
天池:零樣本目標識別新手筆記2
阿新 • • 發佈:2018-12-09
所用思路和上一個差不多,本篇基於天池論壇的這篇文章:Keras多分類聯合訓練+歐式距離遷移對映 ,並做了自己的處理。線上精度0.0905。
- 沒有構造如
'non_1'的特徵,直接使用如原來的全0特徵表示,並對每類特徵除和 - 使用的vgg16
處理後的特徵檔案如下:
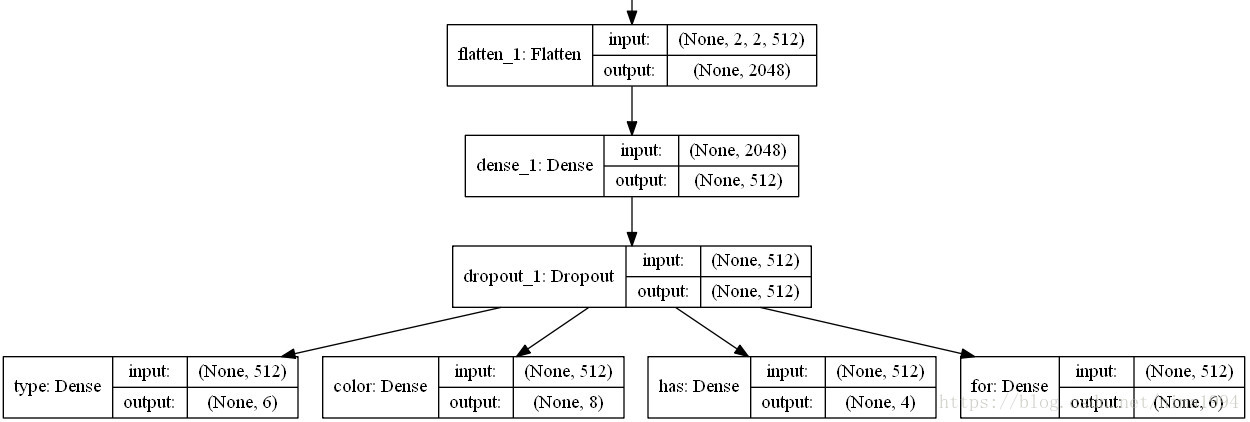
模型的關鍵之處在於:
該部分主要程式碼如下:
def normalline(data):
for i,cs in enumerate(np.sum(data,axis=1).values):
if cs!=0:
data.iloc[i,:]=data.iloc[i,:]*1.0 可以從如下思路改進:
- 目前基於vgg16模型,不符合賽題要求,而且賽題圖片是64x64的,模型提取圖片特徵的能力也有限。所以可以構建更復雜的單網路,進而做圖片特徵的merge等,從而提取更好的圖片特徵
- 在圖片特徵提取這一環,做圖片的訓練集和驗證集,似乎驗證集的結果並不好,如果打標籤質量不好,是否可以考慮課程學習
- 樣本屬性的不同的預處理(歸一化、標準化),或者如文中的分批
- 多種對映方式組合,文中僅僅基於神經網路,可以考慮將圖片特徵、屬性特徵提出從而構建不同的對映