
爬山演算法 x 模擬退火
阿新 • • 發佈:2018-12-09
爬山演算法(Hill Climbing)
學習模擬退火前瞭解爬山演算法是非常必要的
爬山演算法依照一個很簡單的貪心思路 每次在當前作為最優解的點附近隨機一個新的點 比較這個新的點是否比當前更優,若是則更新
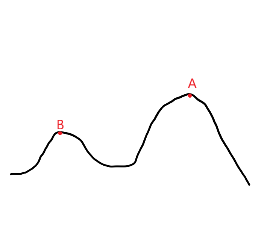
這個演算法有一個比較明顯的缺點,例如下圖
我們想要的最終答案是A 但若當前記錄的最優解是B 區域性最優解B附近谷底的點又顯然不能作為更優解更新答案
所以爬山演算法最終得到的將有可能只是區域性最優解
模擬退火(SA——Simulated Annealing)
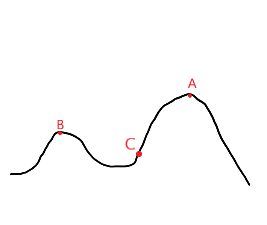
為了解決上述爬山演算法的不足 模擬退火演算法應用了以一定概率接受一個非更優解的思路
加入當前記錄的最優解為B 隨機到的下一個點為C 爬山演算法直接否定了這個點,但模擬退火決定以一定概率去接受
關於如何確定接受概率,就應用到了金屬退火原理
在溫度為的情況下 出現一次能量差為的降溫的概率為
這個要如何應用到OI中呢 我們設定一個初始溫度和最小溫度,以及降溫係數 每次降溫就是令 當溫度下降到時演算法結束
假設在溫度時記錄的最優解為 隨機一個附近的點並計算他的函式值 他們的差作為退火的能量差,即 若,說明這個新的點更優,直接更新 若,我們就以的概率接受這個非更優解
因為,所以的取值範圍是 顯然溫度越小,接受的概率也越小
爬山演算法:兔子朝著比現在高的地方跳去。它找到了不遠處的最高山峰。但是這座山不一定是珠穆朗瑪峰。這就是爬山演算法,它不能保證區域性最優值就是全域性最優值。
模擬退火:兔子喝醉了。它隨機地跳了很長時間。這期間,它可能走向高處,也可能踏入平地。但是,它漸漸清醒了並朝最高方向跳去。這就是模擬退火。
下面給出模擬退火虛擬碼
/*
F(x)在狀態x時的評價函式值
x , nx 當前狀態 與 新的狀態
delta: 用於控制降溫的快慢
T: 系統的溫度,系統初始應該要處於一個高溫的狀態
T_0 , T_min :初始溫度 與 溫度的下限,當溫度T從T_0降溫到T_min,演算法結束
*/
T=T_0
while(T>T_min)
{
nx=RADN(x);//在當前狀態x附近隨機一個新的狀態
dE=F(nx)-F(x); //能量差
if(dE>=0) x=nx;//直接接受更優的移動
else if( exp( dE/T ) > random(0,1) ) x=nx;//以一定概率接受非更優的移動
//(exp是c++庫函式) exp( dE/T )隨溫度降低而減小
T=T*delta; //降溫退火 ,0<delta<1
//delta越大,降溫越慢, 反之delta越小,降溫越快
//若delta過大,則搜尋到全域性最優解的可能會較高,但搜尋的過程也就較長。
//若delta過小,則搜尋的過程會很快,但最終可能會達到一個區域性最優值
}爬山演算法與模擬退火的應用
求函式在0 <= x <=100內的最小值
持續更新…