
LSTM 實際神經元隱含層物理架構原理解析
最近看一些基於LSTM網路的NLP案例程式碼,其中涉及到一些input_size, num_hidden等變數的時候,可能容易搞混,首先是參照了知乎上的一個有關LSTM網路的回答https://www.zhihu.com/question/41949741, 以及github上對於LSTM比較清晰的推導公式http://arunmallya.github.io/writeups/nn/lstm/index.html#/3, 對於lstm cell中各個門處理,以及隱含層的實際物理實現有了更深刻的認識,前期一些理解上還模糊的點 也在不斷的分析中逐漸清晰。
首先給出LSTM網路的三種不同的架構圖:
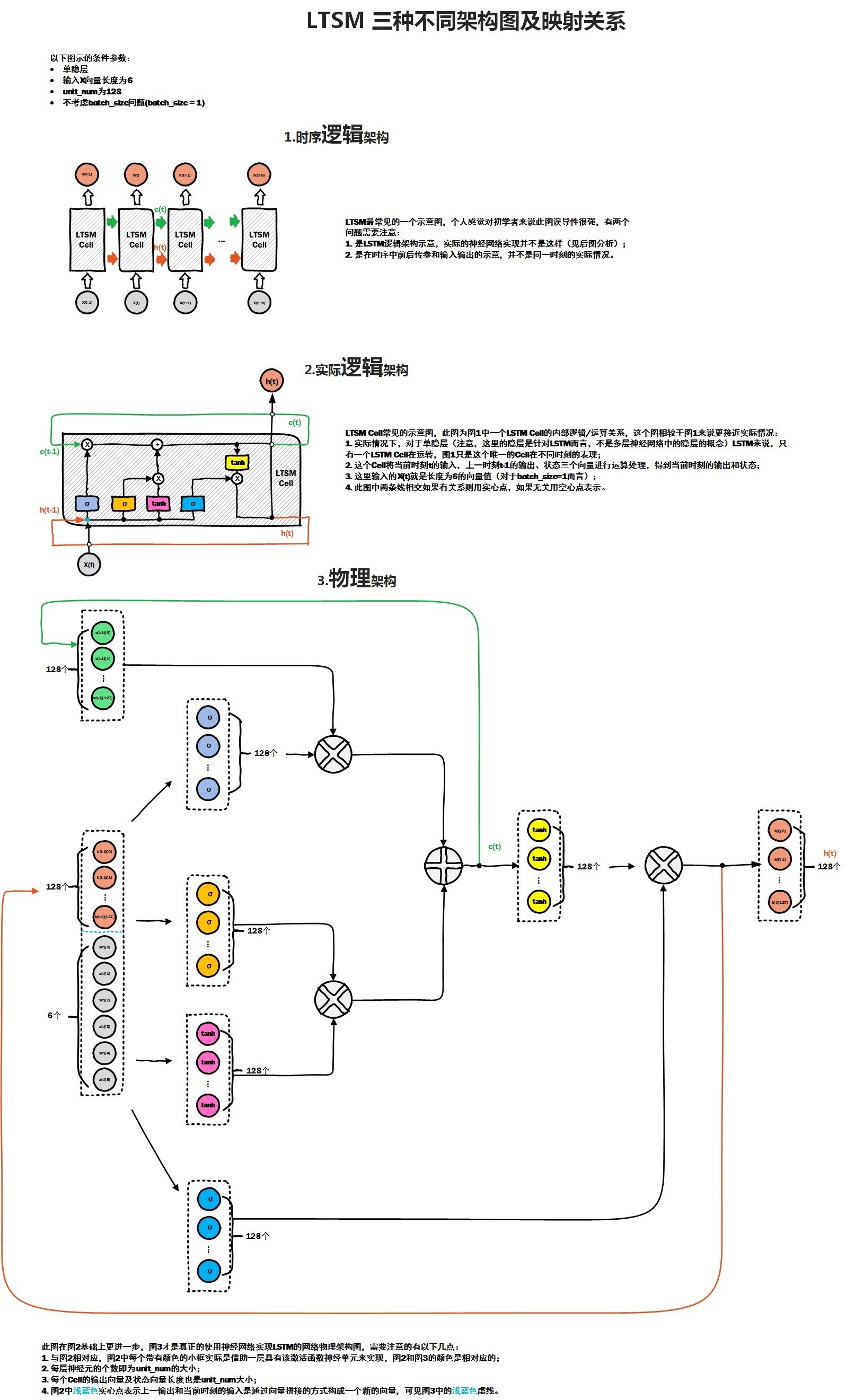
其中前兩種是網上最常見的,圖二相對圖一,進一步解釋了cell內各個門的作用,但是在實際的神經網路中,各個門處理函式 其實是由一定數量的隱含層神經元來處理,在RNN中,M個神經元組成的隱含層,實際的功能應該是f(wx + b), 這裡實現了兩部,首先M個隱含層神經元與輸入向量X之間全連線,通過w引數矩陣對x向量進行加權求和,其實就是對x向量各個維度上進行篩選,加上bias偏置矩陣後,通過f激勵函式, 得到隱含層的輸出。而在LSTM Cell中,一個cell 包含了若干個門處理函式,假如每個門的物理實現,我們都可以看做是由num_hidden個神經元來實現該門函式功能, 那麼每個門各自都包含了相應的w引數矩陣以及bias偏置矩陣引數,就是在圖3物理架構圖中的實現。從圖3中可以看出,cell單元裡有四個門,每個門都對應128個隱含層神經元,相當於四個隱含層,每個隱含層各自與輸入x 全連線,而輸入x向量是由兩部分組成,一部分是上一時刻cell 輸出,大小為128, 還有部分就是當前樣本向量的輸入,大小為6,因此通過該cell內部計算後,最終得到當前時刻的輸出,大小為128,即num_hidden,作為下一時刻cell的一部分輸入。比如在NLP場景下,當一個詞向量維度為M時, 可以認為當前x維度為M,如果num_hidden = N, 那麼與x全連線的某個隱含層神經元的w矩陣大小為 M * N, bias的維度為N, 所以平時我們在初始化lstm cell的時候,樣本輸入的embedding_size 與 num_hidden 之間沒有直接關聯,而是會決定每個門的w矩陣維度, 而且之前的一片BasicLSTMCell 原始碼分析中,我們提到了BasicLSTMCell 是直接要求embedding_size 與 num_hidden 是相等的,這也大大簡化了多個w矩陣的計算,這也說明了BasicLSTMCell是最簡單和最常用的一種lstm cell
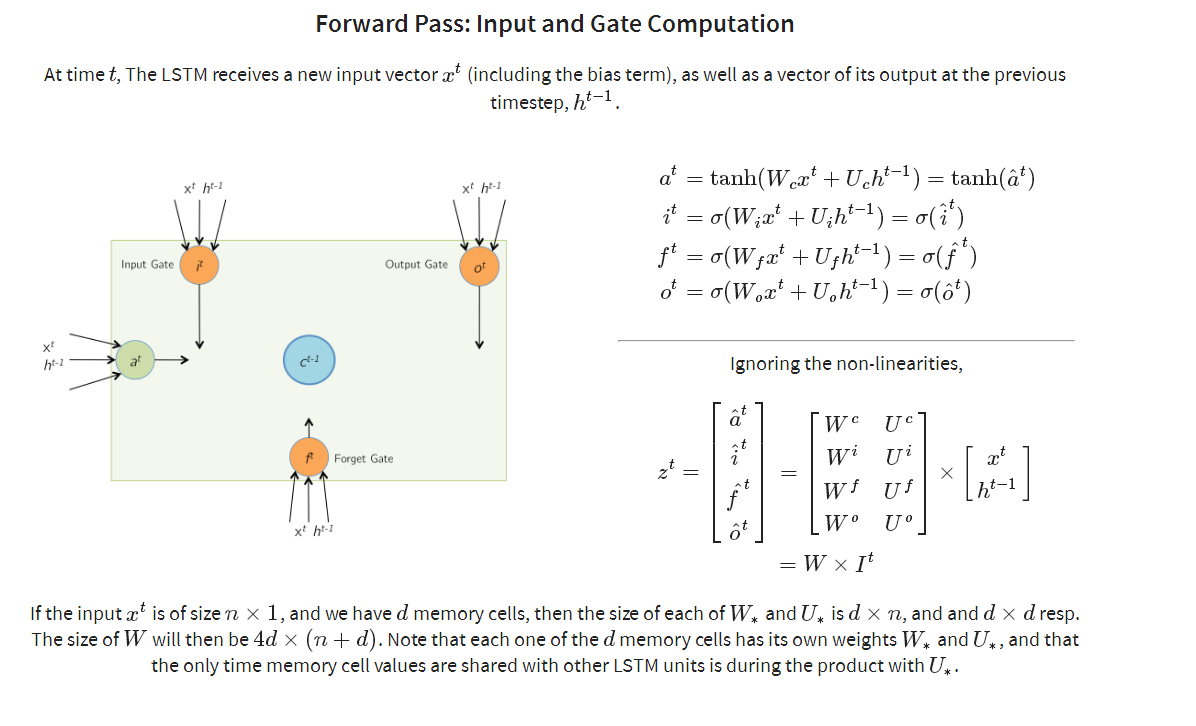
從上圖中可以看出,每個門都對應一個w 以及bias矩陣
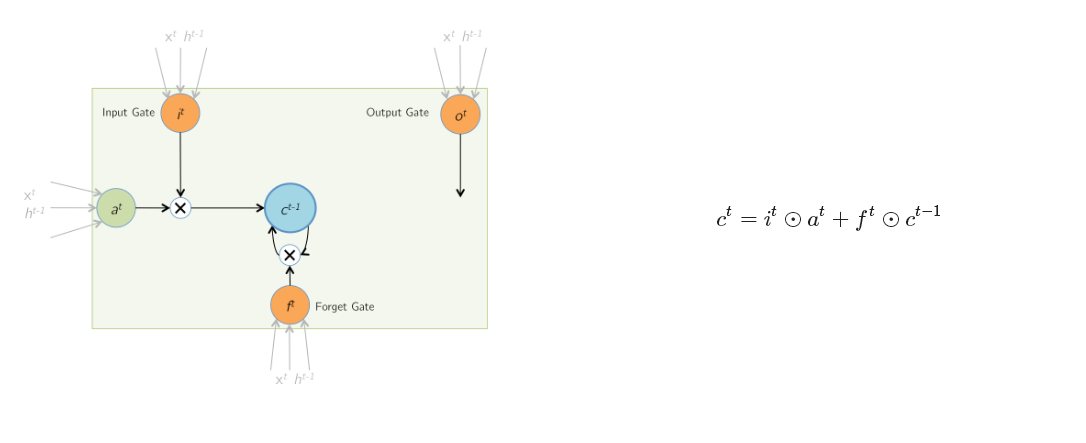
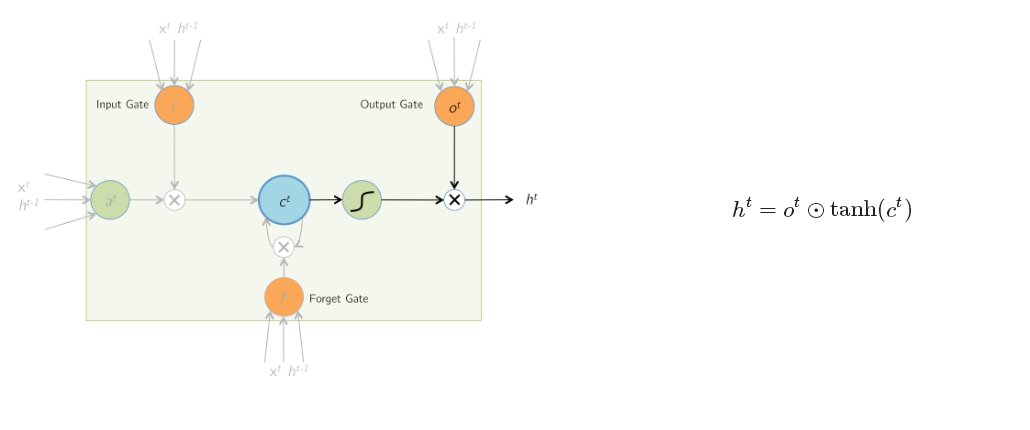
最終當前時刻的輸出h 是有cell內多個門函式共同作用的結果。
關於time_step的問題:
假設 文字的樣本資料集是(100, 80 , 50), 其中100指的是batch_size, 即樣本個數,80 是指句子sentence的最大長度, 也是指引數優化過程中一次處理的最大時間步長max_time steps, 50則是詞向量維度embedding_size, 假如num_hidden = 256, 那麼每個時間步 輸出的是256維度的一階向量,那麼在一次梯度優化過程中輸出的二階向量為80 * 256, 具體可以看下面的公式:

這裡的T 就是樣本集中的80,也是指一個sentence最大長度,我們在引數優化的過程中,以一個完整句子的輸出進行梯度下降計算。
以上只是參考了別人的想法,自己對lstm cell 的一個初步的理解和認識,後續在閱讀原始碼和案例程式碼的過程中,還需要反覆揣摩RNN網路的實際底層架構和計算原理,下一篇準備針對LSTMCell 進行原始碼分析。