
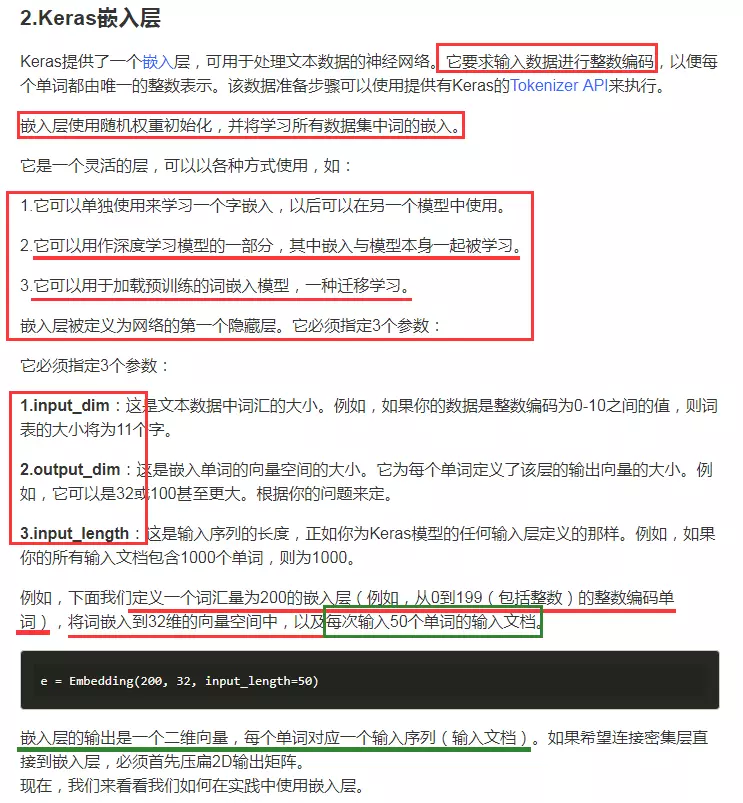
word embeddding和keras中的embedding

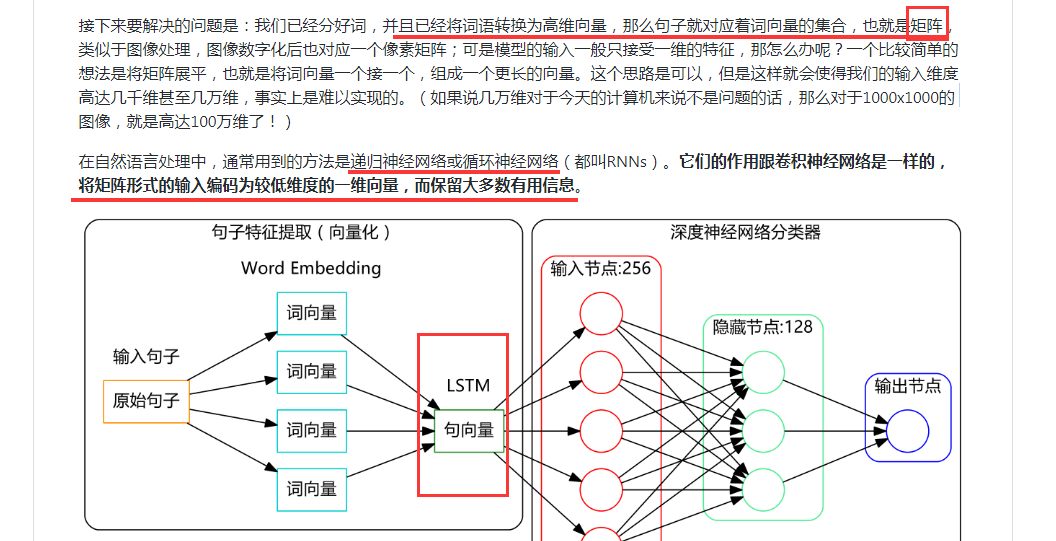
通過上面我們可以拿到每個詞的詞向量,但是我們任務處理時一般是對句子或文字進行操作。當我們拿到一個詞向量後,那麼一個句子或一個文字就可以用詞表示成矩陣(假設一個句子有5個詞,詞向量維度是64,那麼該矩陣就是5*64),然後可以用CNN或RNN(LSTM)模型將該矩陣編碼成一個一維向量,並保留大多數文字資訊。然後將該向量作為深度神經網路分類器的輸入,即可得到最終的結果。
轉載:https://www.jianshu.com/p/b2c33d7e56a5
相關推薦
word embeddding和keras中的embedding
訓練好的詞向量模型被儲存下來,該模型的本質就是一個m*n的矩陣,m代表訓練語料中詞的個數,n代表訓練時我們設定的詞向量維度。當我們訓練好模型後再次呼叫時,就可以從該模型中直接獲取到對應詞的詞向量。 通過上面我們可以拿到每個詞
深度學習基礎系列(五)| 深入理解交叉熵函式及其在tensorflow和keras中的實現
在統計學中,損失函式是一種衡量損失和錯誤(這種損失與“錯誤地”估計有關,如費用或者裝置的損失)程度的函式。假設某樣本的實際輸出為a,而預計的輸出為y,則y與a之間存在偏差,深度學習的目的即是通過不斷地訓練迭代,使得a越來越接近y,即 a - y →0,而訓練的本質就是尋找損失函式最小值的過程。 常見的
keras中的Flatten和Reshape
其他 個數 如果 tensor res sha 模型 flatten 函數 最近在看SSD源碼的時候,就一直不理解,在模型構建的時候如果使用Flatten或者是Merge層,那麽整個數據的shape就發生了變化,那麽還可以對應起來麽(可能你不知道我在說什麽)?後來不知怎麽的
NER 中word數量和tag數量不一致解決方案以及tf.string_split用法
句子中有中文空格 而tf.string_split(source, delimiter=’ ‘)預設是英文空格 導致NER 中word數量和tag數量不一致。 tf.string_split(source, delimiter=' ') source是一維陣列,用於將一組字串
keras中的model.fit和model.fit_generator
fit(self, x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weig
神經網路中embedding層作用——本質就是word2vec,資料降維,同時可以很方便計算同義詞(各個word之間的距離),底層實現是2-gram(詞頻)+神經網路
Embedding tflearn.layers.embedding_ops.embedding (incoming, input_dim, output_dim, validate_indices=False, weights_init='truncated_norm
Python機器學習筆記:深入理解Keras中序貫模型和函式模型
先從sklearn說起吧,如果學習了sklearn的話,那麼學習Keras相對來說比較容易。為什麼這樣說呢? 我們首先比較一下sklearn的機器學習大致使用流程和Keras的大致使用流程: sklearn的機器學習使用流程: 1 2 3 4
keras中model.evaluate 和 model.predict的區別
The model.evaluate function predicts the output for the given input and then computes the metrics function specified in the mod
[6]深度學習和Keras---- 深度學習中的一些難理解的基礎概念:softmax, batch,min-batch,iterations,epoch,SGD
在進行深度學習的過程中,我們經常會遇到一些自己不懂的概念和術語,比如,softmax, batch,min-batch,iterations,epoch,那麼如何快速和容易的理解這些術語呢? 因為筆者也是深度學習的初學者,所以筆者在學習和瀏覽文章的過程中,把一些自己不太容易和
word中字型大小(pt)和網頁中css設定font-size時用的px大小對應關係
pt與px轉換關係為 1px= 0.75pt。 所以word中五號字型(10.5pt)在網頁中對應的大小為font-size:14px。(10.5 / 0.75 = 14) 初號44pt 小初36pt 一號26pt 小一24pt 二號22pt 小二18pt 三號16pt 小
Keras中Conv1D和Conv2D的區別
如有錯誤,歡迎斧正。 我的答案是,在Conv2D輸入通道為1的情況下,二者是沒有區別或者說是可以相互轉化的。首先,二者呼叫的最後的程式碼都是後端程式碼(以TensorFlow為例,在tensorflow_backend.py裡面可以找到): x = tf.nn.convo
利用keras中image.ImageDataGenerator.flow_from_directory()實現從資料夾中提取圖片和進行簡單歸一化處理
keras中有很多封裝好的API可以幫助我們實現對圖片資料的讀取和處理。 比如 : keras.preprocessing.image.ImageDataGenerator.flow_from_dir
css中的word-spacing和letter-spacing
1.word-spacing 的字間距的字說的是每個單詞之間的空白,對中文無效。 比如: <p style="word-spacing: 70px">hello World</p>效果就是: hello W
Keras 中 TimeDistributed 和 TimeDistributedDense 理解
team feed each possible dont app arpa https atom From the offical code: class TimeDistributed(Wrapper): """This wrapper applies a
mysql和mariadb中字段拼接類型有兩個或多個字段或者一個字段和一個固定字符串拼接
str1 from 連接 字符串連接 一個 cat str 拼接 str2 MySQL中concat函數 CONCAT(str1,str2,…) 1 .兩個或多個字段連接 例:字段 a,b 表 tb1 語句: select conca
JavaScript 設計模式入門和框架中的實踐 http://www.codeceo.com/article/javascript-design-pattern.html
{} static log block 抽象 listener args assign ack 在編寫JS代碼的過程中,運用一定的設計模式可以讓我們的代碼更加優雅、靈活。 下面筆者就結合諸如redux的subscribe、ES6的class、vue裏面的$dispatch、
wprintf、wcout輸出中文和unicode中文字符串的轉換問題
fan 5% 轉換問題 int 字符串 ssa dst unicode zed %E4%BD%BF%E7%94%A8CHttpFile%E4%BB%8E%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%AB%AF%E6%AD%A3%E7%A1%AE%E7%9A%
response.getWriter()和jsp中out對象的區別
內置對象 而是 getwriter int() nbsp 返回 代碼 頁面 cep 兩者的主要區別:1.內置對象out的類型是JspWriter; response.getWrite()返回的類型是PrintWriter; out和response.getWriter的類不
response.getWriter()和jsp中的out對象的區別
抽象 執行 resp 屬於 依賴 需要 int bsp write (1) out和response.getWriter屬於的類不同,前者是JspWriter,後者是java.io.PrintWriter。而JspWriter是一個抽象類, PrintWriter是一個繼承
HTML和CSS中的居中效果(1)
htm inner height overflow n-1 txt posit splay read HTML和CSS中的居中效果 單行上下左右居中 Html: <div class=”container”></div> CSS: