
目標檢測--Selective Search for Object Recognition(IJCV, 2013)
Selective Search for Object Recognition
作者: J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, A. W. M. Smeulders.
引用: Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer vision, 104(2) (2013): 154-171.
引用次數: 803(Google Scholar,by 2016/11/29).
這是一篇2013年發表的文章,應該是下面2011年ICCV會議論文的擴充套件:
Van, de Sande, Koen E A, et al. "Segmentation as selective search for object recognition. " IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, November 2011:1879-1886.
1 介紹
如何定位一張影象上的目標(比如"牛")? 處理的流程可以是這樣的:
第一步: 將影象劃分成很多的小區域(regions);
第二步: 判定每個區域是屬於"牛"的還是"非牛",將屬於"牛"的區域進行合併,就定位到牛了!
解釋:
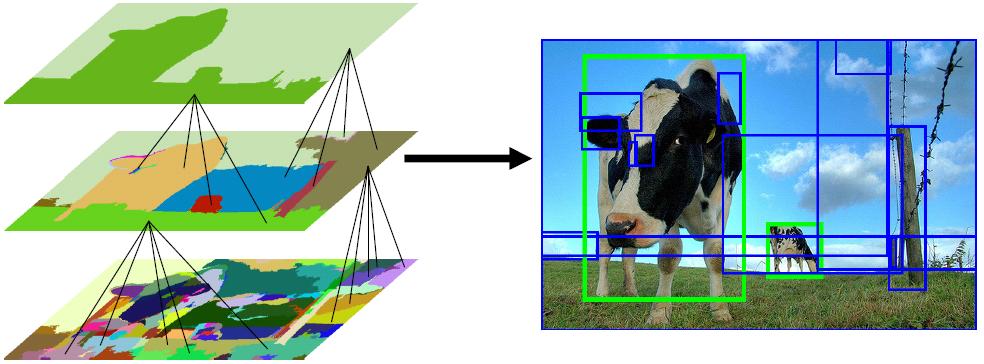
第一步解釋: 如何將影象劃分成很多的小區域? 劃分的方式應該有很多種,比如: 1)等間距劃分grid cell,這樣劃分出來的區域每個區域的大小相同,但是每個區域裡面包含的畫素分佈不均勻,隨機性大;同時,不能滿足目標多尺度的要求(當然,可以用不同的尺度劃分grid cell,這稱為Exhaustive Search, 計算複雜度太大)! 2)使用邊緣保持超畫素劃分; 3)使用本文提出的Selective Search(SS)的方法來找到最可能的候選區域;
其實這一步可以看做是對影象的過分割,都是過分割,本文SS方法的過人之處在於預先劃分的區域什麼大小的都有(滿足目標多尺度的要求),而且對過分割的區域還有一個合併的過程(區域的層次聚類),最後剩下的都是那些最可能的候選區域,然後在這些已經過濾了一遍的區域上進行後續的識別等處理,這樣的話,將會大大減小候選區域的數目,提供了演算法的速度.
下面放一張圖說明目標的多尺度:

第二步解釋: 第一步中先生成,後合併得到了那些最可能的候選區域,這一步將對每個區域進行判別,也就是判別每個區域到底是"牛"還是"非牛"! 流程的話,無非是在每個區域上提取特徵,然後訓練一個分類器(Kernel SVM);
2 訓練和測試流程圖
2.1 本文模型訓練流程圖
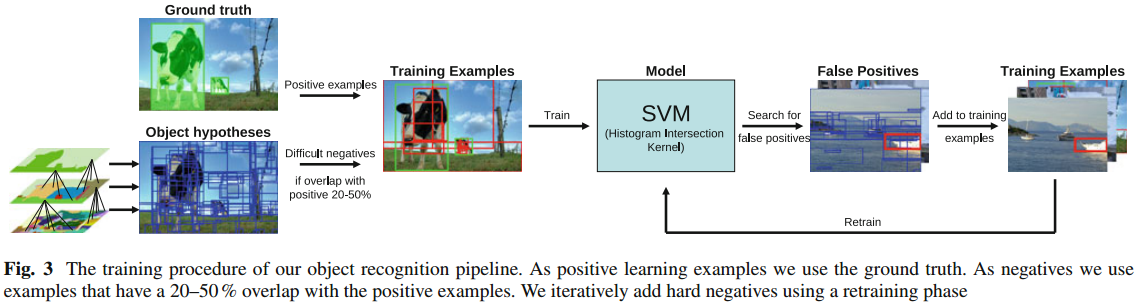
下面我將按照自己的理解一步一步地對此訓練流程圖進行講解: 這個流程圖我認為應該分成四個部分:
第一部分: 訓練集構造
負樣本: 給定一張訓練影象 --> 形成原始的過分割區域 --> 使用本文SS方法對區域進行融合,形成一系列最可能的候選區域 --> 計算每個候選區域與真實標記區域GT之間的重合度,如果區域A與GT的重合度在20-50%之間,而且A與其他的任何一個已生成的負樣本之間的重合度不大於70%,則A被採納為負樣本,否則丟棄A,繼續判別下一個區域;
正樣本: 就是那些手工標記的GT區域作為正樣本;
(問題1: 會不會負樣本很多而正樣本很少? 從而出現類不均衡問題)
下圖展示了區域合併的過程: 對於此圖而言,正樣本是兩個綠色框框圈出來的區域;負樣本為藍色框框圈出來的區域;正樣本是人手工標記的,負樣本是SS方法得到的!
第二部分: 提取每個正/負樣本(都是一個個不同大小的區域)的特徵
第一部分中將正樣本區域和負樣本區域都提取出來了,現在就需要提取每個區域的特徵了.本文主要採用了兩種特徵: HOG特徵 + bag-of-words特徵,同時輔助性地增加了SIFT,two colour SIFT,Extended OpponentSIFT,RGB-SIFT這四種特徵,這樣特徵加起來的維度達到了驚人的360,000.
(問題2:每個區域的大小都是不相同的,如何保證提取到的每個區域的特徵向量維度相同?)
第三部分: 分類器
第二部分中,每個區域的特徵提取出來了,真實類別標籤也知道,那這就是一個2分類問題;分類器這裡採用了帶有Histogram Intersection Kernel的SVM分類器進行分類;這裡沒有對分類器本身做什麼改進,我們可能會質疑一下他這種分類器的選擇是否對這種場合是最好的,其他的沒什麼好講的.
(問題3:選這種分類器的原因是不是它適用於處理高維度資料?)
第四部分: 反饋
第三部分將分類器訓練好了,訓練好了就完了嗎? NO! 現在流行一種反饋機制,SVM訓練完成了,將得到每個訓練影象每個候選區域的軟分類結果(每個區域都會得到一個屬於正樣本的概率),一般如果概率大於0.5將被認為是目標,否則被認為是非目標,如果完全分類正確,所有的正樣本的SVM輸出概率都大於0.5,所有負樣本的SVM輸出概率都小於0.5,但是最常見的情況是有一部分的負樣本的輸入概率也是大於0.5的,我們會錯誤地將這樣樣本認為是目標,這些樣本就稱之為"False Positives".
我們這裡就是想把這些"False Positives"收集起來,以剛才訓練得到的SVM的權值作為其初始權值,對SVM進行二次訓練,經過二次訓練的SVM的分類準確度一般會有一定的提升;
2.2 測試過程
測試的過程基本和訓練過程相同: 首先用SS方法得到測試影象上候選區域 --> 然後提取每個區域的特徵向量 --> 送入已訓練好的SVM進行軟分類 --> 將這些區域按照概率值進行排序 --> 把概率值小於0.5的區域去除 --> 對那些概率值大於0.5的,計算每個區域與比它分數更高的區域之間的重疊程度,如果重疊程度大於30%,則把這個區域也去除了 --> 最後剩下的區域為目標區域.
(問題4:重疊程度如何計算,如果計算A與B之間的重疊程度,分子是A與B的交集,分母是A還是B?)
總結
1. 本文最大的賣點在於它的Selective Search策略,這個策略其實是藉助了層次聚類的思想(可以搜尋瞭解一下"層次聚類演算法"),將層次聚類的思想應用到區域的合併上面;作者給出了SS的計算過程:
總體思路:假設現在影象上有n個預分割的區域,表示為R={R1, R2, ..., Rn}, 計算每個region與它相鄰region(注意是相鄰的區域)的相似度,這樣會得到一個n*n的相似度矩陣(同一個區域之間和一個區域與不相鄰區域之間的相似度可設為NaN),從矩陣中找出最大相似度值對應的兩個區域,將這兩個區域合二為一,這時候影象上還剩下n-1個區域; 重複上面的過程(只需要計算新的區域與它相鄰區域的新相似度,其他的不用重複計算),重複一次,區域的總數目就少1,知道最後所有的區域都合併稱為了同一個區域(即此過程進行了n-1次,區域總數目最後變成了1).演算法的流程圖如下圖所示:


2. 除了SS這個賣點之外, 本文還用較大的篇幅講述了"Diversification Strategies(多樣化策略)"這個東西,在我看來,這就是一個模型選擇問題,講不講都沒有多大的關係.我認為,面對一個具體的問題,有很多的超參需要調節.何為超參?我認為超參從小到大應該分成三類:
第一類: 一個既定模型裡面可以調節的引數.比如在CNN裡面有學習率,卷積核尺寸,卷積maps數目等等引數,面對不同的問題,這些引數的設定可能是不相同的,不同的引數帶來不同的結果,因此我們需要對這些引數進行調節;再比如本文SS演算法裡面的相似度度量,度量方法不止一種,你可能需要面對實際的任務對其進行實驗調整.
第二類: 一個既定模型裡面可以調節的模組.比如說本文的模型,它採用了SVM分類器,你可以把它換成其他的分類器;提取了HOG等特徵,你也可以把它換成深度特徵;利用了RGB影象,你也可以把RGB轉化到其他的色彩空間進行;採用這種初始區域初始化方法,當然也可以換成其他的,只要最適合你的任務就行.
第三類: 模型方法超參.比如同樣是解決目標檢測問題,本文的方法算是一種,但是還有千千萬萬種其他的不同的目標檢測演算法,從這個角度來說,模型方法整體上可以看做是一種超參,當然,在實際進行中我們可能只專注於自己的演算法,對這個超參的調節表現在實驗部分對不同方法之間的對比.
原文"3.2 Diversification Strategies"這一節提供了調參的一些思路,分析了不同顏色空間各通道的特點,這有利於我們在面對自己的實際任務時明白要嘗試的方向.還有就是給出了SS演算法裡面相似度度量的幾種方法,比如顏色相似度,紋理相似度,尺寸相似度,填充相似度,作者肯定沒有對所有的相似度進行窮舉,也沒有說哪種相似度適合哪種任務,我覺得更重要的還是一種思路的借鑑,提供了一種思路和思考方向,我覺得這篇論文的價值就達到了.

3. 計算速度
相比於以往的對影象上的區域進行窮舉的方法,本文SS方法只生產一小部分的最可能的候選區域,這樣對後續的處理以及整體計算有效性確實有所提高.但是我認為對每個區域都要提取高達36萬維度的特徵向量,這可能是本文演算法最耗時的地方,如此高緯度的特徵向量是否有必要?(給人的感覺就是一股腦把那些典型的手工特徵HOG,SIFT不管好壞都提取出來了)
本文難念有一些誤解或者不當之處, 敬請留言指教, 謝謝!