
將神經網路訓練成一個“放大鏡”
摘要: 想不想將神經網路訓練成一個“放大鏡”?我們就訓練了一個這樣炫酷的神經網路,點選文章一起看下吧!

低解析度蝴蝶的放大
當我們網購時,我們肯定希望有一個貼近現實的購物體驗,也就是說能夠全方位的看清楚產品的細節。而解析度高的大影象能夠對商品進行更加詳細的介紹,這真的可以改變顧客的購物體驗,讓顧客有個特別棒的購物之旅。idealo.de是歐洲領先的比價網站,也是德國電子商務市場最大的入口網站之一,在此基礎上,我們希望能夠在此基礎上為使用者提供一個使用者友好、有吸引力的購物平臺。
在這裡,我們利用深度學習來評估數百萬酒店影象的美學層次和技術質量,另外,那些沒有任何資訊的、特別難看的小的產品影象對我們來說是無效的,因此需要想辦法解決。
購物網站上並不是所有的商店都能為顧客提供高質量的影象,相反,商家提供的影象特別小、解析度特別低、質量也很低。為了向用戶展示高質量的高解析度影象,我們基於2018年的論文《影象超解析度的RDN網路》,訓練了一個特別先進的卷積神經網路。
我們的目標很簡單:拍攝一些特別小的影象,然後就像使用放大鏡一樣,對影象進行放大,並且還要保持高解析度。
本文對實現這一目標做了詳細介紹,另外,具體實現的細節,請檢視GitHub。
總概
與大多數深度學習專案一樣,我們的深度學習專案主要有四個步驟:
1.回顧前人對該專案所做的貢獻。
2.實施一個或多個解決方案,然後比較預先訓練的版本。
3.獲取資料,訓練並測試模型。
4.針對訓練和驗證結果對模型進行改進和優化。
具體來說,本文主要有以下幾方面的內容:
1.介紹模型訓練的配置,如何評估模型的效能
2. 檢視早期訓練和測試結果,瞭解從哪方面進行改進。
3.指出後續需要探索的方向。
訓練
與以往“標準”的監督深度學習任務不同,我們這個“放大鏡”深度學習模型輸出的不僅僅是類標籤或一個分數,而是一整幅影象。這就意味著訓練過程以及評估會跟以往略有不同,我們要輸出的是原始高解析度影象,為了更好的對模型進行評估,我們需要一種測量縮放輸出影象“質量”的方法,該方法更詳細的優缺點將在後面進一步做詳細闡釋。

損失函式
損失函式是用來評估神經網路的效能究竟如何,這個有很多方法可以評估。這個問題的本質為大家留下了創造力空間,如有些聰明的人會用
評估
我們用峰值信噪比(PSNR)來評估輸出影象的質量,峰值信噪比是基於兩個影象之間的畫素均方差(MSE)。由於峰值信噪比是最常用的評估輸出影象質量的方法,因此我們也使用這一評估標準,以便將本文模型與其他模型作比較。
開始
我們在p2.xlarge AWS EC2例項上進行訓練,直到驗證損失函式收斂,訓練結束,這大概需要90個週期(一個週期24小時),然後使用Tensorboard跟蹤訓練資料集及驗證資料集的損失函式和PSNR值。

90個訓練時期的Tensorboard圖
如上圖所示,左上角為在每個週期結束時,反向傳播到神經網路上的訓練損失函式。右上角為跟蹤泛化效能的非訓練資料及的損失。左下角為訓練資料集的PSNR值。右下角為驗證資料集的PSNR值。
結果
輸出的結果如下所示,我們先看看模型的輸出結果,再考慮如何對該模型進行改進。左側是驗證資料集中的整個影象,中間是卷積神經網路的輸出提取影象塊,右側是使用標準過程將中間輸出提取影象塊按比例放大後的輸出,這裡使用了GIMP的影象縮放功能


LR影象(左),重建SR(中),GIMP基線縮放(右)。
這個結果肯定不是特別完美:蝴蝶的天線周圍有些沒必要的噪聲,蝴蝶的頸部和背部的毛髮及翅膀上有些斑點輪廓,神經網路的輸出影象(中)看起來要比GIMP基線輸出影象(右)更加清晰。
結果分析
為了進一步理解模型有哪些優缺點,我們需要從驗證資料集中提取具有高PSNR值的影象塊和具有低能量度值的影象塊。

不出所料,效能最佳的影象塊是具有較多平坦區域的影象塊,而較為複雜的影象塊難以準確再現。因此,我們重點關注這些較複雜的影象塊,以便對結果進行訓練和評估。
同樣的,我們也可以使用熱圖(heatmap)突出顯示原始HR影象和神經網路輸出SR影象之間的誤差,顏色較暗的部分對應於較高的畫素均方誤差(較差的結果),顏色較淺的部分對應於較低的畫素均方誤差(或較好的結果)


HR-SR畫素誤差熱圖。顏色越暗,誤差越大。
我們可以看到,具有多種模式的區域的誤差會更大,但是看起來“更簡單”的過渡區域則是相當黑暗的(例如雲、天空),這是可以改進的,因為它與idealo的目錄用例相關。
淺談深度學習任務中的非真實資料
與常見的分類問題或輸出為一個分值的監督式深度學習任務不同,我們用於評估神經網路輸出的真實資料是原始HR影象。
這既有好處,也有壞處。
壞處:像Keras這樣的當前較為流行的深度學習框架沒有預先制定訓練解決方案,比如生成器。實際上,它們通常依賴於從一維陣列中獲取訓練和驗證標籤或檔案,或者是直接從檔案結構中派生出來的,這會涉及到一些額外的編碼演算法。
好處:沒有必要花太多時間來獲得標籤,給出一個HR影象池,我們可以對其進行簡單的縮小,獲得我們所需要的LR訓練資料,並使用原始HR影象來評估損失函式
通常來說,使用影象資料對神經網路進行訓練時,需要從訓練資料集中隨機的選擇多個影象來建立訓練批次。然後將這些尺寸重新縮小到一個較小的尺寸,一般來說,大小約為100*100畫素。我們隨時使用隨機變換對影象進行增強,並反饋到神經網路中。在這種情況下,沒有必要向神經網路反饋整張影象,並且這也非常不可取。這是因為,我們不能將影象重新縮放到100*100的小畫素點。畢竟,我們想要對影象進行放大。同時,我們也無法用較大尺寸的影象進行訓練,比如大小為500*600畫素的影象,因為處理這種大影象需要很長的時間。相反,我們可以從整個影象中提取一個非常小的隨機色塊,比如大小為16*16畫素塊,這樣一來,我們就有了更多的資料點,因為每個影象都可以提供數百個不同的色塊。
我們之所以能夠處理這種小色塊,是因為我們不需要將一堆影象進行分類,比如:腿+尾巴+鬍鬚+死老鼠=貓。因此,模型的末端就沒有全連線層。我們只需要使用神經網路來構建這些模式的抽象表示,然後學習如何對其進行放大,除此以外,還要對塊進行重新組合,使組合後的影象變得有意義。這種抽象表示由卷積層和放大層來完成,其中,卷積層是該網路中唯一的一種層型別。
我們還要說明的是,全卷積結構使該網路的輸入大小相互獨立。也就是說,這意味著它與普通的分類卷積神經網路有所不同,你可以向完全卷積神經網路中輸入任何大小的影象:無論輸入影象原始大小是什麼,網路都會輸入一個輸入影象大小2倍的影象。
有關影象超解析度的RDN網路更加詳細的介紹,請檢視文末連結。
另一方面,我們還需要思考如何從影象中提取這些塊。思路如下:從資料集中提取出n個隨機影象,然後從每個影象中提取p個隨機快。我們嘗試了幾種方法,如下圖所示:
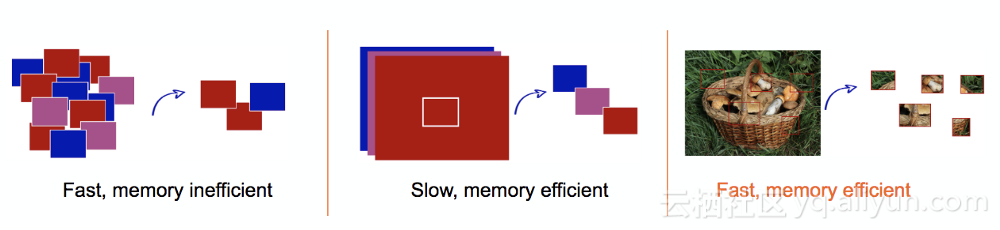
提取塊的不同方法
首先,從一個均勻的網格中提出塊,並建立一個完整的塊資料集。在訓練的時候,我們隨機的提取其batch_size,並對其進行放大,反饋給網路。這種方法的缺點是需要靜態的儲存非常大的資料集,如果要用雲伺服器進行訓練,這種方法其實並不理想:移動和提取資料集是一項相當耗時的操作,並且具有確定性定義的資料集可能並不是最佳資料集。
另一種方法是隨機選擇batch_size大小的影象,並從中提取單個塊。這種方法需要從磁碟中讀取資料,這就大大降低了訓練時間(我們設定的每個訓練時間為15min-1h)。
最後,我們將原始資料集中隨機提取的單個影象塊進行融合,並從中提取動態的batch_size塊,這不僅能儲存原始資料集,同時,也能保持較快的訓練速度。
拓展
這是放大idealo網站產品目錄的第一步,我們已經完成了。
下面是我們將產品影象中低質量、低解析度的影象進行放大,並輸出。

涼鞋的低解析度影象

涼鞋的放大影象
從上圖中,我們可以看到,影象中較為平坦的地方會產生較為明顯的噪聲,文字也會略有失真。這就是我們計劃要改進的地方。
在下一步的探索中,我們將在自己的產品影象資料集上對神經網路進行訓練。
相關連結
Github: Image Super Resolution
Paper: Residual Dense Network for Image Super-Resolution (Zhang et al. 2018)