
NLP底層技術之句法分析
句法分析是自然語言處理(natural language processing, NLP)中的關鍵底層技術之一,其基本任務是確定句子的句法結構或者句子中詞彙之間的依存關係。
句法分析分為句法結構分析(syntactic structure parsing)和依存關係分析(dependency parsing)。以獲取整個句子的句法結構或者完全短語結構為目的的句法分析,被稱為成分結構分析(constituent structure parsing)或者短語結構分析(phrase structure parsing);另外一種是以獲取區域性成分為目的的句法分析,被稱為依存分析(dependency parsing)。
如以下取自WSJ語料庫的句法結構樹示例:
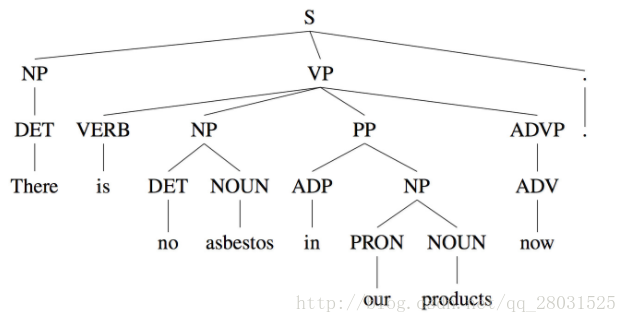
以及取自哈工大LTP的依存句法分析例項:
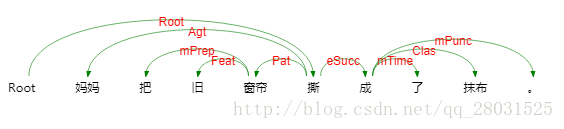
目前的句法分析已經從句法結構分析轉向依存句法分析,一是因為通用資料集Treebank(Universal Dependencies treebanks)的發展,雖然該資料集的標註較為複雜,但是其標註結果可以用作多種任務(命名體識別或詞性標註)且作為不同任務的評估資料,因而得到越來越多的應用,二是句法結構分析的語法集是由固定的語法集組成,較為固定和呆板;三是依存句法分析樹標註簡單且parser準確率高。
本文將對學習中遇到的PCFG、Lexical PCFG及主流的依存句法分析方法—Transition-based Parsing
目錄:
1.PCFG
結合上下文無關文法(CFG)中最左派生規則(left-most derivations)和不同的rules概率,計算所有可能的樹結構概率,取最大值對應的樹作為該句子的句法分析結果。
(The key idea in probabilistic context-free grammars(PCFG) is to extend our definition to give a probability over possible derivations.)
對最左派生規則的每一步都新增概率,這樣整棵句法分析樹的概率就是所有這些“獨立”的概率的乘積。
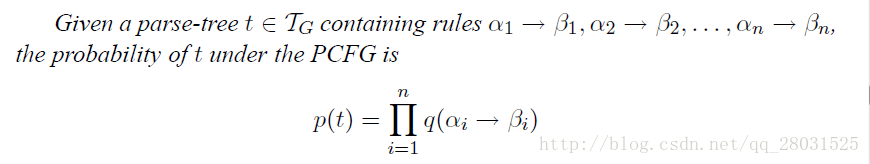
如下例:
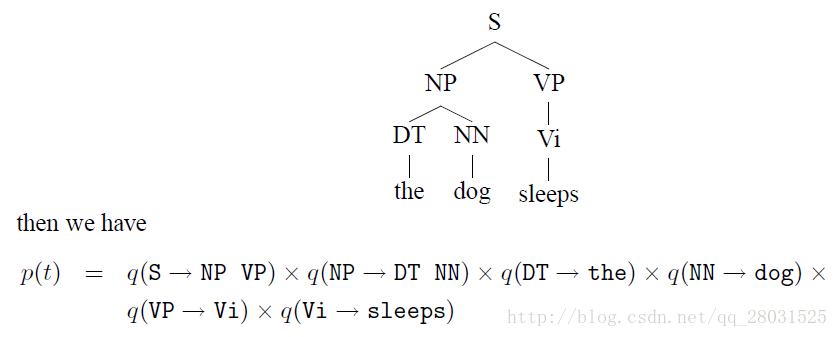
為了方便計算,在PCFG中新增對rules的限制(Chomsky Normal Form):
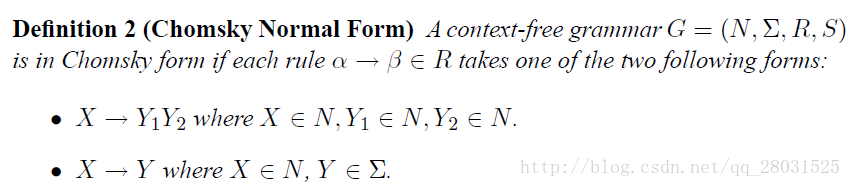
問題是如何尋找概率最大的句法分析樹結構?
1. 暴力搜尋(Brute-force method)
暴力搜尋Brute-force method(根據PCFG的rules,暴力計算不同句法結構的概率,選擇概率最高的句法分析樹作為結論),缺陷在於隨著句子的增長,計算量指數增長:

2. 動態規劃(dynamic programming)CKY演算法
is the highest score for any parse tree that dominates words , and has non-terminal X as its root.
因此整個句子的概率為,其中是句子所有可能結構的集合。


結合上面的定義:
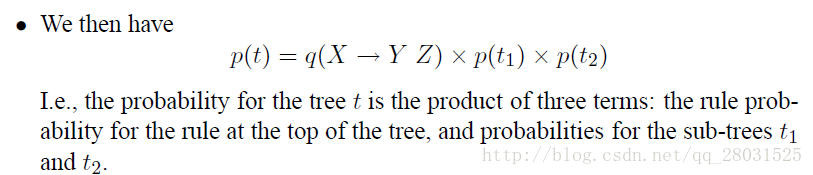
下面舉例說明:

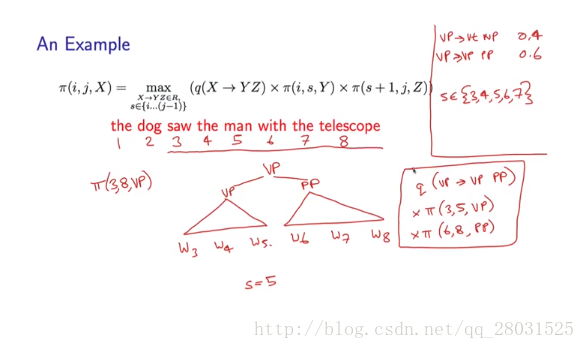
因此整個動態規劃演算法如下:

考慮演算法時間複雜度:
i,j,s的選擇都是o(n),對於X、Y和Z 和rules的選擇都是o(|N|)。(n是句子中單詞的數量,N是非終止符號的數量)

2.Lexical PCFG(基於詞典的PCFG)
首先考慮PCFG的缺陷:
1、在PCFG中,詞的選擇具有很強的獨立性假設,詞的選擇完全依賴於當前的詞性(POS),而條件獨立於與其他所有句法樹上的結構(More formally, the choice of each word in the string is conditionally independent of the entire tree,once we have conditioned on the POS directly above the word),而這正是很多歧義問題的原因。下例中,’IBM’的選擇僅僅與’NP’有關,而與其他樹上的結構完全無關。
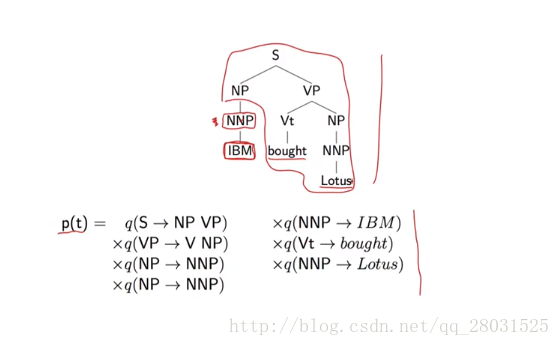
2、對結構偏好(structure preference)不敏感
對於存在歧義的兩個句子,具有完全相同的樹形結構,但是由於缺乏詞彙的資訊,進而缺少結構依賴的資訊,使得最終不同樹形結構計算的概率完全相同。
如下例中:同一句話,兩個完全不同的句法分析結構,由於採用了相同的rules,因此概率計算最終也會相同。
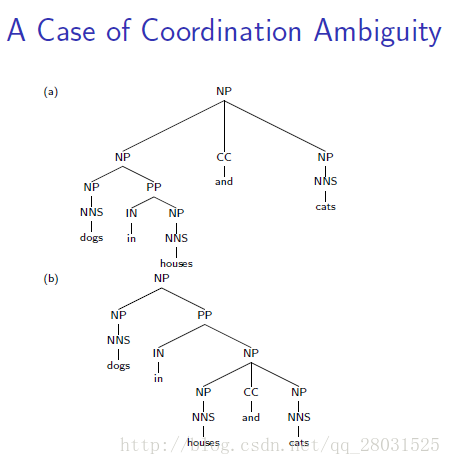
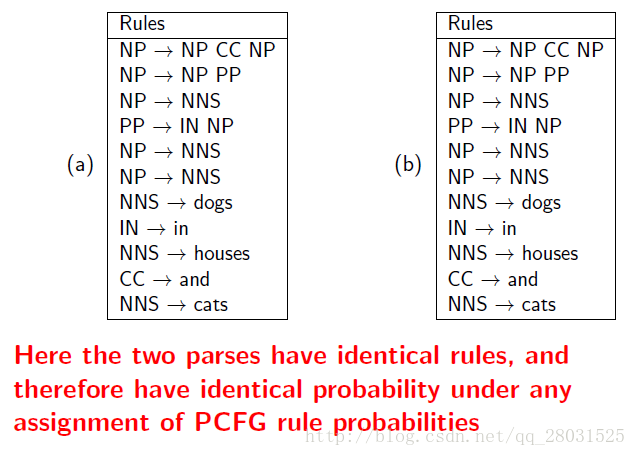
特別是介詞短語(PP)的情況,在訓練集中能統計到PP與名詞短語(NP)或動詞短語(VP)結合時不同的比例,但是PCFG完全忽略了這種偏好(preference)。
Lexicalized Context-Free
自下向上(bottom-up)的標記每條規則的head child,並新增到句法分析樹上,每條規則的head child採用啟發式自動選擇。
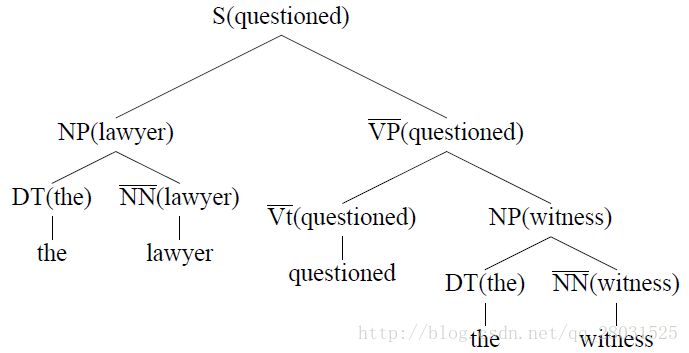

如下圖在基於詞典的PCFG中,規則概率如下:

基於詞典的PCFG的引數估計
由於採用lexicalized PCFG之後,添加了詞典資訊,rules的數量和引數數量增多。因此需要考慮引數估計方法。

整個概率計算分為兩部分,第一部分預測了規則(rules)的概率,第二部分預測了該規則下的詞概率,每部分都利用平滑的估計方法進行計算。


對於Lexical PCFG,同樣存在如何尋找概率最大的句法分析樹結構的問題,而答案和PCFG相同,一樣是採用動態規劃(dynamic programming)的思想。
3.Transition-based parsing(基於貪心決策動作的拼接句法樹)
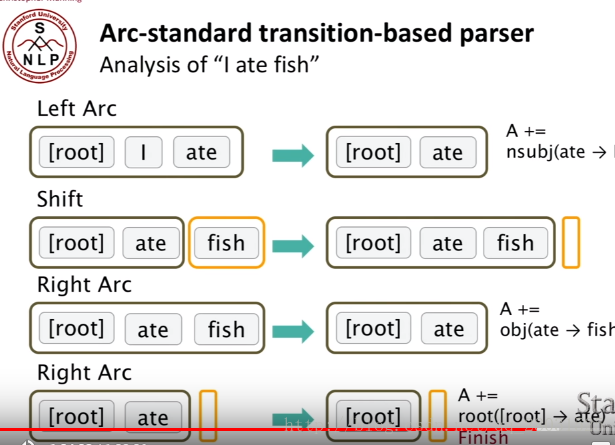
首先介紹Arc-standard transition,動作體系的formal描述如下:
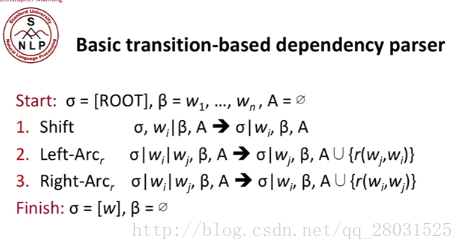
整個轉移過程中的三種動作:Shift, Left-Arc, Right-Arc。一個stack,Buffer(整個原始的句子)。
在arc-standard system中,一次分析任務由一個棧s,一個佇列b,一系列依存弧A構成。如果定義一個句子為單詞構成的序列那麼——
棧
棧s是用來儲存系統已經處理過的句法子樹的根節點的,初始狀態下。另外,定義從棧頂數起的第個元素為。那麼棧頂元素就是,的下一個元素就是:

在一些中文論文中習慣使用焦點詞這個表述,如果我們將棧橫著放,亦即讓先入棧的元素在左邊,後入棧的元素在右邊:

則稱為左焦點詞,為右焦點詞。接下來的動作都是圍繞著這兩個焦點詞展開的。
佇列
初始狀態下佇列就是整個句子,且順序不變,佇列的出口在左邊。
依存弧
一條依存弧有兩個資訊:動作型別+依存關係名稱I。l視依存句法語料庫中使用了哪些依存關係label而定,在arc-standard系統中,一共有如下三種動作:
LEFT-ARC(l):新增一條s1 -> s2的依存邊,名稱為l,並且將從棧中刪除。前提條件:。亦即建立右焦點詞依存於左焦點詞的依存關係,例如:

RIGHT-ARC(l):新增一條s2 -> s1的依存邊,名稱為l,並且將從棧中刪除。前提條件:。亦即建立左焦點詞依存於右焦點詞的依存關係,例如:

SHIFT:將b1出隊,壓入棧。亦即不建立依存關係,只轉移句法分析的焦點,即新的左焦點詞是原來的右焦點詞,依此類推。例如:

But How to check the next operation?(由於有三種動作,因此需要判斷在下一步動作的順序)。
Answer: 每一步動作都是由機器學習分類器得到的,如果我們得到treebank的句法分析樹結構,我們就能得到序列轉移或動作的順序,最終變成一個有監督學習問題。(Since we have a treebank with parses of sentences,We can use these sentences to see which sequences of operations would give the correct parse of a sentences.)
只是在該演算法提出之際,只是簡單的用到了傳統的機器學習方法。

當然由於在整個監督學習中,我們只是標識了轉移的方向,因此可以看做3分類問題,但是實際過程中,當我們從stack中移出元素時,我們通常標識的dependency關係可以達到40種之多,而這就是分類的標籤數量。
下面的一個重要的問題就是,How do we train the model,How do we choose the features?
一般而言,依存句法分析的可用特徵:
1. Bilexical affinities(雙詞彙親和)
2. Dependency distance(依存距離,一般傾向於距離近的)
3. Intervening material(標點符號兩邊的成分可能沒有相互關係)
4. Valency of heads (詞語配價,對於不同詞性依附的詞的數量或者依附方向)
傳統的特徵是棧和佇列中的單詞、詞性或者依存標籤等組合的特徵,是一組很長的稀疏向量。
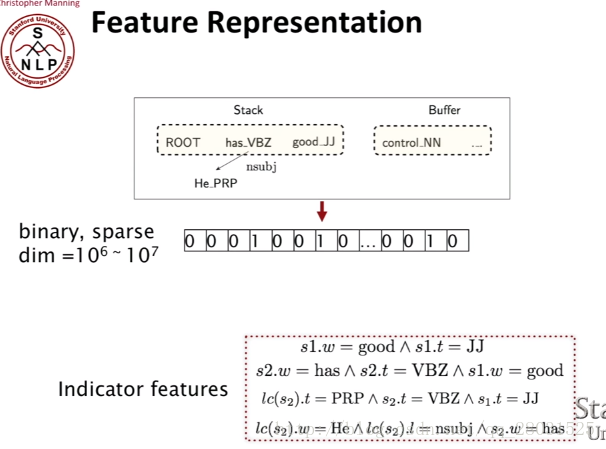
相比於使用大量的categorial (類別)特徵,導致特徵的sparse,使用神經網路可以使得特徵更加dense,使用distributed representation of words減少特徵的稀疏性。

