TensorFlow遊樂園介紹及其神經網路訓練過程
TensorFlow遊樂場是一個通過網頁瀏覽器就可以訓練簡單神經網路。並實現了視覺化訓練過程的工具。遊樂場地址為http://playground.tensorflow.org/
一、TensorFlow遊樂園引數介紹
開啟遊樂園可以看到有很多的預設引數:
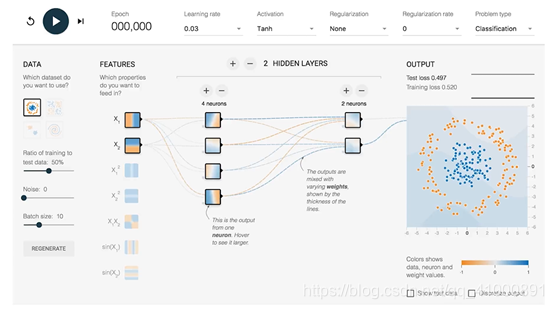
首先我們來解讀一下頂部的一些引數:

Epoch ---> 訓練次數。
learning rate ---> 學習率(是一個超引數,在梯度下降演算法中會用到;學習率是人為根據實際情況來設定)。
Activation ---> 啟用函式(預設為非線性函式Tanh;如果對於線性分類問題,這裡可以不使用啟用函式)。
Regularization ---> 正則化(正則化是利用範數解決過擬合的問題,這裡咱不討論)。
Regularization rate
Problem type ---> 問題型別(在這裡我們要解決的是一個二分類問題,簡單解釋一下分類問題是指,給定一個新的模式,根據訓練集推斷它所對應的類別(如:+1,-1),是一種定性輸出,也叫離散變數預測;迴歸問題是指,給定一個新的模式,根據訓練集推斷它所對應的輸出值(實數)是多少,是一種定量輸出,也叫連續變數預測;在這裡我們屬於分類問題)
其次是下發的一些模組:

DATA
FEATURES ---> 特徵向量(為了將一個實際問題對應到空間中的點,我們需要提取特徵。在這裡我們可以用零件的長度和質量來大致描述;所以這裡x1就代表零件長度,x2代表零件質量;特徵向量是神經網路的輸入)。
HIDDEN LAYERS ---> 隱藏層(在輸入和輸出之間的神經網路稱為隱藏層;一般神經網路的隱藏層越多這個神經網路越深;這裡我們預設有一個隱藏層,這個隱藏層上有4個節點)。
OUTPUT ---> 輸出(顯示區分平面以及訓練資料)。
二、以TensorFlow遊樂園為例介紹神經網路訓練過程
圖上每一個小格子代表神經網路中的一個神經元,每一條線代表神經元之間的連線。每一個節點和邊都被塗上了或深或淺的顏色。但邊的顏色和格子中的顏色含義有略微區別。每一條邊代表了神經網路的一個權重(可以理解為一個引數),它可以理解為任意實數。神經網路就是利用反向傳播演算法對權重進行合理修改從而解決分類或者回歸問題。邊的顏色表現了權重的取值,當邊顏色越深這個引數絕對值越大;當邊越接近白色,這個引數絕對值趨於0。
每一個節點上的顏色代表了這個節點的區分平面。在這裡稍微解釋一下區分平面的概念。如果我們把這個平面當成一個笛卡爾座標系,這個平面上的每一個點就代表了(x1,x2)的一種取值。如果你覺得小圖不太清楚,可以把滑鼠放到輸入節點x1上面,可以看到x1節點此時的區分平面就是Y軸。
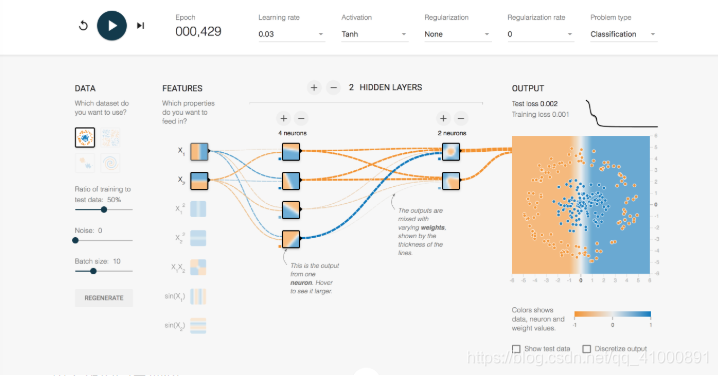
因為x1為輸入層,輸入層的輸出值就是x1本身的值。所以當x1小於0時,這個節點輸出為負,x1大於靈時節點輸出為正。所以Y軸左側都為橙色,右側都是藍色。同理x2的區分平面也很容易理解。
現在我們來看隱藏層的節點,這裡我們只有一個隱藏層,這個隱藏層上有四個節點。先來看第一個。這裡我們把隱藏層節點1簡稱為h1。
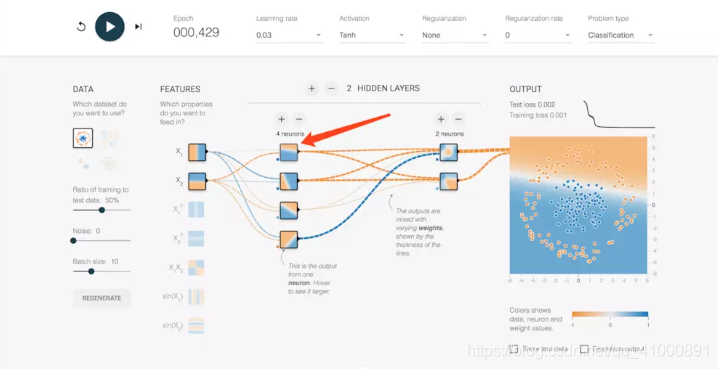
可以看到這個節點的區分平面是一條在x軸之上的斜線。為什麼會發生這種情況??這裡就涉及到我們之前說的權重。在神經網路前向傳播的過程中,後面節點的輸入是之前與之相連的所有節點的加權和。我們仔細觀察連線可以發現x1和h1的連線趨於白色,x2和h1是一條很明顯的橙色線。把滑鼠移到細線上可以看到權重的值,這裡得到公式-0.12x1 + -0.73x2 = h1。所以得到了如圖所示的一個區分平面。平面上方都是負值,下方都是正值。其它節點以此類推。在這裡可以看到,權重對分類的影響至關重要。
最後我們來看隱藏層到輸出層的輸出。首先我們來看一下OUTPUT,如果最終要區分藍色的點和橙色的點,我們的區分平面應該是一個閉合曲線。然而如果我們光靠加權和這種線性變換的話是沒有辦法準確圈出藍色和橙色點的分界線。所以在隱藏層到輸出層的過程我們增加了一個非線性啟用函式Tanh,使得我們最後可以得到一個非線性的結果。綜上神經網路解決一個分類問題大致可以分為:
1.提取特徵向量作為輸入,比如說本例子中零件的長度和質量。
2.定義神經網路結構。包括隱藏層數,啟用函式等等。
3.通過訓練利用反響傳播演算法不斷優化權重的值,使之達到最合理水平。
4.使用訓練好的神經網路來預測未知資料,這裡訓練好的網路就是指權重達到最優的情況。
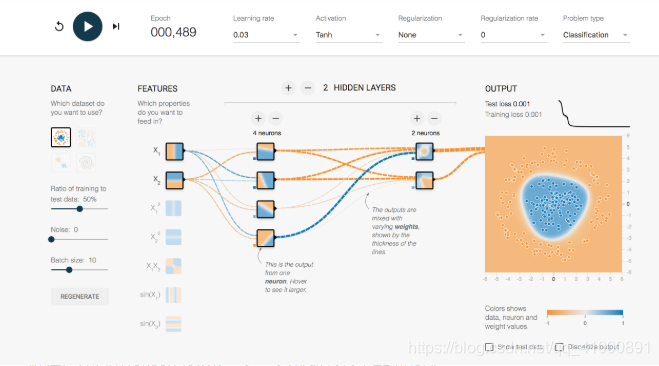
下面我們點選開始訓練按鈕,下圖是訓練489次後的情況。觀察OUTPUT,這時模型其實已經很準確的進行了分類。