
R語言開發之資料型別之陣列&因子&資料幀
阿新 • • 發佈:2018-12-09
咱們接著上篇文章來啊,上篇文章最後說道矩陣,但是矩陣只能有兩個維度,然而陣列可以是任意數量的維數。R語言中陣列函式採用一個dim屬性,建立所需的維數。 在下面的例子中,我們嘗試建立一個有三個元素的陣列,每個元素都是3x3個矩陣:
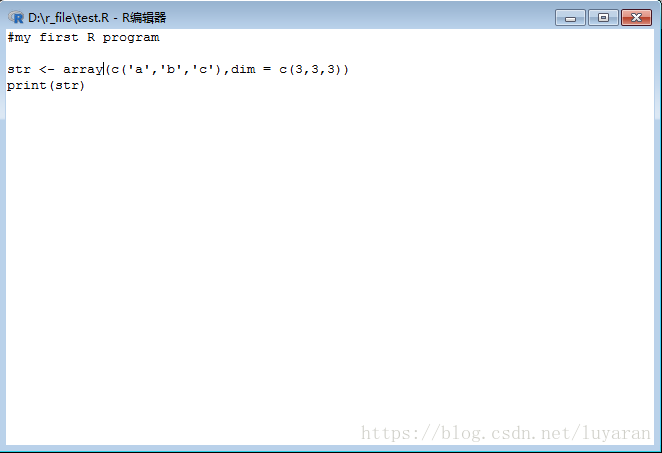
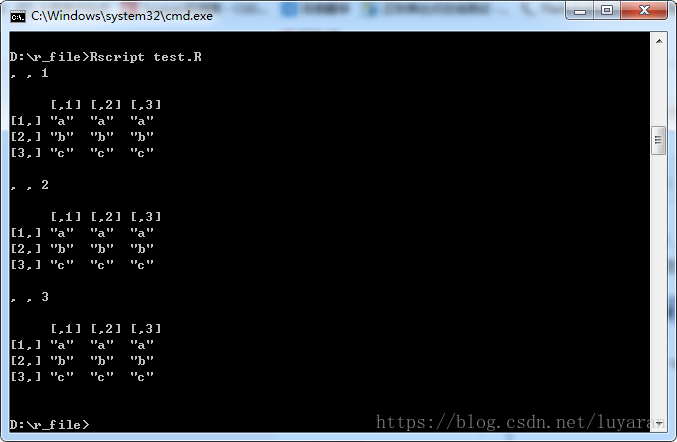
執行結果如下:
然後因子是使用向量建立的R物件, 它將向量儲存在向量中的元素的不同值作為標籤,並且標籤始終是字元,無論它是輸入向量中是數字,還是字元或布林等,這讓它們在統計建模中很有用,其中因子使用factor()函式建立,之後又nlevels函式給出了級別的計數,來看下例項:
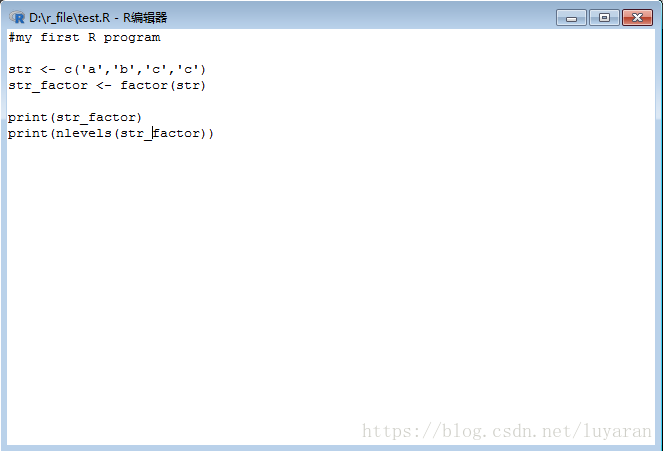
執行結果如下:

資料幀是表格資料物件,它與陣列中的矩陣不同,每列可以包含不同的資料模式。 第一列是數字,而第二列可以是字元,第三列可以是邏輯型別。它是一個長度相等的向量列表。它使用data.frame()
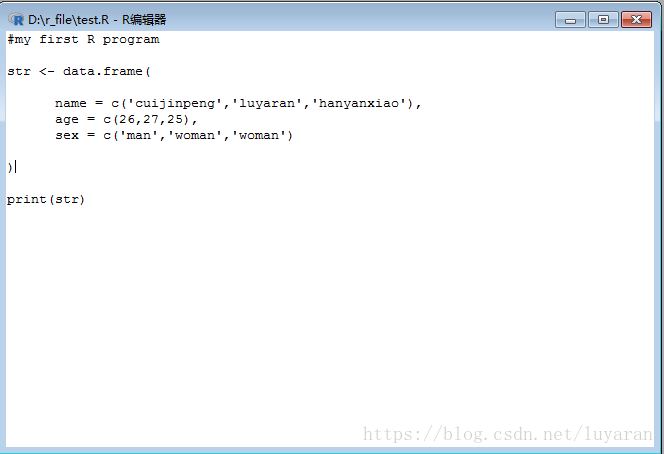
輸出結果如下:

好啦,本次記錄就到這裡了。
如果感覺不錯的話,請多多點贊支援哦。。。