
R語言開發之平均值,中位數和眾數了解下
R中的統計分析通過使用許多內建函式來執行的,這些函式大部分是R基礎包的一部分,並且它們將R向量與引數一起作為輸入,並在執行計算後給出結果。
先來看如何求平均值。
平均值是通過取數值的總和併除以資料序列中的值的數量來計算,函式mean()用於在R中計算平均值,語法如下:
mean(x, trim = 0, na.rm = FALSE, ...)引數描述如下:
- x - 是輸入向量。
- trim - 用於從排序的向量的兩端刪除一些觀測值。
- na.rm - 用於從輸入向量中刪除缺少的值。
當我們提供trim引數時,向量中的值進行排序,然後從計算平均值中刪除所需數量的觀察值,例如,當trim = 0.3
3個值將從計算中刪除以找到均值。在這種情況下,排序的向量為(-21,-5,2,3,42,7,8,12,18,54),從用於計算平均值的向量中從左邊刪除:(-21,-5,2)和從右邊刪除:(12,18,54)這幾個值。
如果缺少值,則平均函式返回NA,我們如果要從計算中刪除缺少的值,可以使用na.rm = TRUE, 這意味著刪除NA值。
好啦,來綜合看下例項:
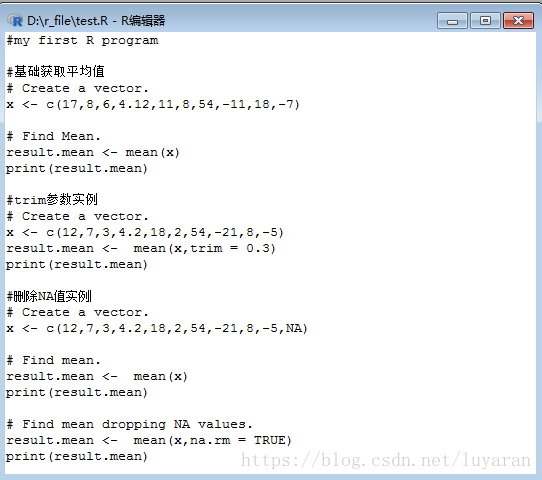
輸出結果為:
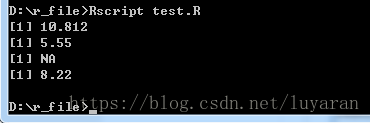
資料系列中的中間值被稱為中位數,在R中使用median()函式來計算中位數,語法如下:
median(x, na.rm = FALSE)引數描述如下:
- x - 是輸入向量。
- na.rm- 用於從輸入向量中刪除缺少的值。
眾數是指給定的一組資料集合中出現次數最多的值,不同於平均值和中位數,眾數可以同時具有數字和字元資料。R沒有標準的內建函式來計算眾數,因此,我們將建立一個使用者自定義函式來計算R中的資料集的眾數。該函式將向量作為輸入,並將眾數值作為輸出,來分別看下例項:
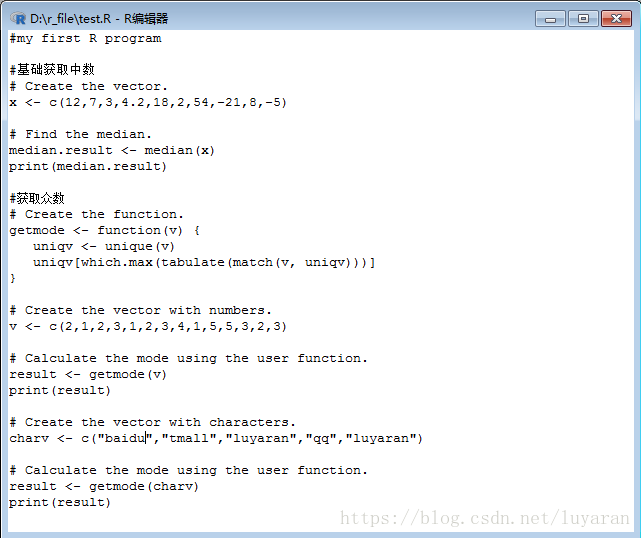
輸出結果為:
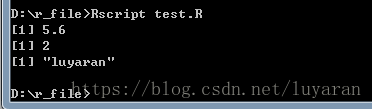
好啦,本次記錄就到這裡了。
如果感覺不錯的話,請多多點贊支援哦。。。
相關推薦
R語言開發之平均值,中位數和眾數了解下
R中的統計分析通過使用許多內建函式來執行的,這些函式大部分是R基礎包的一部分,並且它們將R向量與引數一起作為輸入,並在執行計算後給出結果。 先來看如何求平均值。 平均值是通過取數值的總和併除以資料序列中的值的數量來計算,函式mean()用於在R中計算平均值,語法如下:
算數-平均數、中位數和眾數平均數
平均數、中位數和眾數平均數 flyfish 2015-11-10 筆記 平均數(average,arithmetic mean):若干個數的平均數,是用這些數的和除以數的個數。 中位數(median):一列數按大小順序排列後,處於中間的那個數。如果這列數有
計算一個list中資料的平均數、中位數和眾數【python實現】
一個數列的平均數的定義為,所有數值求和再除以數列長度 中位數定義為,將一個數列排序後位於中間的數值(數列長度為奇數時,取正中間的數,長度為偶數時,去中間的兩個數的平均) 眾數定義為,在一個數列中,出
R語言開發之資料型別之陣列&因子&資料幀
咱們接著上篇文章來啊,上篇文章最後說道矩陣,但是矩陣只能有兩個維度,然而陣列可以是任意數量的維數。R語言中陣列函式採用一個dim屬性,建立所需的維數。 在下面的例子中,我們嘗試建立一個有三個元素的陣列,
R語言開發之迴圈結構的控制語句(break&next)瞭解下
迴圈控制語句用於更改程式正常執行順序,就是當執行離開範圍時,在該範圍內建立的所有自動物件都將被銷燬。我們來看下R支援的控制語句: 序號 控制語句 描述 1 break語句 終止迴圈語句並將執行轉移到迴圈之後的語句。 2 next語句
R語言開發之陣列操作了解下
陣列是可以在二維及以上儲存資料的R資料物件, 例如 - 如果建立一個維陣列(2,3,4),那麼它將建立4個矩形矩陣,每個矩陣具有2行和3列並且陣列只能儲存資料型別。我們可通過使用array()函式來建立
R語言開發之包是個什麼鬼???
R包是R函式,編碼和樣本資料的集合, 它們儲存在R環境中的名為“library”的目錄下。 預設情況下,R在安裝過程中安裝一組軟體包。當需要某些特定的目的時,也可根據需要新增更多的包。 當我們啟動R控制檯時,預設情況下只有預設軟體包可用。 已經安裝的其他軟體包必須明確載入才能
R語言開發之CSV檔案的讀寫操作了解下
在R中,我們可以從儲存在R環境外部的檔案讀取資料,還可以將資料寫入由作業系統儲存和訪問的檔案。這個csv檔案應該存在於當前工作目錄中,以方便R可以讀取它, 當然,也可以設定自己的目錄,並從那裡讀取檔案。
R語言開發之輸出直方圖
直方圖表示一個變數範圍內的值的頻率。直方圖類似於條形,但區別在於將值分組為連續範圍。直方圖中的每個欄表示該範圍中存在的值的數量的高度。在R中使用hist()函式建立直方圖。 該函式將一個向量作為輸入,並
R語言開發之二進位制檔案讀寫操作
二進位制檔案是一個檔案,其中包含僅以位和位元組形式儲存的資訊(0和1),它們是不可讀的,因為其中的位元組轉換為包含許多其他不可列印字元的字元和符號,隨便我們嘗試使用任何文字編輯器讀取二進位制檔案將顯示為類似Ø和ð這樣的字元。 但是二進位制檔案必須由特定程式讀取才能使用。例如
R語言開發之線性迴歸瞭解下
迴歸分析是一個廣泛使用的統計工具,用於建立兩個變數之間的關係模型,這些變數之一稱為預測變數,其值通過實驗收集。 另一個變數稱為響應變數,其值來自預測變數。線上性迴歸中,這兩個變數通過一個等式相關聯,其中這兩個變數的指數(冪)是1,數學上,當繪製為圖形時,線性關係表示直線,並且
R語言開發之協方差分析瞭解下
我們通常使用迴歸分析來建立描述預測變數變數對響應變數的影響的模型,有時,如果我們有類似於是/否或男/女等值的分類變數,簡單迴歸分析為分類變數的每個值提供多個結果。在這種情況下,我們可以通過使用分類變數和預測變數來研究分類變數的影響,並比較分類變數的每個級別的迴歸線。 這樣的分
R語言開發之非線性最小二乘法瞭解下
當對真實世界資料建模進行迴歸分析時,我們觀察到模型的方程很少是給出線性圖的線性方程。 反而是在大多數情況下,現實世界資料模型的方程式涉及更高程度的數學函式,如3或sin函式的指數。 在這種情況下,模型的曲線給出了曲線而不是線性。線性和非線性迴歸的目標是調整模型引數的值以找到最
R語言開發之矩陣操作了解下
矩陣是其中元素以二維矩形佈局排列的R物件,它們包含相同原子型別的元素。 雖然我們可以建立一個僅包含字元或僅包含邏輯值的矩陣,但它們沒有太多用處,我們通常使用包含數學元素的矩陣來在數學計算中使用,並且通過使用matrix()函式來建立矩陣。基本語法如下: matrix(dat
R語言開發之二項分佈瞭解下
二項分佈模型用來處理在一系列實驗中只發現兩個可能結果的事件的成功概率,例如,擲硬幣總是兩種結果:正面或反面。我們可以使用二項式分佈估算在重複拋擲硬幣10次時正好準確地找到3次是正面的概率。在R中具有四個內建函式來生成二項分佈,如下: dbinom(x, size, prob
R語言開發之決策樹瞭解下
決策樹是以樹的形式表示選擇及其結果的圖形,圖中的節點表示事件或選擇,並且圖形的邊緣表示決策規則或條件。 它主要用於使用R的機器學習和資料探勘應用程式。 使用決策的例子我們可以看下。 將接收的郵件預測是否為垃圾郵件,根據這些資訊中的因素,預測腫瘤是癌症或預測貸款作為良好或
R語言開發之字串操作基礎瞭解下
在R中的單引號或雙引號中寫入的任何值都將被視為字串,並且在R內部將每個字串儲存在雙引號內,即使我們是使用單引號建立它們。來看下字串構造的規則: 字串開頭和結尾的引號應為雙引號或雙引號,他們不能混合。 雙引號可以插入到以單引號開始和結尾的字串中。 單引號可以插入到以雙引號
【Python】不用numpy用純python求極差、平均數、中位數、眾數與方差,python的列印到控制檯
原文連結:https://blog.csdn.net/yongh701/article/details/50150619 python作為資料分析的利器,求極差、平均數、中位數、眾數與方差是很常用的,然而,在python進行統計往往要使用外部的python庫numpy,這個庫不難裝,然而,如果單
【C++程式設計練習】任意給定 n 個有序整數,求這 n 個有序整數序列的最大值,中位數和最小值
題目來源 CCF模擬試題>>小中大>>201903-1 題目描述 老師給了你n個整陣列成的測量資
Numpy求均值、中位數、眾數的方法
首先需要資料來源,這裡隨便寫了一個: nums = [1,2,3,4] 求均值和中位數均可以使用numpy庫的方法: import numpy as np #均值 np.mean(nums) #中位數 np.median(nums) 求眾數方法一: 在numpy中沒有直接的方法