NLP句法分析小結
句法分析是自然語言處理(natural language processing, NLP)中的關鍵底層技術之一,其基本任務是確定句子的句法結構或者句子中詞彙之間的依存關係。
句法分析分為句法結構分析(syntactic structure parsing)和依存關係分析(dependency parsing)。以獲取整個句子的句法結構或者完全短語結構為目的的句法分析,被稱為成分結構分析(constituent structure parsing)或者短語結構分析(phrase structure parsing);另外一種是以獲取區域性成分為目的的句法分析,被稱為依存分析(dependency parsing)。
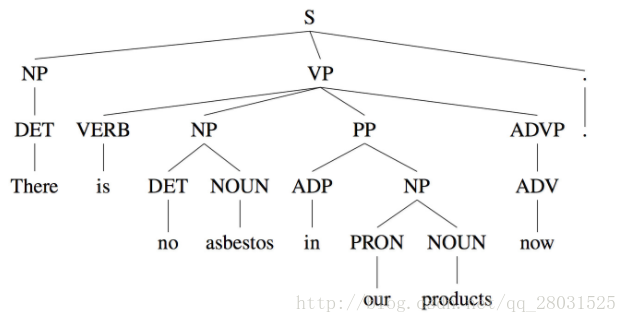
如以下取自WSJ語料庫的句法結構樹示例:
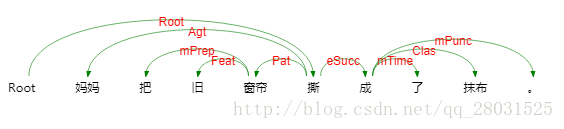 目前的句法分析已經從句法結構分析轉向依存句法分析,一是因為通用資料集Treebank(Universal Dependencies treebanks)的發展,雖然該資料集的標註較為複雜,但是其標註結果可以用作多種任務(命名體識別或詞性標註)且作為不同任務的評估資料,因而得到越來越多的應用,二是句法結構分析的語法集是由固定的語法集組成,較為固定和呆板;三是依存句法分析樹標註簡單且parser準確率高。
目前的句法分析已經從句法結構分析轉向依存句法分析,一是因為通用資料集Treebank(Universal Dependencies treebanks)的發展,雖然該資料集的標註較為複雜,但是其標註結果可以用作多種任務(命名體識別或詞性標註)且作為不同任務的評估資料,因而得到越來越多的應用,二是句法結構分析的語法集是由固定的語法集組成,較為固定和呆板;三是依存句法分析樹標註簡單且parser準確率高。
本文將對學習中遇到的PCFG、Lexical PCFG及主流的依存句法分析方法—Transition-based Parsing(基於貪心決策動作拼裝句法樹)做一整理。 目錄:
1.PCFG
結合上下文無關文法(CFG)中最左派生規則(left-most derivations)和不同的rules概率,計算所有可能的樹結構概率,取最大值對應的樹作為該句子的句法分析結果。
(The key idea in probabilistic context-free grammars(PCFG) is to extend our definition to give a probability over possible derivations.)
對最左派生規則的每一步都新增概率,這樣整棵句法分析樹的概率就是所有這些“獨立”的概率的乘積。 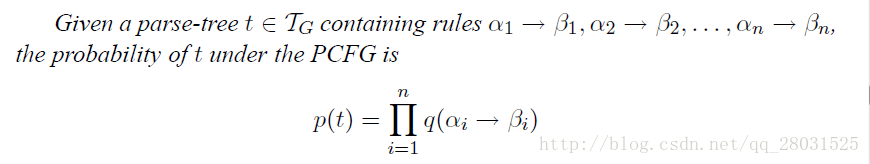
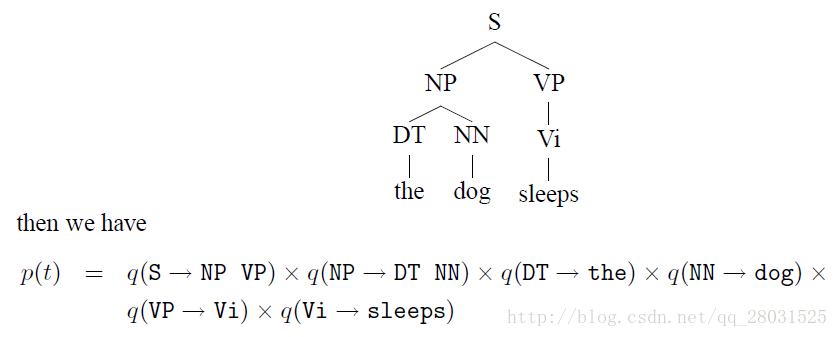
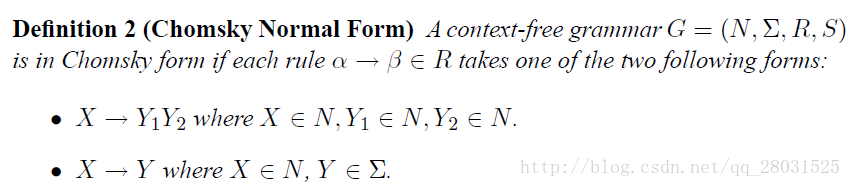
問題是如何尋找概率最大的句法分析樹結構?
1. 暴力搜尋(Brute-force method)
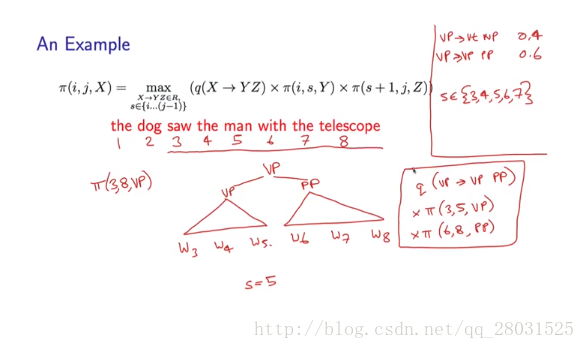
暴力搜尋Brute-force method(根據PCFG的rules,暴力計算不同句法結構的概率,選擇概率最高的句法分析樹作為結論),缺陷在於隨著句子的增長,計算量指數增長: 


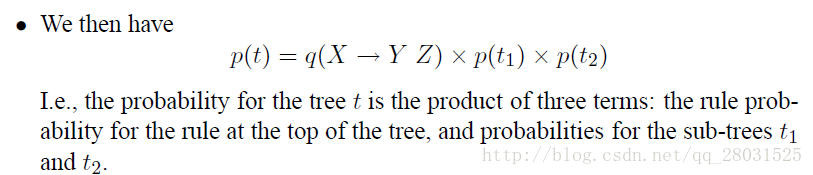



2.Lexical PCFG(基於詞典的PCFG)
首先考慮PCFG的缺陷:
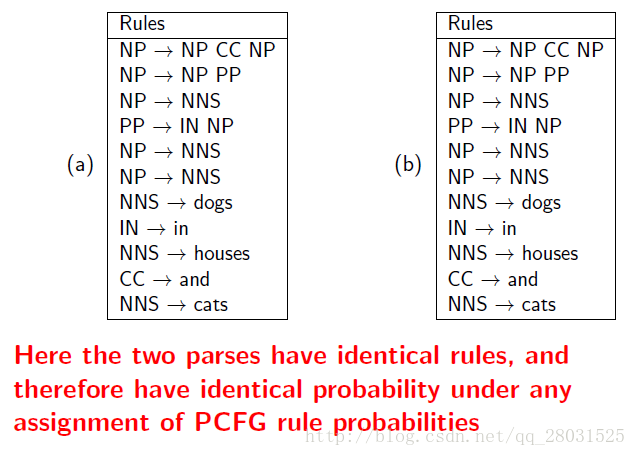
1、在PCFG中,詞的選擇具有很強的獨立性假設,詞的選擇完全依賴於當前的詞性(POS),而條件獨立於與其他所有句法樹上的結構(More formally, the choice of each word in the string is conditionally independent of the entire tree,once we have conditioned on the POS directly above the word),而這正是很多歧義問題的原因。下例中,’IBM’的選擇僅僅與’NP’有關,而與其他樹上的結構完全無關。 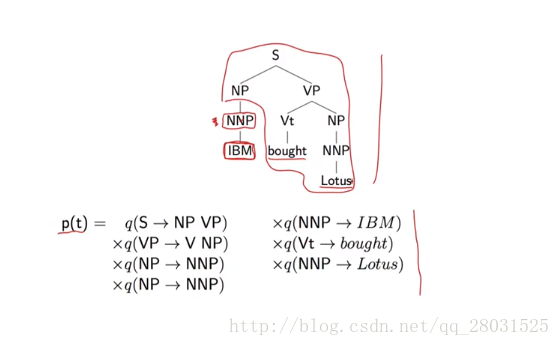
Lexicalized Context-Free
自下向上(bottom-up)的標記每條規則的head child,並新增到句法分析樹上,每條規則的head child採用啟發式自動選擇。 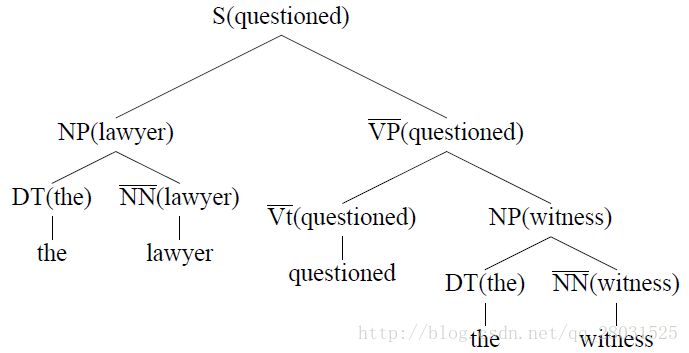





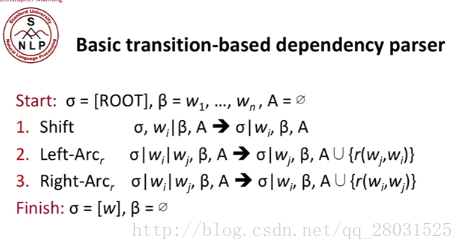
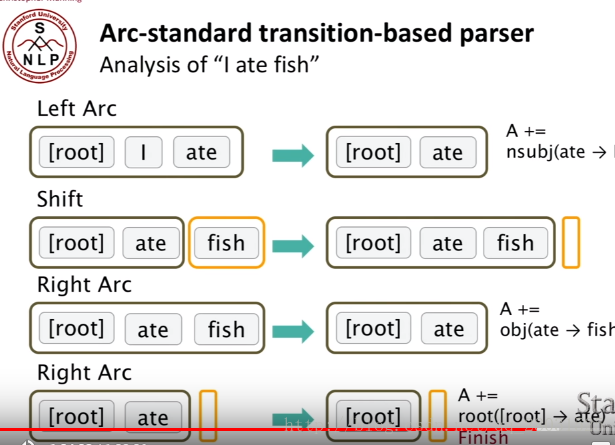
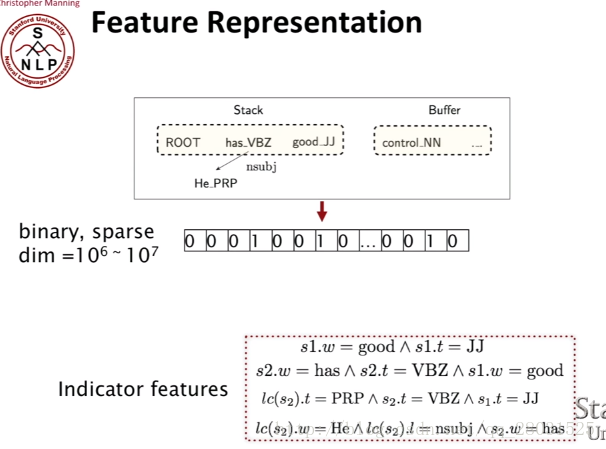
3.Transition-based parsing(基於貪心決策動作的拼接句法樹)
首先介紹Arc-standard transition,動作體系的formal描述如下: