
Elasticsearch架構原理解析
帶著問題學習
- 寫入的資料是如何變成elasticsearch裡可以被檢索和聚合的索引內容的?
- lucene如何實現準實時索引?
- 什麼是segment?
- 什麼是commit?
- segment的資料來自哪裡?
- segment在寫入磁碟前就可以被檢索,是因為利用了什麼?
- elasticsearch中的refresh操作是什麼?配置項是哪個?設定的命令是什麼?
- refresh只是寫到了檔案系統快取,那麼實際寫入磁碟是由什麼控制呢?,如果這期間發生錯誤和故障,資料會不會丟失?
- 什麼是translog日誌?什麼時候會被清空?什麼是flush操作?配置項是什麼?怎麼配置?
- 什麼是段合併?為什麼要段合併?段合併執行緒配置項?段合併策略?怎麼forcemerge(optimize)?
- routing的規則是什麼樣的?replica讀寫過程?wait_for_active_shards引數timeout引數 ?
- reroute 介面?
- 兩種 自動發現方式?
segment、buffer和translog對實時性的影響
既然介紹資料流向,首先第一步就是:寫入的資料是如何變成 Elasticsearch 裡可以被檢索和聚合的索引內容的?
以單檔案的靜態層面看,每個全文索引都是一個詞元的倒排索引,具體涉及到全文索引的通用知識,這裡不單獨介紹,有興趣的讀者可以閱讀《Lucene in Action》等書籍詳細瞭解。
動態更新的 Lucene 索引
以線上動態服務的層面看,要做到實時更新條件下資料的可用和可靠,就需要在倒排索引的基礎上,再做一系列更高階的處理。
其實總結一下 Lucene 的處理辦法,很簡單,就是一句話:新收到的資料寫到新的索引檔案裡。
Lucene 把每次生成的倒排索引,叫做一個段(segment)。然後另外使用一個 commit 檔案,記錄索引內所有的 segment。而生成 segment 的資料來源,則是記憶體中的 buffer。也就是說,動態更新過程如下:
當前索引有 3 個 segment 可用。索引狀態如圖 2-1;
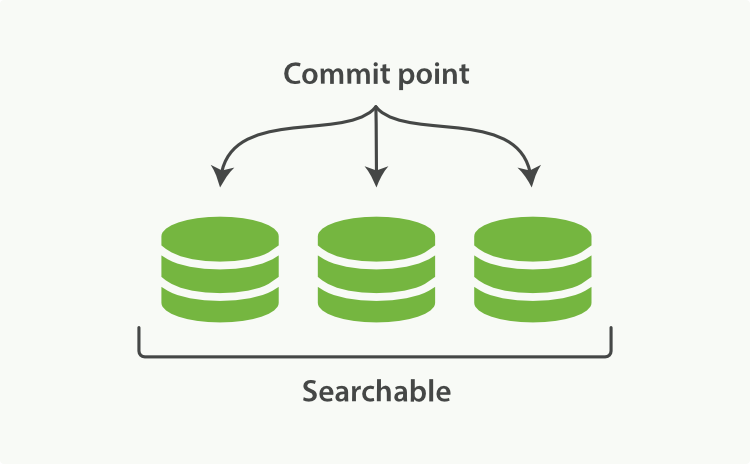
圖 2-1
新接收的資料進入記憶體 buffer。索引狀態如圖 2-2;
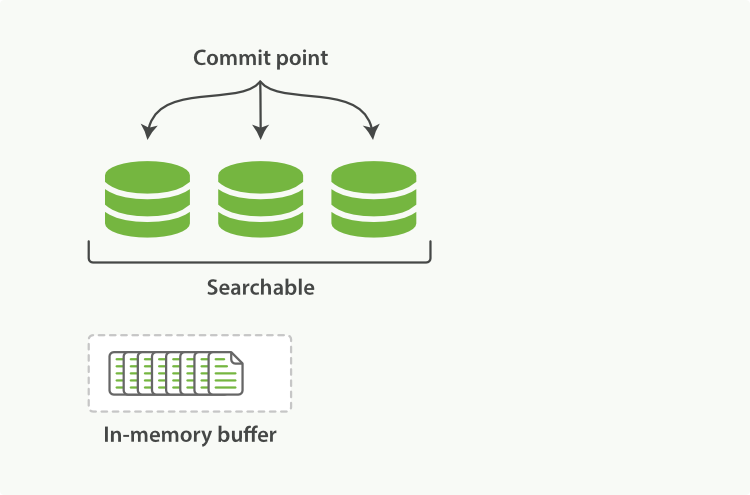
圖 2-2
記憶體 buffer 刷到磁碟,生成一個新的 segment,commit 檔案同步更新。索引狀態如圖 2-3。
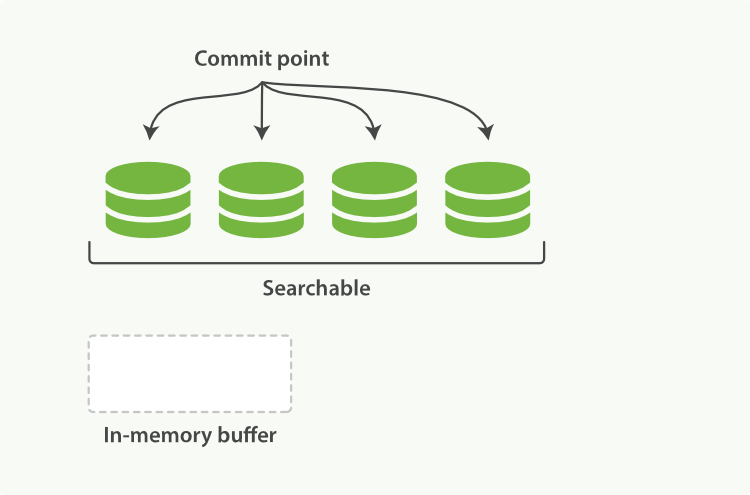
圖 2-3
利用磁碟快取實現的準實時檢索
既然涉及到磁碟,那麼一個不可避免的問題就來了:磁碟太慢了!對我們要求實時性很高的服務來說,這種處理還不夠。所以,在第 3 步的處理中,還有一箇中間狀態:
1、記憶體 buffer 生成一個新的 segment,刷到檔案系統快取中,Lucene 即可檢索這個新 segment。索引狀態如圖 2-4。
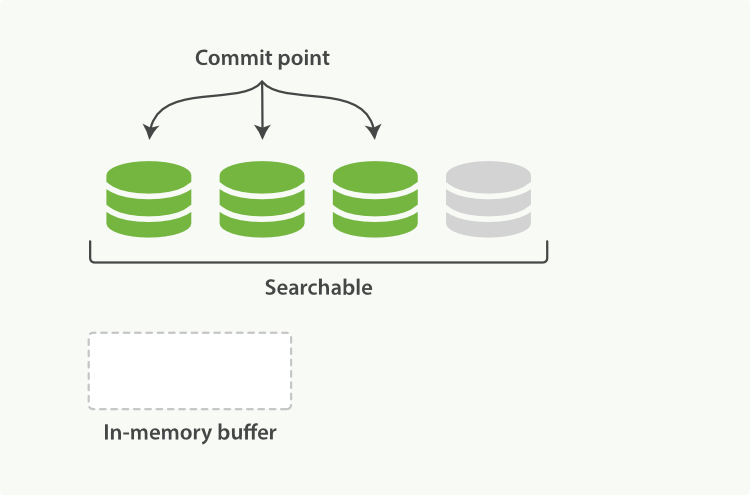
圖 2-4
2、檔案系統快取真正同步到磁碟上,commit 檔案更新。達到圖 2-3 中的狀態。
這一步刷到檔案系統快取的步驟,在 Elasticsearch 中,是預設設定為 1 秒間隔的,對於大多數應用來說,幾乎就相當於是實時可搜尋了。Elasticsearch 也提供了單獨的 /_refresh 介面,使用者如果對 1 秒間隔還不滿意的,可以主動呼叫該介面來保證搜尋可見。
注:5.0 中還提供了一個新的請求引數:?refresh=wait_for,可以在寫入資料後不強制重新整理但一直等到重新整理才返回。
不過對於 Elastic Stack 的日誌場景來說,恰恰相反,我們並不需要如此高的實時性,而是需要更快的寫入效能。所以,一般來說,我們反而會通過 /_settings 介面或者定製 template 的方式,加大 refresh_interval 引數:
# curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/_settings -d'
{ "refresh_interval": "10s" }'
如果是匯入歷史資料的場合,那甚至可以先完全關閉掉:
# curl -XPUT http://127.0.0.1:9200/logstash-2015.05.01 -d'
{
"settings" : {
"refresh_interval": "-1"
}
}'
在匯入完成以後,修改回來或者手動呼叫一次即可:
# curl -XPOST http://127.0.0.1:9200/logstash-2015.05.01/_refresh
translog 提供的磁碟同步控制
既然 refresh 只是寫到檔案系統快取,那麼第 4 步寫到實際磁碟又是有什麼來控制的?如果這期間發生主機錯誤、硬體故障等異常情況,資料會不會丟失?
這裡,其實有另一個機制來控制。Elasticsearch 在把資料寫入到記憶體 buffer 的同時,其實還另外記錄了一個 translog 日誌。也就是說,第 2 步並不是圖 2-2 的狀態,而是像圖 2-5 這樣:
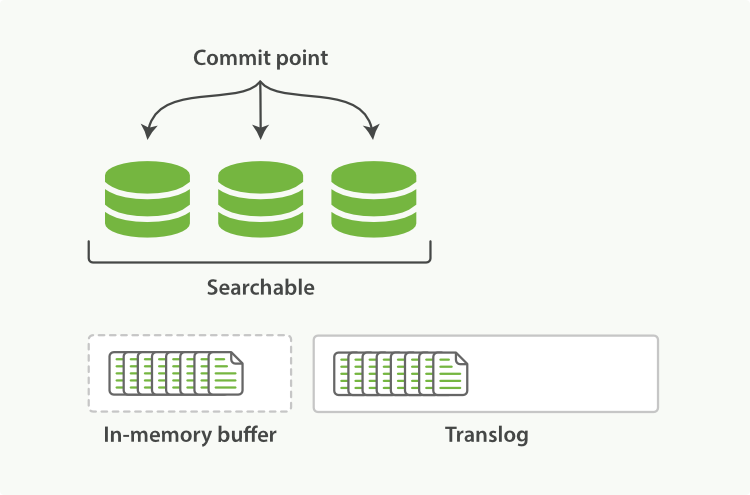
圖 2-5
在第 3 和第 4 步,refresh 發生的時候,translog 日誌檔案依然保持原樣,如圖 2-6:
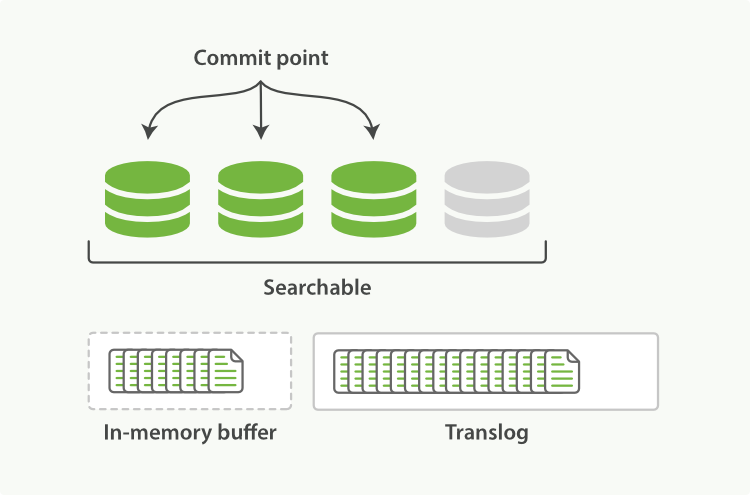
圖 2-6
也就是說,如果在這期間發生異常,Elasticsearch 會從 commit 位置開始,恢復整個 translog 檔案中的記錄,保證資料一致性。
等到真正把 segment 刷到磁碟,且 commit 檔案進行更新的時候, translog 檔案才清空。這一步,叫做 flush。同樣,Elasticsearch 也提供了 /_flush 介面。
對於 flush 操作,Elasticsearch 預設設定為:每 30 分鐘主動進行一次 flush,或者當 translog 檔案大小大於 512MB (老版本是 200MB)時,主動進行一次 flush。這兩個行為,可以分別通過 index.translog.flush_threshold_period 和 index.translog.flush_threshold_size 引數修改。
如果對這兩種控制方式都不滿意,Elasticsearch 還可以通過 index.translog.flush_threshold_ops 引數,控制每收到多少條資料後 flush 一次。
translog 的一致性
索引資料的一致性通過 translog 保證。那麼 translog 檔案自己呢?
預設情況下,Elasticsearch 每 5 秒,或每次請求操作結束前,會強制重新整理 translog 日誌到磁碟上。
後者是 Elasticsearch 2.0 新加入的特性。為了保證不丟資料,每次 index、bulk、delete、update 完成的時候,一定觸發重新整理 translog 到磁碟上,才給請求返回 200 OK。這個改變在提高資料安全性的同時當然也降低了一點效能。
如果你不在意這點可能性,還是希望效能優先,可以在 index template 裡設定如下引數:
{
"index.translog.durability": "async"
}
Elasticsearch 分散式索引
大家可能注意到了,前面一段內容,一直寫的是”Lucene 索引”。這個區別在於,Elasticsearch 為了完成分散式系統,對一些名詞概念作了變動。索引成為了整個叢集級別的命名,而在單個主機上的Lucene 索引,則被命名為分片(shard)。至於資料是怎麼識別到自己應該在哪個分片,請閱讀稍後有關 routing 的章節。
segment merge對寫入效能的影響
通過上節內容,我們知道了資料怎麼進入 ES 並且如何才能讓資料更快的被檢索使用。其中用一句話概括了 Lucene 的設計思路就是”開新檔案”。從另一個方面看,開新檔案也會給伺服器帶來負載壓力。因為預設每 1 秒,都會有一個新檔案產生,每個檔案都需要有檔案控制代碼,記憶體,CPU 使用等各種資源。一天有 86400 秒,設想一下,每次請求要掃描一遍 86400 個檔案,這個響應效能絕對好不了!
為了解決這個問題,ES 會不斷在後臺執行任務,主動將這些零散的 segment 做資料歸併,儘量讓索引內只保有少量的,每個都比較大的,segment 檔案。這個過程是有獨立的執行緒來進行的,並不影響新 segment 的產生。歸併過程中,索引狀態如圖 2-7,尚未完成的較大的 segment 是被排除在檢索可見範圍之外的:
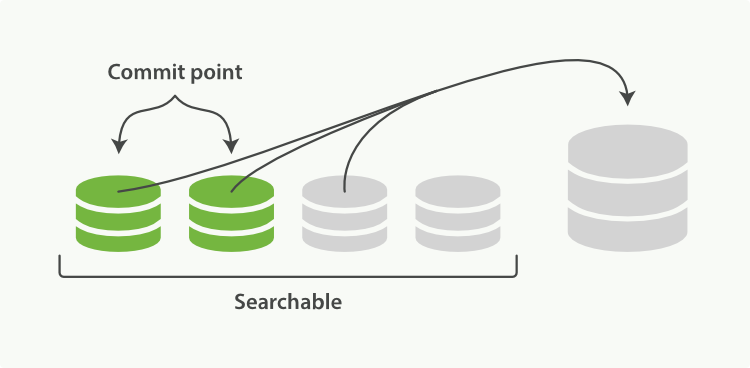
圖 2-7
當歸並完成,較大的這個 segment 刷到磁碟後,commit 檔案做出相應變更,刪除之前幾個小 segment,改成新的大 segment。等檢索請求都從小 segment 轉到大 segment 上以後,刪除沒用的小 segment。這時候,索引裡 segment 數量就下降了,狀態如圖 2-8 所示:
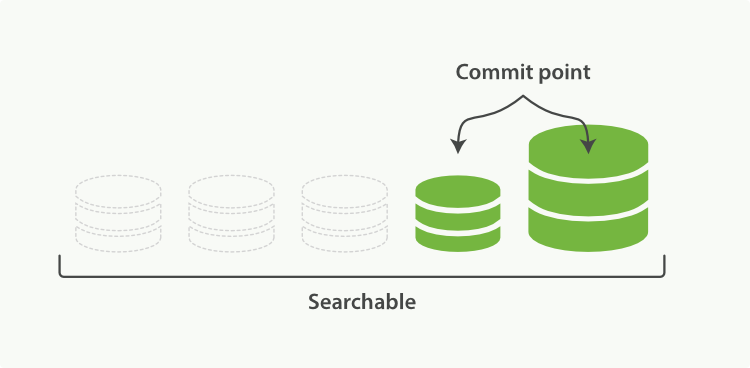
圖 2-8
歸併執行緒配置
segment 歸併的過程,需要先讀取 segment,歸併計算,再寫一遍 segment,最後還要保證刷到磁碟。可以說,這是一個非常消耗磁碟 IO 和 CPU 的任務。所以,ES 提供了對歸併執行緒的限速機制,確保這個任務不會過分影響到其他任務。
在 5.0 之前,歸併執行緒的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。對於寫入量較大,磁碟轉速較高,甚至使用 SSD 盤的伺服器來說,這個限速是明顯過低的。對於 Elastic Stack 應用,社群廣泛的建議是可以適當調大到 100MB或者更高。
# curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}'
5.0 開始,ES 對此作了大幅度改進,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 機制,正常情況下已經不再需要手動配置 indices.store.throttle.max_bytes_per_sec 了。官方文件中都已經刪除了相關介紹,不過從原始碼中還是可以看到,這個值目前的預設設定是 10240 MB。
歸併執行緒的數目,ES 也是有所控制的。預設數目的計算公式是: Math.min(3, Runtime.getRuntime().availableProcessors() / 2)。即伺服器 CPU 核數的一半大於 3 時,啟動 3 個歸併執行緒;否則啟動跟 CPU 核數的一半相等的執行緒數。相信一般做 Elastic Stack 的伺服器 CPU 合數都會在 6 個以上。所以一般來說就是 3 個歸併執行緒。如果你確定自己磁碟效能跟不上,可以降低 index.merge.scheduler.max_thread_count 配置,免得 IO 情況更加惡化。
歸併策略
歸併執行緒是按照一定的執行策略來挑選 segment 進行歸併的。主要有以下幾條:
- index.merge.policy.floor_segment 預設 2MB,小於這個大小的 segment,優先被歸併。
- index.merge.policy.max_merge_at_once 預設一次最多歸併 10 個 segment
- index.merge.policy.max_merge_at_once_explicit 預設 forcemerge 時一次最多歸併 30 個 segment。
- index.merge.policy.max_merged_segment 預設 5 GB,大於這個大小的 segment,不用參與歸併。forcemerge 除外。
根據這段策略,其實我們也可以從另一個角度考慮如何減少 segment 歸併的消耗以及提高響應的辦法:加大 flush 間隔,儘量讓每次新生成的 segment 本身大小就比較大。
forcemerge 介面
既然預設的最大 segment 大小是 5GB。那麼一個比較龐大的資料索引,就必然會有為數不少的 segment 永遠存在,這對檔案控制代碼,記憶體等資源都是極大的浪費。但是由於歸併任務太消耗資源,所以一般不太選擇加大 index.merge.policy.max_merged_segment 配置,而是在負載較低的時間段,通過 forcemerge 介面,強制歸併 segment。
# curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
由於 forcemerge 執行緒對資源的消耗比普通的歸併執行緒大得多,所以,絕對不建議對還在寫入資料的熱索引執行這個操作。這個問題對於 Elastic Stack 來說非常好辦,一般索引都是按天分割的。更合適的任務定義方式,請閱讀本書稍後的 curator 章節。
routing和replica的讀寫過程
之前兩節,完整介紹了在單個 Lucene 索引,即 ES 分片內的資料寫入流程。現在徹底回到 ES 的分散式層面上來,當一個 ES 節點收到一條資料的寫入請求時,它是如何確認這個資料應該儲存在哪個節點的哪個分片上的?
路由計算
作為一個沒有額外依賴的簡單的分散式方案,ES 在這個問題上同樣選擇了一個非常簡潔的處理方式,對任一條資料計算其對應分片的方式如下:
shard = hash(routing) % number_of_primary_shards
每個資料都有一個 routing 引數,預設情況下,就使用其 _id 值。將其 _id 值計算雜湊後,對索引的主分片數取餘,就是資料實際應該儲存到的分片 ID。
由於取餘這個計算,完全依賴於分母,所以導致 ES 索引有一個限制,索引的主分片數,不可以隨意修改。因為一旦主分片數不一樣,所以資料的儲存位置計算結果都會發生改變,索引資料就完全不可讀了。
副本一致性
作為分散式系統,資料副本可算是一個標配。ES 資料寫入流程,自然也涉及到副本。在有副本配置的情況下,資料從發向 ES 節點,到接到 ES 節點響應返回,流向如下(附圖 2-9):
- 客戶端請求傳送給 Node 1 節點,注意圖中 Node 1 是 Master 節點,實際完全可以不是。
- Node 1 用資料的 _id 取餘計算得到應該講資料儲存到 shard 0 上。通過 cluster state 資訊發現 shard 0 的主分片已經分配到了 Node 3 上。Node 1 轉發請求資料給 Node 3。
- Node 3 完成請求資料的索引過程,存入主分片 0。然後並行轉發資料給分配有 shard 0 的副本分片的 Node 1 和 Node 2。當收到任一節點彙報副本分片資料寫入成功,Node 3 即返回給初始的接收節點 Node 1,宣佈資料寫入成功。Node 1 返回成功響應給客戶端。
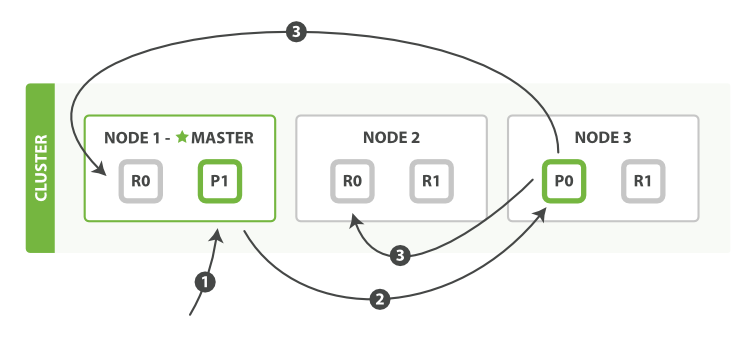
圖 2-9
這個過程中,有幾個引數可以用來控制或變更其行為:
- wait_for_active_shards
上面示例中,2 個副本分片只要有 1 個成功,就可以返回給客戶端了。這點也是有配置項的。其預設值的計算來源如下:
int( (primary + number_of_replicas) / 2 ) + 1
根據需要,也可以將引數設定為 one,表示僅寫完主分片就返回,等同於 async;還可以設定為 all,表示等所有副本分片都寫完才能返回。
- * timeout
如果叢集出現異常,有些分片當前不可用,ES 預設會等待 1 分鐘看分片能否恢復。可以使用 ?timeout=30s 引數來縮短這個等待時間。
副本配置和分片配置不一樣,是可以隨時調整的。有些較大的索引,甚至可以在做 forcemerge 前,先把副本全部取消掉,等 optimize 完後,再重新開啟副本,節約單個 segment 的重複歸併消耗。
# curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{
"index": { "number_of_replicas" : 0 }
}'
shard 的 allocate 控制
某個 shard 分配在哪個節點上,一般來說,是由 ES 自動決定的。以下幾種情況會觸發分配動作:
- 新索引生成
- 索引的刪除
- 新增副本分片
- 節點增減引發的資料均衡
ES 提供了一系列引數詳細控制這部分邏輯:
- cluster.routing.allocation.enable 該引數用來控制允許分配哪種分片。預設是 all。可選項還包括 primaries 和 new_primaries。none 則徹底拒絕分片。該引數的作用,本書稍後叢集升級章節會有說明。
- cluster.routing.allocation.allow_rebalance 該引數用來控制什麼時候允許資料均衡。預設是 indices_all_active,即要求所有分片都正常啟動成功以後,才可以進行資料均衡操作,否則的話,在叢集重啟階段,會浪費太多流量了。
- cluster.routing.allocation.cluster_concurrent_rebalance 該引數用來控制叢集內同時執行的資料均衡任務個數。預設是 2 個。如果有節點增減,且叢集負載壓力不高的時候,可以適當加大。
- cluster.routing.allocation.node_initial_primaries_recoveries 該引數用來控制節點重啟時,允許同時恢復幾個主分片。預設是 4 個。如果節點是多磁碟,且 IO 壓力不大,可以適當加大。
- cluster.routing.allocation.node_concurrent_recoveries 該引數用來控制節點除了主分片重啟恢復以外其他情況下,允許同時執行的資料恢復任務。預設是 2 個。所以,節點重啟時,可以看到主分片迅速恢復完成,副本分片的恢復卻很慢。除了副本分片本身資料要通過網路複製以外,併發執行緒本身也減少了一半。當然,這種設定也是有道理的——主分片一定是本地恢復,副本分片卻需要走網路,頻寬是有限的。從 ES 1.6 開始,冷索引的副本分片可以本地恢復,這個引數也就是可以適當加大了。
- indices.recovery.concurrent_streams 該引數用來控制節點從網路複製恢復副本分片時的資料流個數。預設是 3 個。可以配合上一條配置一起加大。
- indices.recovery.max_bytes_per_sec 該引數用來控制節點恢復時的速率。預設是 40MB。顯然是比較小的,建議加大。
此外,ES 還有一些其他的分片分配控制策略。比如以 tag 和 rack_id 作為區分等。一般來說,Elastic Stack 場景中使用不多。運維人員可能比較常見的策略有兩種:
- 磁碟限額
為了保護節點資料安全,ES 會定時(cluster.info.update.interval,預設 30 秒)檢查一下各節點的資料目錄磁碟使用情況。在達到 cluster.routing.allocation.disk.watermark.low (預設 85%)的時候,新索引分片就不會再分配到這個節點上了。在達到 cluster.routing.allocation.disk.watermark.high (預設 90%)的時候,就會觸發該節點現存分片的資料均衡,把資料挪到其他節點上去。這兩個值不但可以寫百分比,還可以寫具體的位元組數。有些公司可能出於成本考慮,對磁碟使用率有一定的要求,需要適當擡高這個配置:
# curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.disk.watermark.low" : "85%",
"cluster.routing.allocation.disk.watermark.high" : "10gb",
"cluster.info.update.interval" : "1m"
}
}'
- 熱索引分片不均
預設情況下,ES 叢集的資料均衡策略是以各節點的分片總數(indices_all_active)作為基準的。這對於搜尋服務來說無疑是均衡搜尋壓力提高效能的好辦法。但是對於 Elastic Stack 場景,一般壓力集中在新索引的資料寫入方面。正常執行的時候,也沒有問題。但是當叢集擴容時,新加入叢集的節點,分片總數遠遠低於其他節點。這時候如果有新索引建立,ES 的預設策略會導致新索引的所有主分片幾乎全分配在這臺新節點上。整個叢集的寫入壓力,壓在一個節點上,結果很可能是這個節點直接被壓死,叢集出現異常。
所以,對於 Elastic Stack 場景,強烈建議大家預先計算好索引的分片數後,配置好單節點分片的限額。比如,一個 5 節點的叢集,索引主分片 10 個,副本 1 份。則平均下來每個節點應該有 4 個分片,那麼就配置:
# curl -s -XPUT http://127.0.0.1:9200/logstash-2015.05.08/_settings -d '{
"index": { "routing.allocation.total_shards_per_node" : "5" }
}'
注意,這裡配置的是 5 而不是 4。因為我們需要預防有機器故障,分片發生遷移的情況。如果寫的是 4,那麼分片遷移會失敗。
此外,另一種方式則更加玄妙,Elasticsearch 中有一系列引數,相互影響,最終聯合決定分片分配:
- cluster.routing.allocation.balance.shard 節點上分配分片的權重,預設為 0.45。數值越大越傾向於在節點層面均衡分片。
- cluster.routing.allocation.balance.index 每個索引往單個節點上分配分片的權重,預設為 0.55。數值越大越傾向於在索引層面均衡分片。
- cluster.routing.allocation.balance.threshold 大於閾值則觸發均衡操作。預設為1。
Elasticsearch 中的計算方法是:
(indexBalance * (node.numShards(index) – avgShardsPerNode(index)) + shardBalance * (node.numShards() – avgShardsPerNode)) <=> weightthreshold
所以,也可以採取加大 cluster.routing.allocation.balance.index,甚至設定 cluster.routing.allocation.balance.shard 為 0 來儘量採用索引內的節點均衡。
reroute 介面
上面說的各種配置,都是從策略層面,控制分片分配的選擇。在必要的時候,還可以通過 ES 的 reroute 介面,手動完成對分片的分配選擇的控制。
reroute 介面支援五種指令:allocate_replica, allocate_stale_primary, allocate_empty_primary,move 和 cancel。常用的一般是 allocate 和 move:
- allocate_* 指令
因為負載過高等原因,有時候個別分片可能長期處於 UNASSIGNED 狀態,我們就可以手動分配分片到指定節點上。預設情況下只允許手動分配副本分片(即使用 allocate_replica),所以如果要分配主分片,需要單獨加一個 accept_data_loss 選項:
# curl -XPOST 127.0.0.1:9200/_cluster/reroute -d '{
"commands" : [ {
"allocate_stale_primary" :
{
"index" : "logstash-2015.05.27", "shard" : 61, "node" : "10.19.0.77", "accept_data_loss" : true
}
}
]
}'
注意,allocate_stale_primary 表示準備分配到的節點上可能有老版本的歷史資料,執行時請提前確認一下是哪個節點上保留有這個分片的實際目錄,且目錄大小最大。然後手動分配到這個節點上。以此減少資料丟失。
- move 指令
因為負載過高,磁碟利用率過高,伺服器下線,更換磁碟等原因,可以會需要從節點上移走部分分片:
curl -XPOST 127.0.0.1:9200/_cluster/reroute -d '{
"commands" : [ {
"move" :
{
"index" : "logstash-2015.05.22", "shard" : 0, "from_node" : "10.19.0.81", "to_node" : "10.19.0.104"
}
}
]
}'
分配失敗原因
如果是自己手工 reroute 失敗,Elasticsearch 返回的響應中會帶上失敗的原因。不過格式非常難看,一堆 YES,NO。從 5.0 版本開始,Elasticsearch 新增了一個 allocation explain 介面,專門用來解釋指定分片的具體失敗理由:
curl -XGET 'http://localhost:9200/_cluster/allocation/explain' -d'{
"index": "logstash-2016.10.31",
"shard": 0,
"primary": false
}'
得到的響應如下:
{
"shard" : {
"index" : "myindex",
"index_uuid" : "KnW0-zELRs6PK84l0r38ZA",
"id" : 0,
"primary" : false
},
"assigned" : false,
"shard_state_fetch_pending": false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-22T20:04:23.620Z"
},
"allocation_delay_ms" : 0,
"remaining_delay_ms" : 0,
"nodes" : {
"V-Spi0AyRZ6ZvKbaI3691w" : {
"node_name" : "H5dfFeA",
"node_attributes" : {
"bar" : "baz"
},
"store" : {
"shard_copy" : "NONE"
},
"final_decision" : "NO",
"final_explanation" : "the shard cannot be assigned because one or more allocation decider returns a 'NO' decision",
"weight" : 0.06666675,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ]
},
"Qc6VL8c5RWaw1qXZ0Rg57g" : {
...
這會是很長一串 JSON,把叢集裡所有的節點都列上來,挨個解釋為什麼不能分配到這個節點。
節點下線
叢集中個別節點出現故障預警等情況,需要下線,也是 Elasticsearch 運維工作中常見的情況。如果已經穩定執行過一段時間的叢集,每個節點上都會儲存有數量不少的分片。這種時候通過 reroute 介面手動轉移,就顯得太過麻煩了。這個時候,有另一種方式:
curl -XPUT 127.0.0.1:9200/_cluster/settings -d '{
"transient" :{
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}'
Elasticsearch 叢集就會自動把這個 IP 上的所有分片,都自動轉移到其他節點上。等到轉移完成,這個空節點就可以毫無影響的下線了。
和 _ip 類似的引數還有 _host, _name 等。此外,這類引數不單是 cluster 級別,也可以是 index 級別。下一小節就是 index 級別的用例。
冷熱資料的讀寫分離
Elasticsearch 叢集一個比較突出的問題是: 使用者做一次大的查詢的時候, 非常大量的讀 IO 以及聚合計算導致機器 Load 升高, CPU 使用率上升, 會影響阻塞到新資料的寫入, 這個過程甚至會持續幾分鐘。所以,可能需要仿照 MySQL 叢集一樣,做讀寫分離。
實施方案
N 臺機器做熱資料的儲存, 上面只放當天的資料。這 N 臺熱資料節點上面的 elasticsearc.yml 中配置 node.attr.tag: hot
之前的資料放在另外的 M 臺機器上。這 M 臺冷資料節點中配置 node.attr.tag: stale
模板中控制對新建索引新增 hot 標籤:
{
"order" : 0,
"template" : "*",
"settings" : {
"index.routing.allocation.include.tag" : "hot"
}
}
每天計劃任務更新索引的配置, 將 tag 更改為 stale, 索引會自動遷移到 M 臺冷資料節點
curl -XPUT http://127.0.0.1:9200/indexname/_settings -d'
{
"index": {
"routing": {
"allocation": {
"include": {
"tag": "stale"
}
}
}
}
}'
這樣,寫操作集中在 N 臺熱資料節點上,大範圍的讀操作集中在 M 臺冷資料節點上。避免了堵塞影響。
該方案運用的,是 Elasticsearch 中的 allocation filter 功能,詳細說明見:https://www.elastic.co/guide/en/elasticsearch/reference/master/shard-allocation-filtering.html
叢集自動發現
ES 是一個 P2P 型別(使用 gossip 協議)的分散式系統,除了叢集狀態管理以外,其他所有的請求都可以傳送到叢集內任意一臺節點上,這個節點可以自己找到需要轉發給哪些節點,並且直接跟這些節點通訊。
所以,從網路架構及服務配置上來說,構建叢集所需要的配置極其簡單。在 Elasticsearch 2.0 之前,無阻礙的網路下,所有配置了相同 cluster.name 的節點都自動歸屬到一個叢集中。
2.0 版本之後,基於安全的考慮,Elasticsearch 稍作了調整,避免開發環境過於隨便造成的麻煩。
unicast 方式
ES 從 2.0 版本開始,預設的自動發現方式改為了單播(unicast)方式。配置裡提供幾臺節點的地址,ES 將其視作 gossip router 角色,藉以完成叢集的發現。由於這只是 ES 內一個很小的功能,所以 gossip router 角色並不需要單獨配置,每個 ES 節點都可以擔任。所以,採用單播方式的叢集,各節點都配置相同的幾個節點列表作為 router 即可。
此外,考慮到節點有時候因為高負載,慢 GC 等原因可能會有偶爾沒及時響應 ping 包的可能,一般建議稍微加大 Fault Detection 的超時時間。
同樣基於安全考慮做的變更還有監聽的主機名。現在預設只監聽本地 lo 網絡卡上。所以正式環境上需要修改配置為監聽具體的網絡卡。
network.host: "192.168.0.2"
discovery.zen.minimum_master_nodes: 3
discovery.zen.ping_timeout: 100s
discovery.zen.fd.ping_timeout: 100s
discovery.zen.ping.unicast.hosts: ["10.19.0.97","10.19.0.98","10.19.0.99","10.19.0.100"]
上面的配置中,兩個 timeout 可能會讓人有所迷惑。這裡的 fd 是 fault detection 的縮寫。也就是說:
discovery.zen.ping_timeout 引數僅在加入或者選舉 master 主節點的時候才起作用;
discovery.zen.fd.ping_timeout 引數則在穩定執行的叢集中,master 檢測所有節點,以及節點檢測 master 是否暢通時長期有用。
既然是長期有用,自然還有執行間隔和重試的配置,也可以根據實際情況調整:
discovery.zen.fd.ping_interval: 10s
discovery.zen.fd.ping_retries: 10
(本文完)
文字整理自《ELKstack權威指南》
---------------------
作者:GhostStories
來源:CSDN
原文:https://blog.csdn.net/wangnan9279/article/details/79287846
版權宣告:本文為博主原創文章,轉載請附上博文連結!