
python爬蟲(一)---智聯招聘實戰
阿新 • • 發佈:2018-12-09
智聯校園招聘資料爬取
1 本次實驗只爬取一頁內容,適合入門學習xpath,excel檔案寫入。
2 url =‘https://xiaoyuan.zhaopin.com/full/538/0_0_160000_1_0_0_0_1_0’
3 結尾會附上全部程式碼
大神請繞過本部落格
(一) xpath基礎知識
含義:xpath可以用在xml文件中對元素和屬性值進行遍歷,在網路爬蟲中,只用xpath採集資料。
xpath有7種類型的節點:元素,屬性,文字,名稱空間,處理指令,詮釋,文件節點
- 路徑表示式
| 表示式 | 含義 |
|---|---|
| nodeName | 選取此節點的所有子節點 |
| / | 從根節點選取 |
| // | 從匹配選擇的當前節點選擇文件節點,不考慮它們位置 |
| . | 選取當前節點 |
| … | 選取當前節點的父節點 |
| @ | 選取屬性 |
| * | 匹配任何元素節點 |
| @* | 匹配任何屬性節點 |
| Node() | 匹配任何型別節點 |
- 用xpath練習
<div class="searchResultList clearfix">
<ul class="searchResultListUl">
<li>
<div class="searchResultItemDetailed" pid="CC000130700J90000003000" datecreated="12/4/2018 1:12:00 AM" companytype="國企">
< 針對上面html原始碼訓練如下:
#匯入lxml中的etree模組
#lxml能將字串或流轉化成ElementTree型別,也能將ElementsTree--> str
from lxml import etree
text = '''上面的html程式碼複製在這'''
#利用etree.HTML將字串解析成HTML文件的elementstree型別
html = etree.HTML(text)
#例如:提取公司型別
# 1 首先看公司型別在哪(所屬標籤) 如上HTML程式碼是span標籤 #<span class="searchResultKeyval" >
# 2 發現不止有公司型別是這個標籤,還有公司規模,所屬行業點等,此時就要進行步驟3
# 3 再找此內容所在標籤的父節點即如上程式碼中span的父節點是 <p class="searchResultCompanyInfodetailed">
# 4 根據索引取得所要得到的公司型別
# 程式碼解釋:
#//:如上表格所說從當前節點選取,不考慮位置,即p節點開始
#[@class=" "]:指定當前p標籤的class
#text() :選取節點內容
companies = html.xpath('//p[@class="searchResultCompanyInfodetailed"]/span[@class="searchResultKeyval"][1]/span/em/text()')
#同理可以選取別的值,按需進行即可
(二)完整程式碼
import requests
import xlwt
from lxml import etree
#不加次header會拒絕訪問,這是偽造頭資訊,去訪問網頁
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
url = 'https://xiaoyuan.zhaopin.com/full/538/0_0_160000_1_0_0_0_1_0'
re = requests.get(url,headers=header)
#print(re.text)
#re和re.text型別不一樣。etree.HTML只能解析str型別
#print(type(re.text))
#print(type(re))
html = etree.HTML(re.text)
print(type(html))
#---------------------解析網頁,提取城市,職位,人數,公司型別,釋出時間-----------
items = []
#找城市
cities = html.xpath('//p[@class="searchResultJobAdrNum"]/span[@class="searchResultKeyval"][1]/span/em/text()')
items.append(cities)
#釋出時間
times = html.xpath('//p[@class="searchResultJobAdrNum"]/span[@class="searchResultKeyval"][2]/span/em/text()')
items.append(times)
#工作,選擇p標籤下的span內容,但是span的class都是一樣的名字,只能用下標索引所要抽取的職位型別的em中的值
jobs = html.xpath('//p[@class="searchResultCompanyInfodetailed"]/span[@class="searchResultKeyval"][4]/span/em/text()')
items.append(jobs)
#招聘人數
numbers = html.xpath('//p[@class="searchResultCompanyInfodetailed"]/span[@class="searchResultKeyval"][5]/span/em/text()')
items.append(numbers)
#公司類別
companies = html.xpath('//p[@class="searchResultCompanyInfodetailed"]/span[@class="searchResultKeyval"][1]/span/em/text()')
items.append(companies)
#職位描述
description = html.xpath('//p[@class="searchResultJobdescription"]/span/text()')
items.append(description)
#-------------------------------------建立檔案---------------------------------
#檔名稱
newFile = "ZhiLian.xls"
#建立excel 檔案 ,宣告編碼為utf-8
wb = xlwt.Workbook(encoding='utf-8')
#建立表格
ws = wb.add_sheet('sheet1')
#表頭資訊
headData = ['城市','職位','公司型別','招聘人數','釋出時間','職責描述']
#寫入表頭資訊
for column in range(0,6):
ws.write(0,column,headData[column],xlwt.easyxf('font:bold on'))
#將所獲得的資訊新增到excel檔案中
# -----------------------------寫入檔案---------------------------------------
#將爬取的資訊寫入excel中 按列儲存
for i in range(0,len(items)):
for j in range(1,len(items[i])):
ws.write(j,i,items[i][j])
wb.save(newFile)
輸出內容:
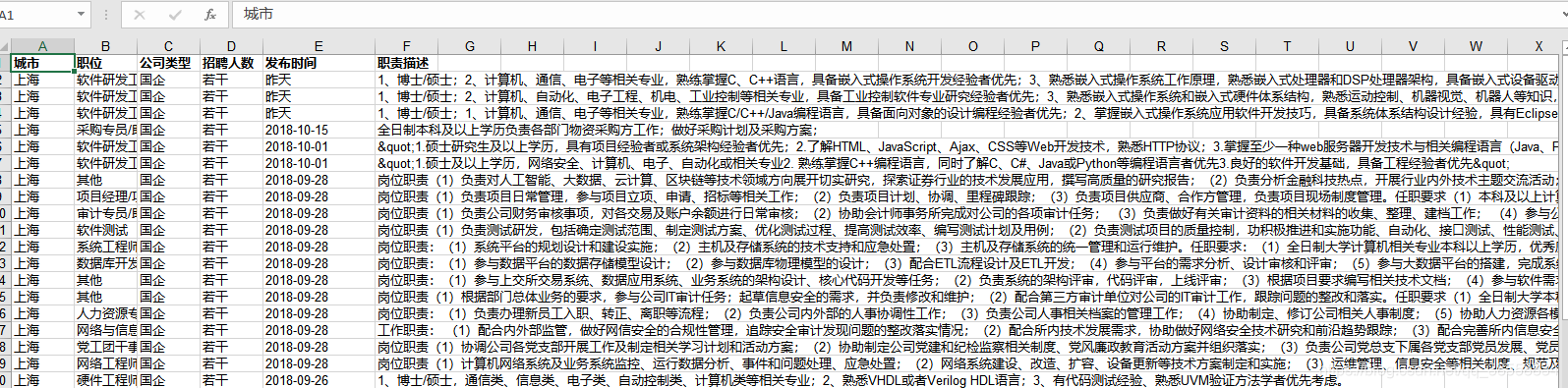
(三)總結:
本文主要將xpath的方式解析網頁,因為本人今天才真正正式學習爬蟲,程式碼比較臃腫,還有那個items.append新增內容有點繁瑣,後期我繼續努力,看看有沒有好的方法,本人下篇部落格將爬取多個網頁,並將程式碼進行封裝。不會顯得零散,可讀性比較差。
(四)致謝:
感謝如下部落格提供的參考:
https://blog.csdn.net/u011486491/article/details/84061432
https://blog.csdn.net/u010187278/article/details/77847737?locationNum=10&fps=1#網頁分析