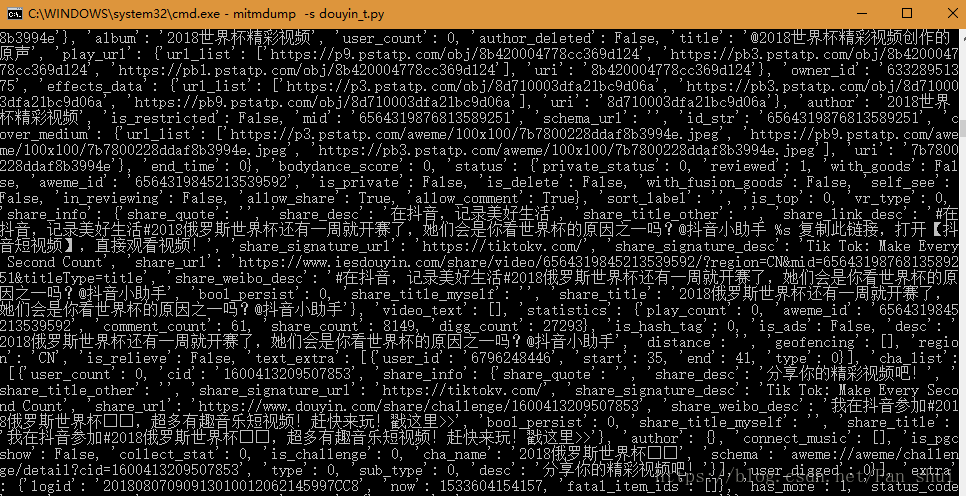
接下來我們只需提取視訊的url,並快取視訊到本地
# douyin_t.py
import json, os
def response(flow):
url = 'https://api.amemv.com/aweme/v1/aweme/post/'
# 篩選出以上面url為開頭的url
if flow.request.url.startswith(url):
text = flow.response.text
# 將已編碼的json字串解碼為python物件
data = json.loads(text)
# print(data)
# 在fiddler中剛剛看到每一個視訊的所有資訊
# 都在aweme_list中
video_url = data['aweme_list']
path = 'E:/爬蟲資料/douyin'
if not os.path.exists(path):
os.mkdir(path)
for each in video_url:
# 視訊描述
desc = each['desc']
url = each['video']['play_addr']['url_list'][0]
print(desc, url)執行如下:
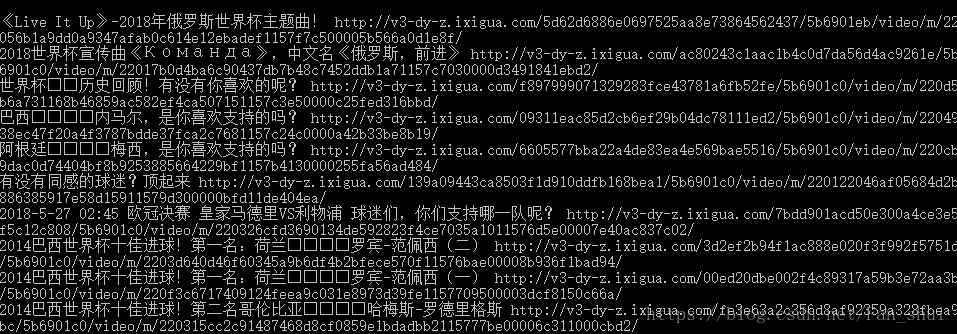
現在只需要用requests把這些url快取到本地,首先要匯入requests庫
# douyin_t.py
import json, os
import requests
def response(flow):
url = 'https://api.amemv.com/aweme/v1/aweme/post/'
# 篩選出以上面url為開頭的url
if flow.request.url.startswith(url):
text = flow.response.text
# 將已編碼的json字串解碼為python物件
data = json.loads(text)
# print(data)
# 在fiddler中剛剛看到每一個視訊的所有資訊
# 都在aweme_list中
video_url = data['aweme_list']
path = 'E:/爬蟲資料/douyin'
if not os.path.exists(path):
os.mkdir(path)
for each in video_url:
# 視訊描述
desc = each['desc']
url = each['video']['play_addr']['url_list'][0]
print(desc, url)不幸的是,我只是匯入了個requests庫,其他什麼都沒有改程式便報錯了
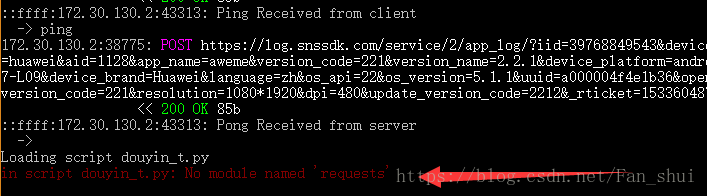
No module named ‘requests’,簡直黑人問號臉,怎麼會沒有requests呢,我天天都在用,怎麼會報這個錯呢?
解決辦法:相信大家也都安裝了requests庫了的,如果你也報這種錯誤,我們就再來搗鼓下路徑問題,提示是沒有requests模組,我非常確定我有這個模組,那隻能說明mitmdump在執行指令碼的時候沒有找到requests模組,那我們可以把我們的指令碼douyi_t.py放在與requests一個檔案下執行
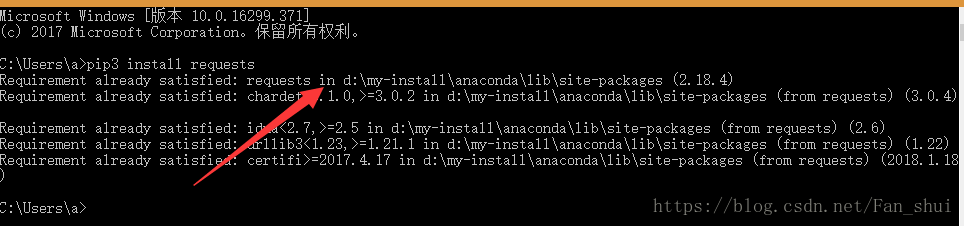
可以通過上述命令看到我的requests庫在D:\my-install\Anaconda\Lib\site-packages,我們把douyin_t.py放在這兒
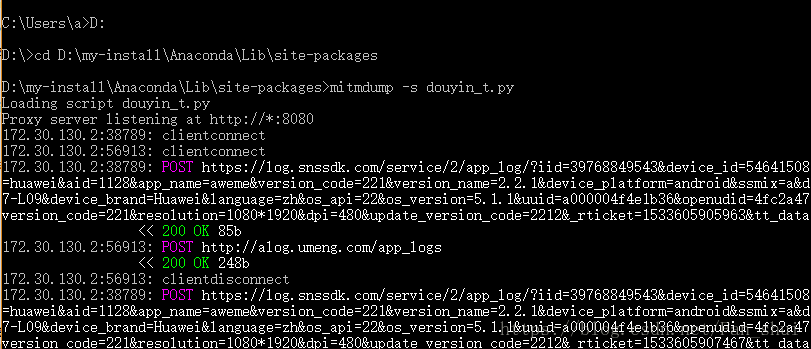
現在就沒有再報錯了,接下來的事情就順利成章了
# douyin_t.py
import json, os
import requests
def response(flow):
url = 'https://api.amemv.com/aweme/v1/aweme/post/'
# 篩選出以上面url為開頭的url
if flow.request.url.startswith(url):
text = flow.response.text
# 將已編碼的json字串解碼為python物件
data = json.loads(text)
# print(data)
# 在fiddler中剛剛看到每一個視訊的所有資訊
# 都在aweme_list中
video_url = data['aweme_list']
path = 'E:/爬蟲資料/douyin'
if not os.path.exists(path):
os.mkdir(path)
for each in video_url:
# 視訊描述
desc = each['desc']
url = each['video']['play_addr']['url_list'][0]
# print(desc,url)
filename = path + '/' + desc + '.mp4'
# print(filename)
req = requests.get(url=url, verify=False)
with open(filename, 'ab') as f:
f.write(req.content)
f.flush()
print(filename, '下載完畢')
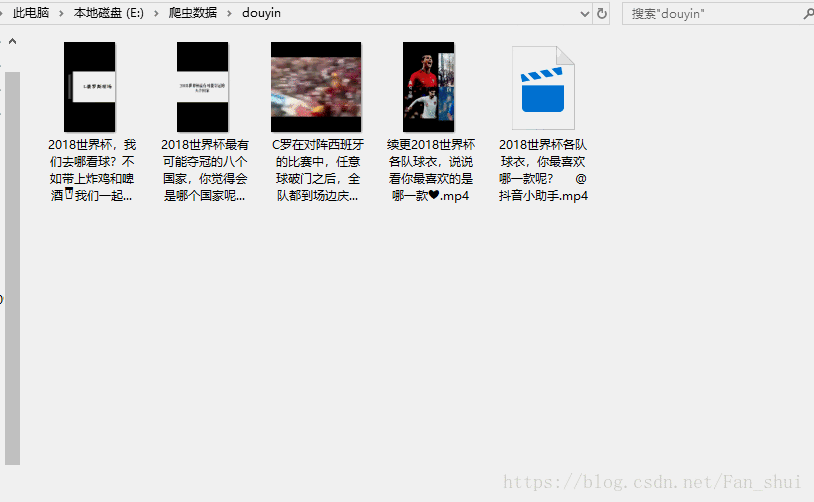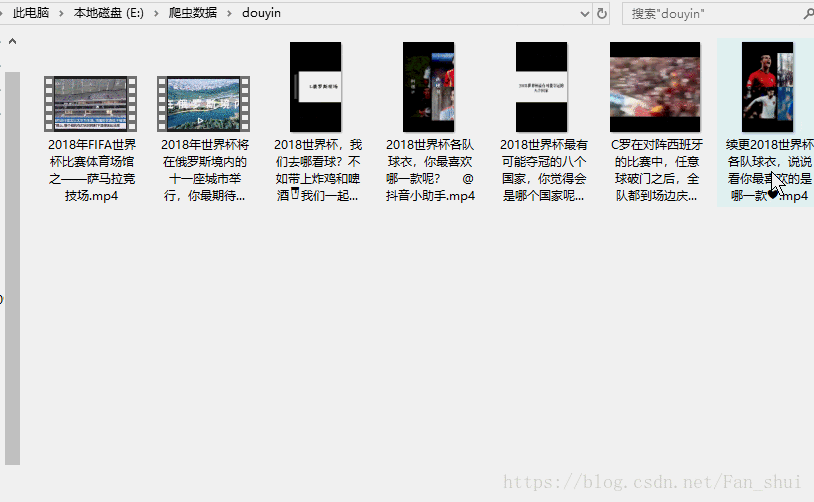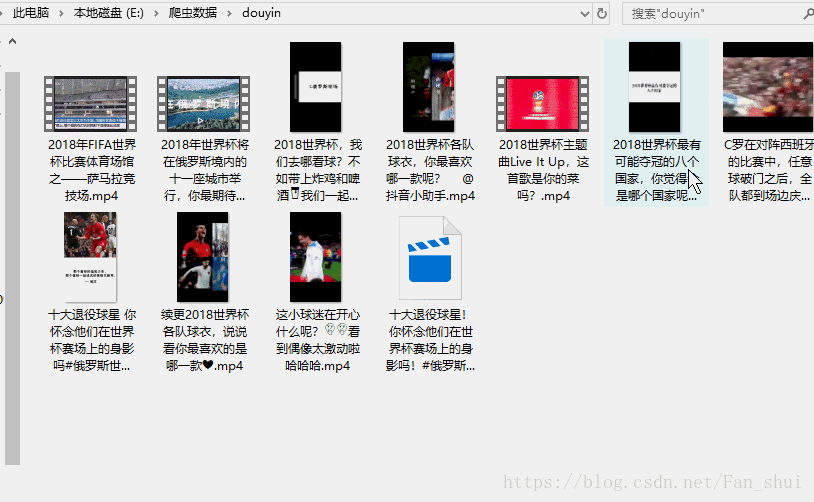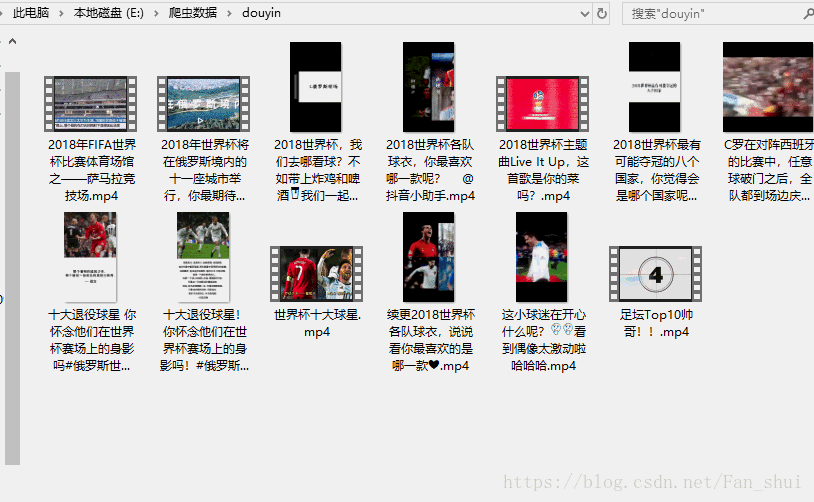
這個只要我們沒有關閉mitmdump執行視窗,我們可以搜尋其他的抖音使用者的頁面,也會被下載下來,不知道大家是更喜歡appium自動化,還是喜歡自己用手滑,嘿嘿嘿嘿
若針對requests匯入錯誤有更好的建議,歡迎分享(●ˇ∀ˇ●)