
GC調優一:GC演算法實現
轉自:https://blog.csdn.net/dabokele/article/details/60601818
在瞭解了上一章中GC演算法的基本概念之後,本章將深入到各GC演算法的具體實現中。對大多數JVM來說,一般需要選擇兩種GC演算法,一種用於回收新生代記憶體區,另一種用於回收老年代記憶體區域。
新生代和老年代GC演算法的可能組合如下表所示,如果不指定的話,將會在新生代和老年代中選擇預設的GC演算法。下表中的GC演算法組合是基於Java 8的,在其他Java版本中可能會有所不同。
| 新生代GC演算法 | 老年代GC演算法 | JVM引數 |
|---|---|---|
| Incremental | Incremental | -Xincgc |
| Serial | Serial | -XX:+UseSerialGC |
| Parallel Scavenge | Serial | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| Parallel New | Serial | N/A |
| Serial | Parallel Old | N/A |
| Parallel Scavenge |
Parallel Old | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| Parallel New | Parallel Old | N/A |
| Serial | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| Parallel Scavenge | CMS | N/A |
| Parallel New | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| G1 | -XX:+UseG1GC |
如果現在覺得上表看起來覺得很複雜,請彆著急。一般常用的是上面加粗的四種組合。剩下的組合一般是已經不用了,或者是不再支援,或者在實際中基本不使用。所以,在接下來的文章中,只介紹上面這四種組合。
- 新生代和老年代的序列GC(Serial GC)
- 新生代和老年代的並行GC(Parallel GC)
- 新生代並行GC(Parallel GC) + 老年代CMS
- 部分新生代老年代的G1
一、序列GC(Serial GC)
序列GC對於新生代使用標記複製(mark-copy)策略,對老年代使用標記清除整理(mark-sweep-compact)策略進行垃圾回收。這些收集器是單執行緒的,不能併發的對垃圾進行回收。並且在垃圾回收動作時會暫停整個應用執行緒(stop-the-world)。
這種GC演算法無法充分利用硬體資源,即使有多個核,在GC時也只用其中一個。在新生代和老年代啟動序列GC的命令如下:
java -XX:+UseSerialGC com.mypackages.MyExecutableClass這種GC演算法一般並不常用,只有在堆記憶體為幾百MB,並且應用執行在單核CPU上時才使用。一般應用都部署在多核的伺服器上,如果使用序列GC會在GC時無法充分利用資源,造成效能瓶頸,提高應用延遲和降低吞吐量。
接下來我們看一個序列GC的垃圾收集日誌資訊,使用如下命令使應用打印出GC日誌,
-XX:+PringGCDetails -XX:+PringGCDateStamps -XX:+PringGCTimeStamps輸出日誌如下,
2015-05-26T14:45:37.987-0200: 151.126: [GC (Allocation Failure) 151.126: [DefNew:629119K->69888K(629120K), 0.0584157 secs] 1619346K->1273247K(2027264K), 0.0585007 secs][Times: user=0.06 sys=0.00, real=0.06 secs]
2015-05-26T14:45:59.690-0200: 172.829: [GC (Allocation Failure) 172.829: [DefNew:629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs] 1832479K->755802K(2027264K), [Metaspace:6741K->6741K(1056768K)], 0.1856954 secs] [Times: user=0.18 sys=0.00, real=0.18 secs]從上面這段日誌資訊中可以看到進行了兩次GC,第一次清理了新生代,第二次清理了新生代和老年代空間。
1、Minor GC
清理新生代記憶體的GC事件日誌如下,

對照上面的不同欄位進行說明,
(1)2015-05-26T14:45:37.987-0200,發生本次GC動作的時間
(2)151.126,GC事件發生時距離該JVM啟動的時間,單位為秒
(3)GC,用於區分是Minor GC還是Full GC。這裡表示本次是Minor GC
(4)Allocation Failure,導致本次進行GC的原因。在這裡,本次GC是由於無法為新的資料結構在新生代中分配記憶體空間導致的。
(5)DefNew,垃圾收集器的名稱。這個名稱表示的是在新生代中進行的單執行緒,標記-複製,全應用暫停的垃圾收集器
(6)629119K->69888K,表示新生代記憶體空間在GC前後的大小。
(7)629120K,表示新生代的總大小
(8)1619346K->1273247K,堆記憶體在GC前後的大小
(9)2027264K,堆記憶體中可用大小
(10)0.0585007 secs,GC動作的時間,單位為秒
(11)Times: user=0.06 sys=0.00, real=0.06 secs,GC動作的時間,其中
user- 表示在此次垃圾回收過程中,所有GC執行緒消耗的CPU時間之和sys- 表示GC過程中作業系統呼叫和系統等等事件所消耗的時間-
real- 應用暫停的總時間。由於序列GC是單執行緒的,所以暫停總時間等於user時間和sys時間之和
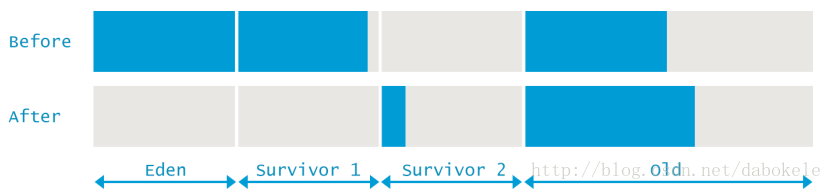
經過上面這些分析後,我們可以更加清楚的從GC日誌中獲取到當時的詳細資訊。在GC前,總共使用了1619346K堆記憶體,其中新生代使用了629119K。通過計算就可以得到老年代使用了990227K。GC後,新生代釋放出了559231K記憶體空間,但是堆的總記憶體僅僅釋放了346099K。也就是說,在本次GC時,有213132K的物件從新生代升級到了老年代區域。
下圖形象的表明了本次GC前後記憶體的變化情況。
2、Full GC
理解了Minor GC事件後,接下來我們看一下第二次GC的日誌,

對上面各組資料進行分析,
(1)2015-05-26T14:45:59.690-0200,本次GC事件發生的時間
(2)172.829,GC時JVM的啟動總時間,單位為秒。
(3)[DefNew: 629120K->629120K(629120K), 0.0000372 secs,由於分配記憶體不足導致的一次新生代GC。在本次GC時,首先進行的是新生代的DefNew型別GC,將新生代的記憶體使用從629120K降低到0。注意在這裡,JVM的顯示有問題,誤認為年輕代記憶體使用完了。本次GC耗時0.0000372秒
(4)Tenured,老年代垃圾收集器的名稱。Tenured表示一個單執行緒,暫停整個應用執行緒的標記清除整理的垃圾收集過程。
(5)1203359K->755802K,老年代在垃圾回收前後的記憶體使用情況
(6)1398144K,老年代總記憶體數
(7)0.1855567 secs,老年代垃圾回收的耗時
(8)1832479K->755802K,垃圾回收前後總堆記憶體的變化情況(包括新生代和老年代)
(9)2027264K,JVM堆的可用記憶體
(10)[Metaspace: 6741K->6741K(1056768K)],元資料區在垃圾回收前後的記憶體使用情況,從這裡可以看出,本次GC時並沒有對元資料區的記憶體進行回收
(11)[Times: user=0.18 sys=0.00, real=0.18 secs],GC事件的耗時,
user- 表示在此次垃圾回收過程中,所有GC執行緒消耗的CPU時間之和sys- 表示GC過程中作業系統呼叫和系統等等事件所消耗的時間real- 應用暫停的總時間。由於序列GC是單執行緒的,所以暫停總時間等於user時間和sys時間之和
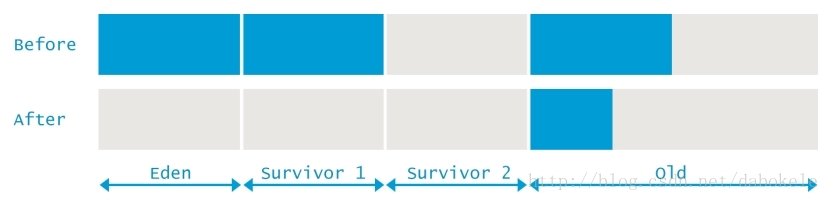
本次Full GC與上面的Minor GC區別十分明顯,Full GC是會對老年代和元資料區進行垃圾回收的。本次垃圾回收的過程如下圖所示,
二、並行GC(Parallel GC)
在這種GC模式下,新生代使用標記複製策略,老年代使用標記清除整理策略。新生代和老年代的GC事件都會導致所有應用執行緒暫停。新生代和老年代在複製(copy)或整理(compact)階段都使用多執行緒,這也是並行GC名稱的來由。使用這種GC演算法,可以降低垃圾回收的時間消耗。
在垃圾回收時的並行執行緒數,可以由引數-XX:+ParallelGCThreads=NNN來設定。該引數的預設值是伺服器的核數。
使用並行GC,可以用以下三種命令模式:
java -XX:+UseParallelGC com.mypackages.MyExecutableClass
java -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
java -XX:+UseParallelGC -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
並行垃圾收集器一般用在多核伺服器上,在多核伺服器上使用並行GC,能重複利用硬體資源,提高應用的吞吐量,
- 在垃圾收集過程中,會利用所有的核並行進行垃圾回收動作,降低應用暫停時間
- 在垃圾回收間歇期,垃圾收集器不工作,不會消耗系統資源
另一方面,並行GC的所有階段都不能被中斷,所以這些垃圾收集器仍然有可能在所有應用執行緒停止時陷入長時間的暫停中。所以,如果要求系統低延遲,那麼不建議使用這種垃圾收集器。
接下來,我們看一下並行GC時的日誌資訊。如下所示,
2015-05-26T14:27:40.915-0200: 116.115: [GC (Allocation Failure) [PSYoungGen: 2694440K->1305132K(2796544K)] 9556775K->8438926K(11185152K), 0.2406675 secs] [Times: user=1.77sys=0.01, real=0.24 secs]
2015-05-26T14:27:41.155-0200: 116.356: [Full GC (Ergonomics) [PSYoungGen: 1305132K->0K(2796544K)] [ParOldGen: 7133794K->6597672K(8388608K)] 8438926K->6597672K(11185152K),[Metaspace: 6745K->6745K(1056768K)], 0.9158801 secs] [Times: user=4.49 sys=0.64,real=0.92 secs]1、Minor GC
接下來詳細分析Minor GC時的日誌資訊。

(1)2015-05-26T14:27:40.915-0200,本次GC事件發生的時間
(2)116.115,GC時JVM的啟動總時間,單位為秒。
(3)GC,用於區分Minor GC和Full GC。這裡表示本次為Minor GC
(4)Allocation Failure,導致本次GC的原因。是由於新生代中無法為新物件分配記憶體
(5)PSYoungGen,垃圾收集器的名稱,這裡表示這是一個並行標記複製,暫停全部應用的新生代垃圾收集器
(6)2694440K->1305132K,GC前後新生代的記憶體空間使用量
(7)2796544K,新生代總記憶體量
(8)9556775K->8438926K,垃圾回收前後總堆記憶體的變化情況(包括新生代和老年代)
(9)11185152K,JVM堆的可用記憶體
(10)0.2406675 secs,GC事件的耗時
(11)[Times: user=1.77 sys=0.01, real=0.24 secs],GC事件的耗時,
user- 表示在此次垃圾回收過程中,所有GC執行緒消耗的CPU時間之和sys- 表示GC過程中作業系統呼叫和系統等等事件所消耗的時間-
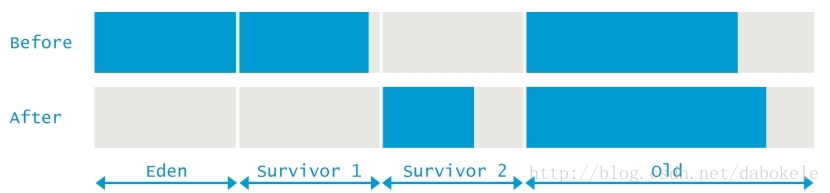
real- 應用暫停的總時間。在並行GC中,這個數值應該接近於(user + sys) / GC執行緒數。即單個核上平均的暫停時間,在這裡執行緒數為8。由於某些過程是不能並行執行的,所以這個值會比剛才求的均值略高。總結一下本次GC過程就是,在GC前整個堆記憶體使用了9556775K,其中新生代使用了2694440K,那麼老年代使用了6862335K。新生代的GC導致新生代釋放了1389308K的空間,但是堆的總空間只釋放了1117849K。這意味著有271459K的物件從新生代升級到了老年代中,整個過程如下圖所示,
2、Full GC
在理解了新生代的並行GC過程後,我們接下來分析一些並行GC在Full GC時的表現,

(1)2015-05-26T14:27:41.155-0200,本次GC事件發生的時間
(2)116.356,GC時JVM的啟動總時間,單位為秒。
(3)Full GC,表示本次是一次Full GC,將會對新生代和老年代的記憶體空間進行回收
(4)Ergonomics,本次GC的觸發原因。這裡是由於JVM認為此刻是一次適合進行垃圾回收的時間
(5)[PSYoungGen: 1305132K->0K(2796544K)],垃圾收集器的名稱。PSYoungGen表示這是一次新生代中進行的標記複製,暫停全部應用的新生代GC。新生代的記憶體空間使用量從1305132K降低到0。一般來說,進行了一次Full GC後,新生代的記憶體空間將會被全部清理。
(6)ParOldGen,老年代中的垃圾收集器型別。在這裡ParOldGen表示在老年代中使用的標記清除整理,暫停全部應用的老年代垃圾收集器。
(7)133794K->6597672K,老年代垃圾回收前後的記憶體使用情況
(8)8388608K,老年代的總記憶體大小
(9)8438926K->6597672K,垃圾回收前後總堆記憶體的變化情況(包括新生代和老年代)
(10)11185152K,JVM堆的總記憶體
(11)[Metaspace: 6745K->6745K(1056768K)],元資料區在垃圾回收前後的記憶體使用情況,從這裡可以看出,本次GC時並沒有對元資料區的記憶體進行回收
(12)0.9158801 secs,本次GC的耗時,單位為秒
(13)[Times: user=4.49 sys=0.64,real=0.92 secs],GC事件的耗時,
user- 表示在此次垃圾回收過程中,所有GC執行緒消耗的CPU時間之和sys- 表示GC過程中作業系統呼叫和系統等等事件所消耗的時間real- 應用暫停的總時間。在並行GC中,這個數值應該接近於(user + sys) / GC執行緒數。即單個核上平均的暫停時間,在這裡執行緒數為8。由於某些過程是不能並行執行的,所以這個值會比剛才求的均值略高。
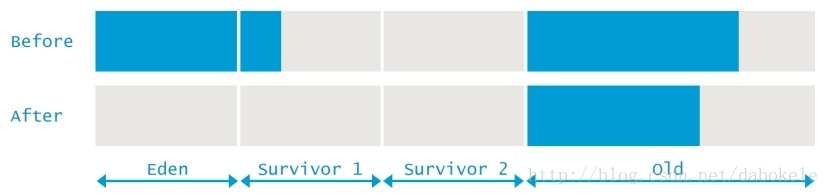
並行GC過程中的Full GC也與Minor GC有些不同。Full GC不僅會對新生代進行垃圾回收,也會清理老年代和元資料區。在Full GC前後,JVM各區記憶體變化情況如下圖所示,
三、併發標記清除CMS(Concurrent Mark and Sweep)
CMS垃圾收集器在新生代使用stop-the-world的並行標記複製演算法,在老年代使用併發的標記清除演算法。
這種收集器可以避免在回收老年代空間時出現的長時間暫停。這主要是由於:(1)不對老年代的空間進行整理,而是使用一個空閒列表(free-lists)來管理這些被回收的空間。(2)標記清除階段與應用並行進行。這意味著CMS垃圾收集器在回收老年代空間時完全不會停止應用執行緒,並且使用多執行緒來完成這些操作。預設情況下,併發執行緒數為當前機器物理核的1/4。
要使用CMS垃圾收集器的話,可以使用如下引數
java -XX:+UseConcMarkSweepGC com.mypackages.MyExecutableClass 如果應用執行在多核機器上,並且對系統的延遲效能要求比較高,那麼就很適合使用這種垃圾收集器。但是,由於CMS垃圾收集器在大部分時候總會有一些CPU資源正在進行GC操作,所以勢必會降低系統的吞吐量。
接下來我們看一些CMS在垃圾回收時生成的日誌資訊,
2015-05-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs][Times: user=0.78 sys=0.01, real=0.11 secs]
2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark:10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]
2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times:user=0.07 sys=0.00, real=0.03 secs]
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs][Times: user=0.02 sys=0.00, real=0.02 secs]
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K(613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing,0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark:10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00,real=0.01 secs]
2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times:user=0.03 sys=0.00, real=0.03 secs]
2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times:user=0.01 sys=0.00, real=0.01 secs]1、Minor GC
在上面的GC日誌中,最前面就能看到一次回收新生代空間的Minor GC,接下來我們詳細分析一些這段GC日誌的每一部分具體含義

(1)2015-05-26T16:23:07.219-0200,本次GC事件發生的時間
(2)64.322,GC時JVM的啟動總時間,單位為秒
(3)GC,區分Minor GC和Full GC的標識,在這裡表示這是一次Minor GC
(4)Allocation Failure,本次GC的觸發原因。在這裡是由於新生代無法為新生成的物件分配記憶體空間
(5)ParNew,垃圾收集器的名稱。在這裡表示這是一次在新生代中進行的並行標記複製,stop-the-world的垃圾回收。一般與老年代中的併發標記清除垃圾收集器配合使用。
(6)613404K->68068K,新生代垃圾回收前後的記憶體使用情況
(7)613440K,新生代的總記憶體大小
(8)0.1020465 secs,在W/O final cleanup階段的總耗時
(9)10885349K->10880154K,垃圾回收前後總堆記憶體的變化情況(包括新生代和老年代)
(10)12514816K,JVM堆的總記憶體
(11)0.1021309 secs,新生代垃圾回收過程中在標記和複製存活物件階段的耗時。包括與ConcurrentMarkSweep收集器的通訊消耗,提升足夠老的物件到老年代,以及最終在垃圾收集週期中對不再使用物件進行清理的耗時
(13)[Times: user=0.78 sys=0.01, real=0.11 secs],GC事件的耗時,
user- 表示在此次垃圾回收過程中,所有GC執行緒消耗的CPU時間之和sys- 表示GC過程中作業系統呼叫和系統等等事件所消耗的時間-
real- 應用暫停的總時間。在並行GC中,這個數值應該接近於(user + sys) / GC執行緒數。即單個核上平均的暫停時間,在這裡執行緒數為8。由於某些過程是不能並行執行的,所以這個值會比剛才求的均值略高。從上面的分析過程中可以看出,在本次垃圾回收前,堆記憶體總共使用了10885349K,其中新生代使用了613404K,那麼老年代使用了10271945K。垃圾收集後,新生代空間的使用量減少了545336K,但是整個堆記憶體空間使用量僅僅減少了5195K。也就是說,在新生代中有540141K的由於存活時間太長,被移動到老年代空間中。
2、Full GC
接下來要分析的Full GC的日誌,與前面看到的日誌不同。CMS的Full GC日誌資訊由老年代中併發執行的不同垃圾回收階段組成。
2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark:10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]
2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times:user=0.07 sys=0.00, real=0.03 secs]
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs][Times: user=0.02 sys=0.00, real=0.02 secs]
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K(613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing,0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark:10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00,real=0.01 secs]
2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times:user=0.03 sys=0.00, real=0.03 secs]
2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times:user=0.01 sys=0.00, real=0.01 secs] 接下來會分階段對這些日誌資訊進行詳細的分析。
階段一:初始標記(Initial Mark)
這一步是CMS垃圾收集過程中兩次stop-the-world的其中一次。目的是找到垃圾收集器的roots物件。
2015-05-26T16:23:07.321-0200: 64.425$^1$: [GC (CMS Initial Mark$^2$) [1 CMS-initial-mark:10812086K$^3$(11901376K)$^4$] 10887844K$^5$(12514816K)$^6$, 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]$^7$(1)2015-05-26T16:23:07.321-0200: 64.425,GC事件的開始時間,最後面的數字表示該JVM的啟動時間。後續日誌資訊中這個時間串都表示相同含義。
(2)CMS Initial Mark,標識本次垃圾收集的階段。initial mark階段的目的是找到垃圾收集器的roots物件。
(3)10812086K,當前使用的老年代記憶體空間
(4)11901376K,當前老年代可用記憶體空間
(5)10887844K,當前使用的整個堆記憶體空間
(6)12514816K,當前堆可用空間
(7)0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs],初始標記階段的耗時,也由user,sys和real三部分組成。
階段二:併發標記(Concurrent Mark)
這個階段垃圾收集器將會遍歷老年代中的所有物件,然後標記其中哪些物件仍然存活。判斷物件是否存活將參考當前物件是否直接或間接的被上一階段中找出的Roots物件所引用。這一階段的動作將與應用執行緒並行進行。
2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark$^1$: 0.035/0.035 secs$^2$] [Times:user=0.07 sys=0.00, real=0.03 secs]$^3$(1)CMS-concurrent-mark,CMS垃圾收集器的併發標記階段。遍歷老年代中所有物件,標記其中存活的物件,這一階段併發執行,並且不會stop-the-world
(2)0.035/0.035 secs,這一階段的持續時間,分別是執行時間和相應的實際時間
(3)[Times:user=0.07 sys=0.00, real=0.03 secs],記錄了併發標記階段從開始到結束的總時間。在併發標記階段,這段資訊沒什麼參考價值,因為這段時間內不僅併發標記在進行,程式也在並行執行。
階段三:併發預清理(Concurrent Preclean)
這一階段也是一個併發階段,與應用執行緒併發執行,不會將應用執行緒暫停。當階段二在併發標記時,隨著應用的執行,也可能會改變某些物件的引用狀況。比如標記為存活的物件,或許已經被遺棄,比如被遺棄的物件又被重新使用等。這些引用狀況發生變化的物件將被JVM標記為drity(即所謂的Card Marking)。在併發預清理階段,這些物件將被標記為存活,即使可能會出現將垃圾物件也標記為存活。此外, 本階段也會執行一些必要的細節處理,併為 Final Remark 階段做一些準備工作。
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean$^1$: 0.016/0.016 secs$^2$][Times: user=0.02 sys=0.00, real=0.02 secs]$^3$(1)CMS-concurrent-preclean,表示此次為併發預清理階段,找出在階段二中標記過之後引用狀態發生變化的物件
(2)0.016/0.016 secs,本階段的耗時
(3)[Times: user=0.02 sys=0.00, real=0.02 secs],記錄了併發與清理階段從開始到結束的總時間。在併發預處理階段,這段資訊沒什麼參考價值,因為這段時間內不僅併發預處理在進行,程式也在並行執行。
階段四:併發可取消預清理(Concurrent Aboartable Preclean)
這一階段同樣不會暫停應用執行緒,主要用於儘可能少的減少Final Remark階段的工作量,以減少stop-the-world的時間。這一階段會迴圈重複相同的動作,直到迴圈次數,有用工作量,消耗的系統時間達到預定值為止。
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean$^1$: 0.167/1.074secs$^2$] [Times: user=0.20 sys=0.00, real=1.07 secs]$^3$(1)CMS-concurrent-abortable-preclean,表示這是併發可取消的預清理步驟
(2)0.167/1.074secs,這一階段的耗時,執行時間和對應的實際時間。從這裡看到執行時間比時間時間小很多。而通常情況下,由於有多核並行,real時間會比user時間小。但是在這裡是由於垃圾回收執行緒等待了將近1秒鐘沒做任何動作,但是隻消耗了0.167秒的CPU時間來進行實際操作。
(3)[Times: user=0.20 sys=0.00, real=1.07 secs],併發階段這裡的數值仍然沒有多大的參考價值。
階段五:最終標記(Final Remark)
這是CMS垃圾收集器各階段中第二個也是最後一個stop-the-world階段。這一階段的目的是確定老年代中最終具體存活有哪些物件。這意味著在這一階段需要遍歷老年代區域中(包括階段三中的dirty物件)所有能直接或間接被GC Roots物件所引用的物件。
通常CMS垃圾收集器會在新生代有足夠空間的情況下嘗試執行最終標記階段。這主要是為了防止與新生代GC導致的stop-the-world事件連續發生。即儘量避開與新生代GC連續執行。
這一階段的日誌稍微複雜一些,
2015-05-26T16:23:08.447-0200: 65.550$^1$: [GC (CMS Final Remark$^2$) [YG occupancy: 387920 K(613440 K)$^3$]65.550: [Rescan (parallel), 0.0085125 secs]$^4$65.559: [weak refs processing,0.0000243 secs]65.559$^5$: [class unloading, 0.0013120 secs]65.560$^6$: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs$^7$][1 CMS-remark:10812086K(11901376K)$^8$] 11200006K(12514816K)$^9$, 0.0110730 secs$^{10}$] [Times: user=0.06 sys=0.00,real=0.01 secs]$^{11}$(1)2015-05-26T16:23:08.447-0200: 65.550,發生本次事件的時間,以及本次事件發生時JVM的啟動時間
(2)CMS Final Remark,標記本次是Final Remark階段。這一階段會stop-the-world,用於標記出老年代中所有存活物件
(3)YG occupancy: 387920 K(613440 K),新生代的記憶體使用量,以及新生代總記憶體量
(4)[Rescan (parallel), 0.0085125 secs],這一步將在應用暫停時併發標記出所有存活物件。在這裡耗時為0.0085125秒
(5)[weak refs processing,0.0000243 secs]65.559,這裡處理弱引用物件,耗時為0.0000243秒,發生在JVM啟動後的第65.559秒
(6)[class unloading, 0.0013120 secs]65.560,清理未使用的類資訊,並記錄好耗時和發生時間
(7)scrub string table, 0.0001759 secs,清理持有class級別元資料的symbol和string表,總耗時為0.0001579秒
(8)10812086K(11901376K),老年代記憶體使用量和總量
(9)11200006K(12514816K),堆記憶體使用量和總量
(10)0.0110730 secs,本階段的耗時
(11)[Times: user=0.06 sys=0.00,real=0.01 secs],本階段的耗時,由user,sys和real三部分組成。
經過以上五步標記階段後,老年代中所有存活物件都已經被標記過,接下來垃圾收集器將回收其中不再使用的物件,並清理老年代的記憶體空間。
階段六:併發清除(Concurrent Sweep)
與應用執行緒一起併發進行,不需要stop-the-world。這一階段的目的是清除不再使用的物件,回收這些物件佔用的記憶體空間。
2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep$^1$: 0.027/0.027 secs$^2$] [Times:user=0.03 sys=0.00, real=0.03 secs]$^3$(1)CMS-concurrent-sweep,標記本次是併發清除階段,清除不再使用的物件,回收這些物件佔用的空間
(2)0.027/0.027 secs,這一階段的耗時
(3)[Times:user=0.03 sys=0.00, real=0.03 secs],這一階段的耗時,由user,sys和real三部分組成
階段七:併發重置(Concurrent Reset)
併發執行階段,重置CMS演算法內部使用的資料結構,為下一次垃圾回收作準備。
2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset$^1$: 0.012/0.012 secs$^2$] [Times:user=0.01 sys=0.00, real=0.01 secs]$^3$(1)CMS-concurrent-reset,標識併發重置階段。這一階段主要用於重置CMS演算法內部使用的資料結構,為下一次垃圾回收週期做準備
(2)0.012/0.012 secs,本階段的耗時
(3)[Times:user=0.01 sys=0.00, real=0.01 secs],本階段的耗時,由user,sys和real三部分組成
總結一下,CMS垃圾收集器儘量將大部分工作移到必須stop-the-world階段之外併發進行,大大降低了應用暫停時間。但是CMS垃圾收集器的缺點也是很明顯的,垃圾收集後在老年代中會有很多記憶體碎片。並且CMS垃圾收集器可能會造成不可預期的暫停,尤其是在堆記憶體比較大的時候。
四、G1(Garbage First)
實現G1(Garbage First,垃圾優先)垃圾收集器的主要目的是想將垃圾回收過程中導致的Stop-The-World維持在一個可控範圍內,對暫停時間可預期,可配置。可以為G1收集器設定一個性能調優目標,可以要求垃圾收集器在給定的y毫秒時間內stop-the-world的暫停時間不超過x毫秒。例如,在給定1秒時間內,由於垃圾收集導致的應用暫停時間不能超過5毫秒。G1收集器會盡可能的去達到設定的調優目標,但是並不保證完全實現設定值。所以,可以稱G1收集器為軟實時(soft real-time)。
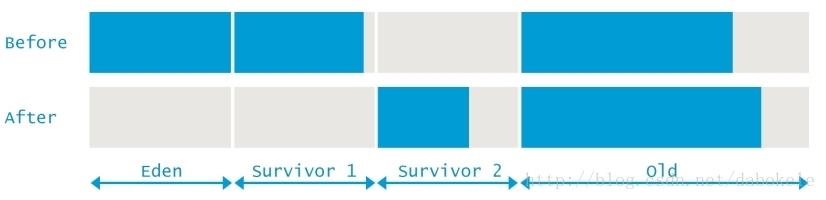
與其他垃圾收集器相比,G1有一些獨特的設計。首先,堆空間不再被劃分為連續新生代和老年代,而是將堆空間劃分為一定數量(一般為2048)個小的堆區域(heap regions)。在這些堆區域中可以儲存物件。每一個區域可能都是一個Eden區,Survivor區,或者是Old區。在邏輯上,G1的小堆區中所有的Eden區和Survivor區可以統稱為新生代,所有Old區可以統稱為老年代。如下圖所示:

這種設計可以避免GC時需要同時回收整個堆空間,在每次GC時,只需要回收所有Region中的一部分小堆區即可,即所謂的回收集(collection set)。所有Young區會在每次暫停時進行回收,部分Old區也有可能在暫停時被回收,
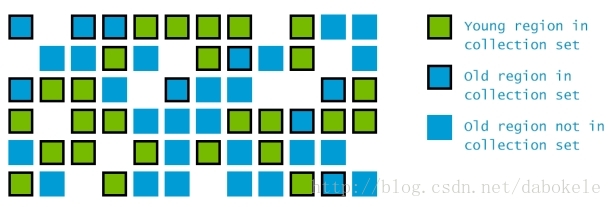
G1的另一點不同之處是,在GC的併發階段,G1收集器會預估一下每個region中可能存活的物件有多少。那些被預估出可能包含很多垃圾的Region會被歸入回收集中,優先進行收集。這也是G1收集器所謂的垃圾優先(garbage-first)的由來。
如果想要設定JVM使用G1收集器的話,使用如下引數
java -XX:+UseG1GC com.mypackages.MyExecutableClass1、Evacuation Pause: Fully Young
在應用剛啟動時,由於還沒有過GC的記錄,G1無法獲取到任何關於GC的相關資訊。所以在最開始,G1收集器會在Fully Young模式下執行。當新生代裝滿後,應用執行緒會被暫停,Young堆區中的物件會被複制到Survivor堆區,或者在還沒有Survivor區時會將存活物件複製到一些空閒的堆區中,這些被選中的堆區就成為了Survivor堆區。
這一複製存活物件到Survivor堆區的過程被稱為是轉移過程,這一過程和前面介紹的其他新生代垃圾收集過程類似。轉移過程中生成的日誌檔案非常大,所以,為了簡單起見會從轉移過程生成的日誌檔案中截取出一部分日誌來分析這一過程。另外,由於日誌記錄太多,這裡面涉及到的並行階段和其他階段的日誌將會被拆分成多個部分來解析。

(1)0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs],G1垃圾收集器的轉移暫停階段。開始於JVM啟動後的第134毫秒。暫停的總CPU時間為0.0144秒。
(2)[Parallel Time: 13.9 ms, GC Workers: 8],表示此次暫停的實際時間為13.9毫秒,有8個執行緒並行。
(3)…,這裡省略的部分在後面分析
(4)[Code Root Fixup: 0.0 ms],釋放用於管理並行活動的內部資料結構。耗時一般都為0。
(5)[Code Root Purge: 0.0 ms],清理更多的資料結構,這一階段耗時也幾乎為0,但並不一定為0。
(6)[Other: 0.4 ms],其他並行活動的耗時
(7)…,省略部分參考後面分析
(8)[Eden: 24.0M(24.0M)->0.0B(13.0M),Eden堆區在本階段前後的空間使用和總空間變化
(9)Survivors: 0.0B->3072.0K,Survivor堆區在本階段前後記憶體使用變化
(10)Heap: 24.0M(256.0M)->21.9M(256.0M)],堆總容量和使用量前後變化情況
(11)[Times: user=0.04 sys=0.04, real=0.02 secs],GC事件的耗時,由以下幾部分組成:
- user - 垃圾收集器在本階段的總CPU耗時
- sys - GC過程中, 系統呼叫和系統等待事件所消耗的時間
-
real - 應用暫停的真實時間。由於GC時是並行執行的,所以這個時間是由
(user時間 + sys時間) / 執行緒數來確定的。在這裡,使用了8執行緒。由於並不是所有階段都是並行執行的,所以,這個值可能比計算的稍大。除此之外,還有一些複雜的工作由幾個專用的執行緒在執行,這部分的日誌如下所示:
-

(1)[Parallel Time: 13.9 ms, GC Workers: 8],表示在13.9毫秒時間內,以下活動由8個執行緒在並行執行
(2)GC Worker Start (ms),這8個執行緒開始執行的最早,最晚,以及平均時間。這裡的時間是距離JVM啟動的毫秒數。如果最小值和最大值相差比較多,則表示有其他執行緒在佔用這些執行緒資源
(3)Ext Root Scanning (ms),遍歷外部根節點的耗時。外部根節點指的是classloader,或者JNI引用,或者JVM系統等。“Sum”統計的是CPU時間
(4)Code Root Scanning (ms),遍歷堆內引用的根節點的耗時
(5)Object Copy (ms),從待回收堆區複製存活物件的耗時
(6)Termination (ms),GC執行緒用於確認自身可以安全停止的耗時,這段時間上面也不做,停止之後該執行緒就終止運行了
(7)Termination Attempts,GC執行緒嘗試停止的次數。如果嘗試停止時發現還有事情沒做完,或者停止時間太早,則會嘗試失敗
(8)GC Worker Other (ms),一些其他的不值得在GC日誌中單獨列出來的工作
(9)GC Worker Total (ms),GC工作執行緒的工作總時間
(10)GC Worker End (ms),GC執行緒完成停止的時間。一般來說,時間應該基本相近,否則意味著有一些GC執行緒被其他執行緒佔用導致被掛起。
另外,在轉移階段還有一些其他活動的GC日誌,我們再看下面這一段,

(1)[Other: 0.4 ms],其他GC活動,大部分也是並行的
(2)[Ref Proc: 0.2 ms],處理非強引用的耗時。主要清除這些非強引用或者決定不需要清除這些非強引用
(3)[Ref Enq: 0.0 ms],將需要保留的非強引用移動到合適的引用佇列中的耗時
(4)[Free CSet: 0.0 ms],將回收集中釋放的小堆區進行回收,這樣下一次分配時又可以重新使用
2、併發標記(Concurrent Marking)
G1垃圾收集器使用了很多CMS中的概念,哪怕在某些階段的執行過程有所不同,但是其最終目的仍然是差不多的。所以如果對CMS不熟悉的話,最好先了解一下CMS的原理,再來繼續研究G1收集器的執行過程。G1併發標記過程會使用Snapshot-At-The-Beginning來記錄在標記開始時各物件的引用狀態,這裡的Snapshot會包含所有物件,哪怕那些物件此時是垃圾物件(這些垃圾物件在後續過程中有可能被重新標記為存活物件)。基於這些資訊可以很方便的構造出回收集來。
這些資訊接下來就會被用來對Old堆區進行垃圾回收,如果可以判斷出某個堆區中全是垃圾物件,或者在stop-the-world的轉移暫停階段某些Old堆區中既包含垃圾物件又包含存活物件,那麼這個過程可以併發的進行。
如果堆空間使用量超過某閾值,就會觸發併發標記階段。預設情況下這一閾值為45%。可以通過引數InitiatingHeapOccupancyPercent引數來設定。類似於CMS,G1中的併發標記過程也由若干階段組成,其中某些階段可以完全併發進行,某些階段需要在應用執行緒暫停的情況下進行。
階段一:初始化標記(Initial Mark)
這一階段標記出所有可以從GC roots物件直接訪問到的物件。在CMS中,這一階段需要在stop-the-world時進行。但是G1中,這一階段會在轉移暫停階段進行。在轉移暫停階段輸出的GC日誌第一行就能看到初始標記的資訊,
1.631: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0062656 secs]階段二:根堆區掃描(Root Region Scan)
這一階段會將可以從根堆區(Root Regions)訪問到的物件都標記出來。所謂的根堆區是指那些非空的小堆區,以及那些在標記階段會對它們進行回收的區域。由於在併發標記階段移動物件可能會造成一些其他的麻煩,所以這一階段需要在下一次轉移暫停階段開始時結束。如果轉移暫停階段需要提前開始,它會向堆根區掃描過程傳送一個終止訊號,然後等堆根區掃描結束就開始轉移暫停階段。目前的堆根區一般是指,在下一次轉移暫停階段會被回收的新生代區域。
1.362: [GC concurrent-root-region-scan-start]
1.364: [GC concurrent-root-region-scan-end, 0.0028513 secs]階段三:併發標記(Concurrent Mark)
這一階段和CMS中的併發標記階段很類似,遍歷物件圖中的所有物件,並在bitmap中標記出那些課訪問的物件。為了保證與snapshot-at-the-beginning中的記錄一致,G1垃圾收集器會將所有應用執行緒中對某些物件的引用發生的變更都記錄下來,以便後續跟蹤。
為了達到這一目的,G1使用了一個Pre-Write機制。在G1的併發標記階段還在進行時,每當某物件中的欄位引用發生變更時,都會在log快取中進行記錄。
1.364: [GC concurrent-mark-start]
1.645: [GC concurrent-mark-end, 0.2803470 secs]階段四:重新標記(Remark)
這個階段和CMS中類似,也會導致stop-the-world。這個暫停過程,主要是用來將標記過程完成。但是對於G1垃圾收集器來說,只會造成一個簡短的暫停。在這個簡短暫停過程中,在不會有應用執行緒繼續更新引用變更log的情況下,對這個log中記錄的引用變動作處理,並且標記出那些在併發標記過程中沒有標記為存活,但是在後續應用執行緒執行中又變成存活狀態的物件。這一階段同樣也會進行一些額外的清理工作,比如對引用的處理,或者類的解除安裝(class unloading)
1.645: [GC remark 1.645: [Finalize Marking, 0.0009461 secs] 1.646: [GC ref-proc, 0.0000417 secs] 1.646:[Unloading, 0.0011301 secs], 0.0074056 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]階段五:清理(Cleanup)
這一階段主要為接下來即將要進行的物件轉移階段做準備。統計出所有小堆區中的存活物件,並且對這些小堆區按存活物件數進行排序。也為下一次標記階段作必要的整理工作,維護併發標記的內部狀態。
最終,所有不包含存活物件的小堆區在這一階段都被回收了。對空的小堆區回收和對存活率的計算都是併發進行的。這個階段需要在短暫的stop-the-world過程中進行,日誌如下
1.652: [GC cleanup 1213M->1213M(1885M), 0.0030492 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
如果某些小堆區只包含垃圾物件,則日誌格式可能會有點不同,如下所示,
1.872: [GC cleanup 1357M->173M(1996M), 0.0015664 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
1.874: [GC concurrent-cleanup-start]
1.876: [GC concurrent-cleanup-end, 0.0014846 secs]3、Evacuation Pause: Mixed
如果上一步併發清除能夠完全釋放老年代中所有的小堆區當然是最理想的情況,但是這一狀況並不經常發生。當併發標記過程順利完成後,G1垃圾收集器會觸發一個混合回收過程,這個混合回收過程不僅會回收新生代堆區的空間,也會回收老年代堆區中的垃圾物件。
混合轉移暫停階段並不經常緊接著併發標記階段進行。混合轉移暫停階段的觸發有一系列的條件。例如,如果不能保證可以釋放出很大一部分Old堆區空間時,是不會輕易進行這一步的。
所以,在併發標記階段後會進行很多次純新生代的轉移暫停,偶爾執行一次混合轉移暫停。
將會新增到回收集中的Old堆區的確切數量,以及它們新增到回收集中的順序,也是由一些條件來決定的。這些條件包括,對應用的效能要求,併發標記過程垃圾回收的效率,以及其他的JVM配置引數。混合垃圾回收的過程和前面已經分析過的純新生代GC過程很類似,但是在這裡我們再提出一個概念記錄集(remembered sets,注意與collection sets進行區分)。
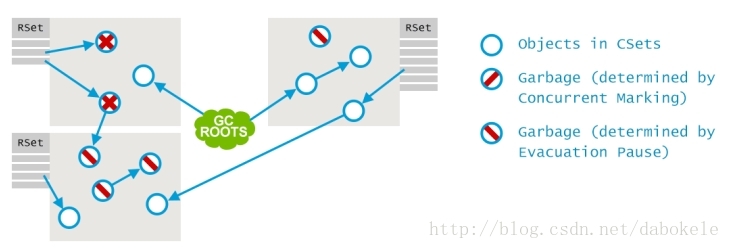
記錄集是用來實現各堆區獨立進行回收的。舉例來說,當回收堆區A,B和C時,我們需要知道是否有從D區或E區指向A,B和C區的引用存在。但是,如果要遍歷整個堆中的所有引用情況將會是一個極其耗時的過程。那麼G1收集器針對這種情況進行了一些優化。G1中使用的記錄集非常類似於其他GC演算法中獨立回收新生代區域的Card Table。
如下圖所示,每一個堆區都有一個記錄集,在記錄集中記錄了所有從外部過來的引用。這些引用在處理的時候會被當成另外的GC roots。注意,併發標記階段中標出的Old堆區中的垃圾物件,即使有外部引用指向它們,在這個過程中也會直接被忽略掉,並且其實引用者也是一個垃圾物件。

接下來的過程和其他垃圾收集器也基本類似,多路GC執行緒併發的找出哪些物件是存活物件,哪些物件是垃圾物件。
最終,這些存活的物件會被移動到survivor堆區中,如果有必要的話,也會根據需要建立survivor堆區。這一過程之後,其他堆區就被清空了,可以進行下一輪的物件分配。
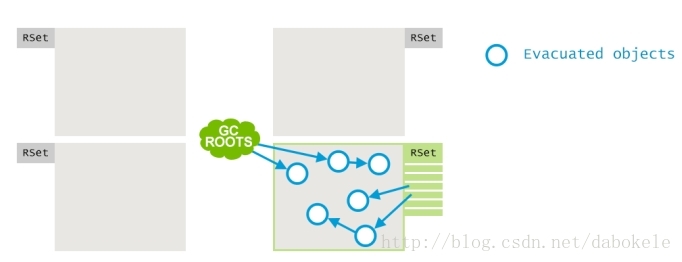
為了在應用執行階段來維持這麼一個記錄集,G1垃圾收集器使用了一個Post-Write策略。如果某個物件的屬性引用更新了,並且是一個跨堆區的引用,那麼就會在目標堆區的記錄集中記錄一次這個引用。為了降低Post-Write的效能消耗,更新記錄集的過程是非同步進行的,並且還做了一些優化。大致上是這樣的:Post-Write將髒的card資訊(dirty card information)記錄到一個本地buffer中,然後會有一個特定的GC執行緒找到這個dirty card information,並且將其記錄到引用堆區的記錄集中。
在混合轉移過程中,輸出的日誌資訊如下,

4、總結
通過上面的分析,應該對G1的功能有了一定的瞭解。但是上面的過程分析中還是對G1的實現細節做了一些省略,比如說G1如何處理超大物件等。綜合來看,G1是HotSpot JVM中最好的垃圾收集器。並且HotSopt對G1收集器一直在持續的做優化。
可以看到,G1垃圾收集器解決了CMS收集器中出現的若干問題,包括應用暫停時間的可預期以及避免了堆記憶體碎片等。對一個應用來說,如果對CPU資源不作限制,而主要關注其延遲效能時,非常適合使用G1垃圾收集器。然而,延遲效能的優化並不是無代價的,由於會有額外的write barriers的存在和使用更多的守護執行緒,G1的吞吐量會有所降低。所以,如果應用對吞吐量有很高的要求,或者CPU資源比較緊張時,CMS可能會更加適合。
在應用中如何選擇合適的GC演算法,最終還是得靠實踐來證明。接下來一章中將會分析效能調優的一些參考。
並且,從Java 9開始,G1垃圾收集器很可能會成為預設的GC。
五、 Shenandoah
到目前為止,已經分析了HotSopt JVM中的所有可用於生產的GC演算法了。這裡將會簡要分析另一種垃圾收集器,超低延遲垃圾收集器(Ultra-Low-Pause-Time Garbage Collector)。它的設計目標主要是用於大型多核大堆記憶體的伺服器應用。目標是用於管理100GB的堆記憶體,以及要求暫停低於10毫秒的應用。實現這一目標是以犧牲吞吐量為代價的,這種幾乎無暫停的GC演算法的實現,要求在吞吐量上的效能降低不能超過10%。
在這種GC演算法沒有正式釋出之前,不會對其做更深入的研究,但是可以預期到這種演算法仍然會用到前面提到的一些垃圾回收的基本思想。比如說併發標記,增量收集等。但是它又有一些不同,比如說不再將堆記憶體劃分為不同的年代而只是使用單個空間。Shenandoah並不是一個基於分代理論的垃圾收集器,這也使得它可以不使用card table和記錄集了。它仍然使用forwarding pointers以及read barrier,這使得它可以對存活物件進行併發的複製,降低了GC次數和GC時間消耗。
有關更多Shenandoah的資訊,可以參考部落格: https://rkennke.wordpress.com/。