Python爬蟲(一)--城市公交網路站點資料的爬取
阿新 • • 發佈:2019-02-15
作者:WenWu_Both
出處:http://blog.csdn.net/wenwu_both/article/
版權:本文版權歸作者和CSDN部落格共有
轉載:歡迎轉載,但未經作者同意,必須保留此段聲 必須在文章中給出原文連結;否則必究法律責任
(1)環境配置,直接上程式碼:
# -*- coding: utf-8 -*-
import requests ##匯入requests
from bs4 import BeautifulSoup ##匯入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' (2)爬取站點分析
1、北京市公交線路分類方式有3種:

本文通過數字開頭來進行爬取,“F12”啟動開發者工具,點選“Elements”,點選“1”,可以發現連結儲存在<div class="bus_kt_r1">
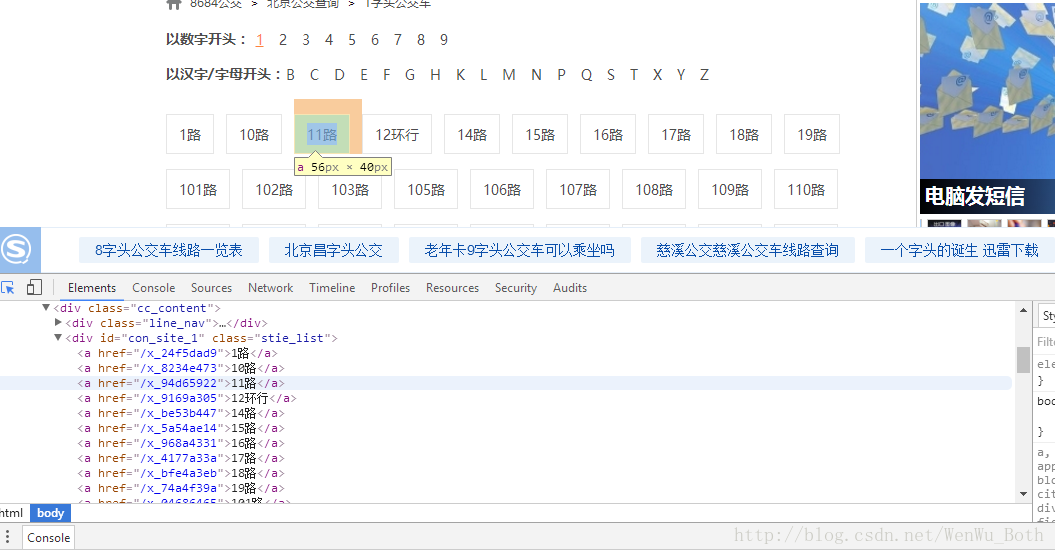
程式碼:
all_a = Soup.find(‘div’,class_=’bus_kt_r1’).find_all(‘a’)
2、接著往下,發現每1路的連結都在<div id="con_site_1" class="site_list"> 的
<a>裡面,取出裡面的herf即為線路網址,其內容即為線路名稱,程式碼:
href = a['href'] #取出a標籤的href 屬性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text) 3、開啟線路連結,就可以看到具體的站點資訊了,開啟頁面分析文件結構後發現:線路的基本資訊存放在<div class="bus_i_content">裡面,而公交站點資訊則存放在<div class="bus_line_top">及<div class="bus_line_site">裡面,提取程式碼:
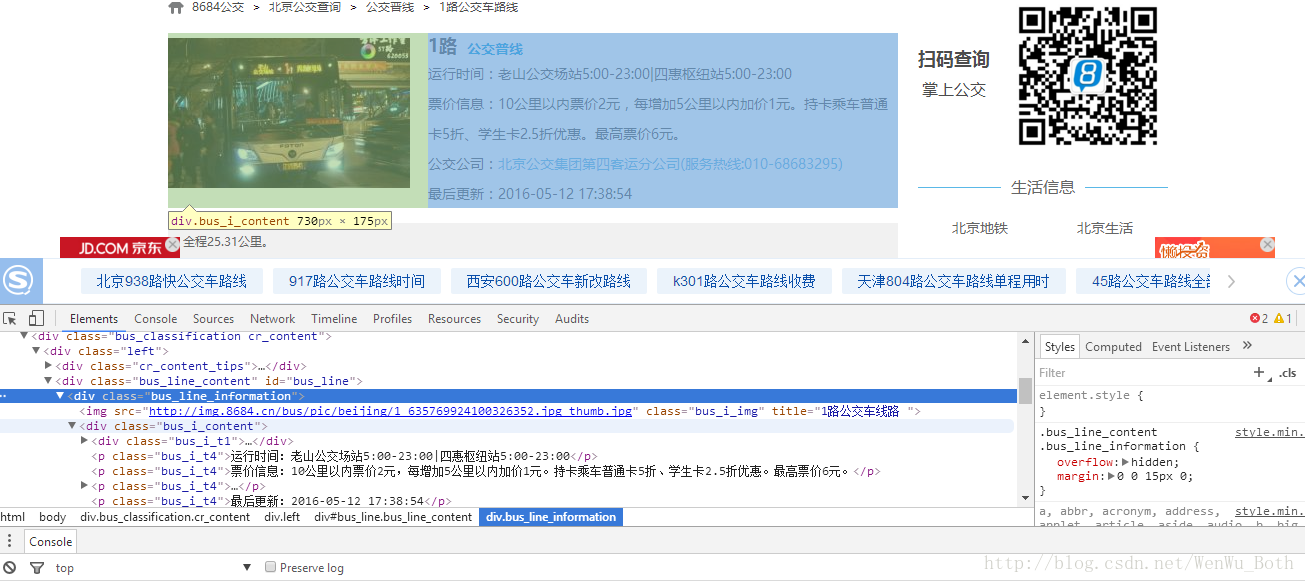
title1 = a2.get_text() #取出a1標籤的文字
href1 = a2['href'] #取出a標籤的href 屬性
#print (title1,href1)
html_bus = all_url + href1 # 構建線路站點url
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text() # 提取線路名
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text() # 提取線路屬性
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text() # 執行時間
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text() # 票價
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text() # 更新時間
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 線路里程
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top') # 線路簡介
all_site = Soup3.find_all('div',class_='bus_line_site')# 公交站點
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行線路站點
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在環線,也返回兩個list,只是其中一個為空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行線路站點
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
自此,我們就把一條線路的相關資訊及上、下行站點資訊就都解析出來了。如果想要爬取全市的公交網路站點,只需要加入迴圈就可以了。
完整程式碼:
# -*- coding: utf-8 -*-
# Python3.5
import requests ##匯入requests
from bs4 import BeautifulSoup ##匯入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://beijing.8684.cn' ##開始的URL地址
start_html = requests.get(all_url, headers=headers)
#print (start_html.text)
Soup = BeautifulSoup(start_html.text, 'lxml')
all_a = Soup.find('div',class_='bus_kt_r1').find_all('a')
Network_list = []
for a in all_a:
href = a['href'] #取出a標籤的href 屬性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道為啥取不出來,只好迂迴取了
for a2 in all_a2:
title1 = a2.get_text() #取出a1標籤的文字
href1 = a2['href'] #取出a標籤的href 屬性
#print (title1,href1)
html_bus = all_url + href1
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text()
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text()
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text()
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text()
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text()
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text()
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text()
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top')
all_site = Soup3.find_all('div',class_='bus_line_site')
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = []
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在環線,也返回兩個list,只是其中一個為空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = []
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
Network_list.append(information)
# 定義儲存函式,將運算結果儲存為txt檔案
def text_save(content,filename,mode='a'):
# Try to save a list variable in txt file.
file = open(filename,mode)
for i in range(len(content)):
file.write(str(content[i])+'\n')
file.close()
# 輸出處理後的資料
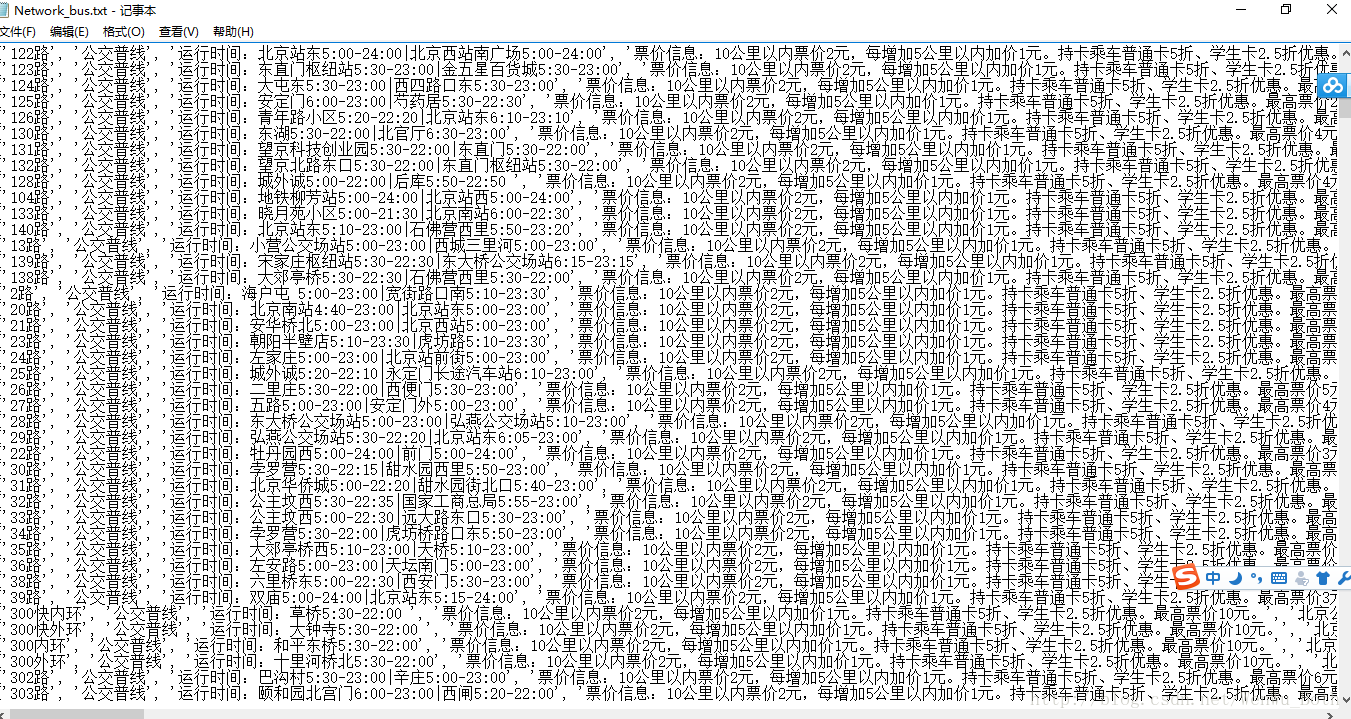
text_save(Network_list,'Network_bus.txt'); 最後輸出整個城市的公交網路站點資訊,這次就先儲存在txt檔案裡吧,也可以儲存到資料庫裡,比如mysql或者MongoDB裡,這裡我就不寫了,有興趣的可以試一下,附上程式執行後的結果圖: