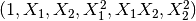python機器學習::資料預處理(1)【轉】
阿新 • • 發佈:2018-12-10
轉載自:http://2hwp.com/2016/02/03/data-preprocessing/
常見的資料預處理方法,以下通過sklearn的preprocessing模組來介紹;
1. 標準化(Standardization or Mean Removal and Variance Scaling)
變換後各維特徵有0均值,單位方差。也叫z-score規範化(零均值規範化)。計算方式是將特徵值減去均值,除以標準差。
1 |
sklearn.preprocessing.scale(X) |
一般會把train和test集放在一起做標準化,或者在train集上做標準化後,用同樣的標準化器去標準化test集,此時可以用scaler
1 2 3 |
scaler = sklearn.preprocessing.StandardScaler().fit(train) scaler.transform(train) scaler.transform(test) |
實際應用中,需要做特徵標準化的常見情景:SVM
2. 最小-最大規範化
最小-最大規範化對原始資料進行線性變換,變換到[0,1]區間(也可以是其他固定最小最大值的區間)
1 2 |
min_max_scaler = sklearn.preprocessing.MinMaxScaler() min_max_scaler.fit_transform(X_train) |
3.規範化(Normalization)
規範化是將不同變化範圍的值對映到相同的固定範圍,常見的是[0,1],此時也稱為歸一化。《機器學習》周志華
將每個樣本變換成unit norm。
1 2 |
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]] sklearn.preprocessing.normalize(X, norm='l2') |
得到:
1 |
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]]) |
可以發現對於每一個樣本都有,0.4^2+0.4^2+0.81^2=1,這就是L2 norm,變換後每個樣本的各維特徵的平方和為1。類似地,L1 norm則是變換後每個樣本的各維特徵的絕對值和為1。還有max norm,則是將每個樣本的各維特徵除以該樣本各維特徵的最大值。
在度量樣本之間相似性時,如果使用的是二次型kernel,需要做Normalization
4. 特徵二值化(Binarization)
給定閾值,將特徵轉換為0/1
1 2 |
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1) binarizer.transform(X) |
5. 標籤二值化(Label binarization)
1 |
lb = sklearn.preprocessing.LabelBinarizer() |
6. 類別特徵編碼
有時候特徵是類別型的,而一些演算法的輸入必須是數值型,此時需要對其編碼。
1 2 3 |
enc = preprocessing.OneHotEncoder() enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]]) |
上面這個例子,第一維特徵有兩種值0和1,用兩位去編碼。第二維用三位,第三維用四位。
7.標籤編碼(Label encoding)
1 2 3 4 5 6 |
le = sklearn.preprocessing.LabelEncoder() le.fit([1, 2, 2, 6]) le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2]) #非數值型轉化為數值型 le.fit(["paris", "paris", "tokyo", "amsterdam"]) le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1]) |
8.特徵中含異常值時
1 |
sklearn.preprocessing.robust_scale |
9.生成多項式特徵
這個其實涉及到特徵工程了,多項式特徵/交叉特徵。
1 2 |
poly = sklearn.preprocessing.PolynomialFeatures(2) poly.fit_transform(X) |
原始特徵:
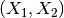
轉化後: