
NLP ---句法分析
句法分析是在計算機系統的基礎上進行發展的,常見的句法分析應用有: 計算機的翻譯、文字的註釋、一對一的問答系統、資訊的自然摘錄以及自動搜尋等。如果對句法分析這一詞不瞭解,那麼一定知道文法分析,這是該定義不同的兩個說法。句法分析說白了就是在一定規則的語法中,進行句子以及句法單位的自動識別,並按照規定輸出識別。常見的漢語理解是分幾個步驟的,一般都會包含待翻譯文章的輸入、文章詞句的切分、詞語屬性分析標註、生成目的標註等。長期以來句法的分析都是各個國家所研究的課題,也是公認的一個難題。句法分析的機器理念出自於 20 世紀的 50 年代,大概是在 60 年代時有了相應的成果。
句法分析的難點
( 一) 語句歧義
漢語言文化博大精深,很多詞都有多種意思,即便是一個很簡單的語句,都有可能有很多種的結果,所以句子語法的分析非常重要
( 二) 漢語的搜尋量太大
語法的分析是一個極其複雜的過程,一般完成一個語法的分析需要很多的資料支援,根據不同的語句長度也會有不同的資料要求
句法的機構

不同的漢語句法結構,會有不同的句法計算方式,所以先要了解句法的機構。短語結構語法和依存關係語法是現在常見的兩種語法關係,當然還有其他的句法體系,在此只做簡單的介紹,並不展開分析。短語結構語法擁有不同的層級,他們之間都是闡述了語法、語言和自動機之間的關係。短語結構語法呈現一個樹分類關係,句法根據一定的規則進行轉換分析。每一個詞的轉換都是需要按照設定的樹值規則進行目的性的轉換。
依存語法( 從屬關係語法) ,該項理論的提出是由法國的語言家———思尼耶爾提出的,在思尼耶爾提出的概念中,依存的語法句式結構表示的一個依存的關係,並不是一個句法樹。每一個依存都是由句子中的支配詞和從屬詞構成,沒有規定每一個語句的定義,也沒有明確的規則來對依存的關係進行進一步的確定標記。依存語法相較於短語結構更加的自由,所以其在近年來受到越來越多的專家學者的青睞,發展也較為迅速。
除了以上介紹的兩種句法體系外,國內外都開展了對句法分析的研究。不論是國外的美國鏈語法、範疇語法等,還是國內的 HNC 理論都是目前行業內常用的語法,只是由於設定區域的不同,所以使用有一定的侷限性。國外的兩種語法體系是由美國的 CMU 計算機學院提出的,國內的 HNC 理論則是由黃曾陽教授提出的 。
關於句法結構分析的詳細的講解請看宗老師的書,這裡就不敘述了,建議大家先看看CFG,這裡就不解釋了,他們都是基於文法的,更偏向於語言學,語言學不是我的專長,我擅長統計方面的,因此下面我們看看PCFG
PCFG(Probabilistic Context-Free Grammar,PCFG)
在統計語言模型中,原來比較常用的是隱馬爾可夫模型,但隱馬爾可夫模型的描述能力等價於隨機正則文法,它的描述能力是很有限的,它能統計詞與詞,詞性與詞性等短距離依賴,在統計詞間長距離依賴便遇到了困難,而且不能用隱馬爾可夫模型統計詞與短語、短語與短語的規約,不能使用這個模型來統計句法資訊和語義資訊。因此,基於概率的上下文無關語法
(Probabilistic Context-Free Grammar,PCFG)和隨機正則文法在計算語言學領域受到了廣泛的關注。基於概率的上下文無關語法可以直接統計語言學中詞與詞、詞與片語以及片語與片語規約資訊,並且可以統計由語法規則生成給定句子的概率、一個給定句子最可能的分析、以及由語法規則生成字首和字尾的概率等等。大家結合宗老師的來看會更好:
原理介紹
為了清楚的介紹概率上下文無關語法,首先對本文要使用的記號做一些說明,如表3-1所示:

概率上下文無關語法是上下文無關語法的一種擴充套件,一個概率上下文無關語法是一個四元組:
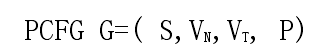
其中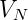
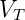
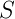
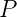
![]() ,
,![]() 是終結符號和非終結符號組成的符號串,
是終結符號和非終結符號組成的符號串,![]() 是產生式的概率,並且有 :
是產生式的概率,並且有 :
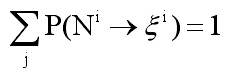
概率上下文無關語法的規則可分為兩類,一部分規則的右端出現的是某種語言中的詞彙,這些規則可以成為詞彙規則;另一部分規則的左端出現的是詞彙類別或短語類別符號,一般稱為語法規則。 語法的作用在於幫助進行句子的句法分析,概率上下文無關語法也是這樣。依據概率上下文無關語法進行句子的句法分析,首先要得到該句子的句法分析樹,這與利用上下文無關語法分析句子類似。 在自然語言中,歧義現象是天然地大量存在著的,而且這些歧義的解釋往往都有可能是合理的,因此,對歧義現象的處理是自然語言句法分析器最本質的要求。人們正常交流中所使用的語言,放在特定的環境下看,一般是沒有歧義的,否則人們將無法交流(某些特殊情況如幽默或雙關語除外),如果不考慮語言所處的環境和語言單位的上下文,將會發現語言的歧義現象無所不在。
一般來說,語言單位的歧義現象在引入更大的上下文範圍或者語言環境時總是可以被被消解的。句法分析的核心任務就是消解一個句子在句法結構上的歧義。 概率上下文無關語法提供了一條解決句法排歧問題的途徑。概率型上下文無關語法通過為每條產生式規則指派一個概率值,擴充套件了標準的上下文無關語法(CFG)描述體系,即PCFG為CFG中的每條規則增加一個概率值。
可以表示為![]() ,並且滿足以下的概率一致化條件:
,並且滿足以下的概率一致化條件:![]() 。利用這個分佈概率值,我們可以很方便地應用概率論中很完備的計算工具來完成句法排歧任務。即利用附在每條規則後的概率值給每棵分析樹計算出一個概率值,利用這個概率值作為評價分析樹的依據,擁有最大概率值的分析樹就是最可能的分析樹。 計算一個句子的概率,最為直接的方法是通過計算出這個句子所有可能的分析樹的概率,然後對它們求和。
。利用這個分佈概率值,我們可以很方便地應用概率論中很完備的計算工具來完成句法排歧任務。即利用附在每條規則後的概率值給每棵分析樹計算出一個概率值,利用這個概率值作為評價分析樹的依據,擁有最大概率值的分析樹就是最可能的分析樹。 計算一個句子的概率,最為直接的方法是通過計算出這個句子所有可能的分析樹的概率,然後對它們求和。
例項
在本文產生式規則所用符號說明,如表3-2所示:

下面是一組產生式規則:
上下文無關文法(CFG)的產生式規則如下:
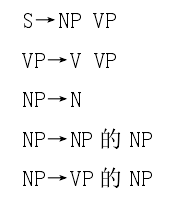
概率上下文無關語法的產生式規則如下:

下面是對句子“老虎咬死了獵人的狗。”的概率計算。圖 3-2 是例句的詞性標註。

例句的概率P(S)為:
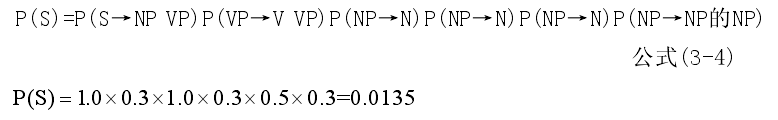
PCFG三個假設 :
使用概率上下文無關語法進行句法分析,需要先做如下三個假設。
位置無關性假設
子結點概率與子結點所管轄的字串在句子中的位置無關,即![]() 相同。
相同。
下面的例子說明假設1)的含義。對於句子:
![]()
有如圖句法結構樹。

在句子的位置1,有一個ART1→a,在位置4也有一個ART2→a,可以看成是結點ART處在句子的不同位置,但只要他們的管轄的結點都是相同的(即用了相同的詞彙規則),則每個ART結點的概率均相同。也就是說ART只與其管轄的詞a有關,而與該詞在句子中所處的位置無關。對於句法樹中出現的兩個NP也是一樣的情況,由於兩個NP均管轄相同的串(ART N),可看成是結點NP處在句子的不同位置,它們的概率依據假設也是相同的。
上下文無關假設
子結點概率與不受子結點管轄的其他符號串無關,即

例如,在上面例句中,如果把saw換成bought,ART,NP等結點的概率值保持不變。該假設是上下文無關假設在概率上的體現,不僅重寫規則是上下文無關的,而且重寫規則的概率也是無關的。
祖先結點無關性假設
子結點概率與匯出該結點的所有祖先結點的概率無關。
有了這三個假設,概率上下文無關語法就不僅繼承了語法本身(無附帶概率時)的上下文無關,還使得概率值也能夠上下文無關的相同使用。這樣就可以利用概率上下文無關語法的句法分析演算法,得到句子的句法分析樹;然後,為每個結點附帶一個概率值,在上述三個假設下,每個結點的概率值就是對該結點進行進一步重寫所使用的規則後面附帶的概率。
三個基本問題
給定一個符號串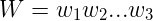
1) 如何快速計算由G產生符號串W的概率P(W|G)?
2) 如果W有多種可能的語法樹,如何選擇一棵最好的樹?
3) 如何調整G的規則概率引數,使得P(W|G)最大?
為了解決上面的三個問題,下面介紹本系統用的三種概率上下文無關語言的基本演算法。其中包括向內演算法,viberbi 演算法,向內-向外演算法。
向內演算法
所示非終結符A的內部概率(inside probability)定義為:根據文法G從A推出詞串…的概率,記做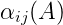

向內演算法公式:
![]()
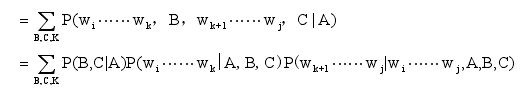
利用獨立性假設可以推導成下式:
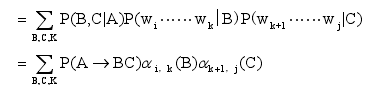
當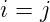

向內演算法的過程描述:(自底向上)

Viterbi演算法
通過 Viterbi 演算法可以有效地找出最為可能的分析樹。為了介紹該演算法,首先引入變數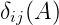
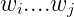
產生出詞串

不解釋了,不理解維特比演算法的建議看我起前面的部落格,我有詳細講解過,這裡直接給出步驟了。維特比演算法詳解
向內-向外演算法
圖 4-3 所示非終結符 A 的外部概率(outside probability)定義為:根據文法 G 從 A 推出詞串 
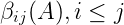
外部概率公式如下:
以上述例句“John ate fish with bone。”為例,通過向內向外演算法分析如下:

好了 ,本節就到這裡,這裡的三個問題可以類比於隱馬爾可夫的問題,結合理解就容易了。