
[work*] 機器學習中正則化項L1和L2的直觀理解
正則化(Regularization)
機器學習中幾乎都可以看到損失函式後面會新增一個額外項,常用的額外項一般有兩種,一般英文稱作-norm和-norm,中文稱作L1正則化和L2正則化,或者L1範數和L2範數。
L1正則化和L2正則化可以看做是損失函式的懲罰項。所謂『懲罰』是指對損失函式中的某些引數做一些限制。對於線性迴歸模型,使用L1正則化的模型建叫做Lasso迴歸,使用L2正則化的模型叫做Ridge迴歸(嶺迴歸)。下圖是Python中Lasso迴歸的損失函式,式中加號後面一項即為L1正則化項。
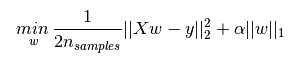
下圖是Python中Ridge迴歸的損失函式,式中加號後面一項即為L2正則化項。
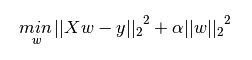
一般迴歸分析中迴歸表示特徵的係數,從上式可以看到正則化項是對係數做了處理(限制)。L1正則化和L2正則化的說明如下:
- L1正則化是指權值向量中各個元素的絕對值之和,通常表示為
- L2正則化是指權值向量中各個元素的平方和然後再求平方根(可以看到Ridge迴歸的L2正則化項有平方符號),通常表示為
一般都會在正則化項之前新增一個係數,Python中用表示,一些文章也用表示。這個係數需要使用者指定。
那新增L1和L2正則化有什麼用?下面是L1正則化和L2正則化的作用,這些表述可以在很多文章中找到。
- L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,可以用於特徵選擇
- L2正則化可以防止模型過擬合(overfitting);一定程度上,L1也可以防止過擬合
稀疏模型與特徵選擇
上面提到L1正則化有助於生成一個稀疏權值矩陣,進而可以用於特徵選擇。為什麼要生成一個稀疏矩陣?
稀疏矩陣指的是很多元素為0,只有少數元素是非零值的矩陣,即得到的線性迴歸模型的大部分系數都是0. 通常機器學習中特徵數量很多,例如文字處理時,如果將一個片語(term)作為一個特徵,那麼特徵數量會達到上萬個(bigram)。在預測或分類時,那麼多特徵顯然難以選擇,但是如果代入這些特徵得到的模型是一個稀疏模型,表示只有少數特徵對這個模型有貢獻,絕大部分特徵是沒有貢獻的,或者貢獻微小(因為它們前面的係數是0或者是很小的值,即使去掉對模型也沒有什麼影響),此時我們就可以只關注係數是非零值的特徵。這就是稀疏模型與特徵選擇的關係。
L1和L2正則化的直觀理解
這部分內容將解釋為什麼L1正則化可以產生稀疏模型(L1是怎麼讓係數等於零的)
L1正則化和特徵選擇
假設有如下帶L1正則化的損失函式:
其中是原始的損失函式,加號後面的一項是L1正則化項,是正則化係數。注意到L1正則化是權值的絕對值之和,是帶有絕對值符號的函式,因此是不完全可微的。機器學習的任務就是要通過一些方法(比如梯度下降)求出損失函式的最小值。當我們在原始損失函式後新增L1正則化項時,相當於對做了一個約束。令,則,此時我們的任務變成在約束下求出取最小值的解。考慮二維的情況,即只有兩個權值和,此時對於梯度下降法,求解的過程可以畫出等值線,同時L1正則化的函式也可以在的二維平面上畫出來。如下圖:
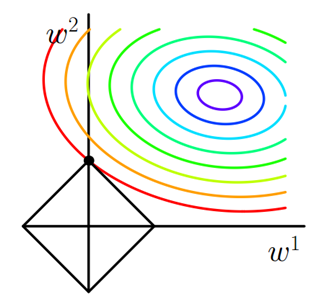
圖中等值線是的等值線,黑色方形是函式的圖形。在圖中,當等值線與圖形首次相交的地方就是最優解。上圖中與在的一個頂點處相交,這個頂點就是最優解。注意到這個頂點的值是。可以直觀想象,因為函式有很多『突出的角』(二維情況下四個,多維情況下更多),與這些角接觸的機率會遠大於與其它部位接觸的機率,而在這些角上,會有很多權值等於0,這就是為什麼L1正則化可以產生稀疏模型,進而可以用於特徵選擇。
而正則化前面的係數,可以控制圖形的大小。越小,的圖形越大(上圖中的黑色方框);越大,的圖形就越小,可以小到黑色方框只超出原點範圍一點點,這是最優點的值中的可以取到很小的值。
類似,假設有如下帶L2正則化的損失函式:
同樣可以畫出他們在二維平面上的圖形,如下:
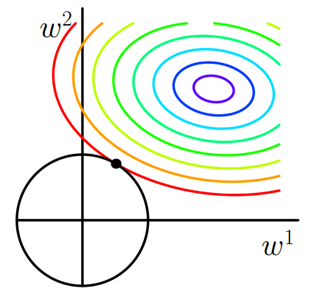
二維平面下L2正則化的函式圖形是個圓,與方形相比,被磨去了稜角。因此與相交時使得或等於零的機率小了許多,這就是為什麼L2正則化不具有稀疏性的原因。
L2正則化和過擬合
擬合過程中通常都傾向於讓權值儘可能小,最後構造一個所有引數都比較小的模型。因為一般認為引數值小的模型比較簡單,能適應不同的資料集,也在一定程度上避免了過擬合現象。可以設想一下對於一個線性迴歸方程,若引數很大,那麼只要資料偏移一點點,就會對結果造成很大的影響;但如果引數足夠小,資料偏移得多一點也不會對結果造成什麼影響,專業一點的說法是『抗擾動能力強』。
那為什麼L2正則化可以獲得值很小的引數?
以線性迴歸中的梯度下降法為例。假設要求的引數為,是我們的假設函式,那麼線性迴歸的代價函式如下:
那麼在梯度下降法中,最終用於迭代計算引數的迭代式為: 其中是learning rate. 上式是沒有新增L2正則化項的迭代公式,如果在原始代價函式之後新增L2正則化,則迭代公式會變成下面的樣子: 其中就是正則化引數。從上式可以看到,與未新增L2正則化的迭代公式相比,每一次迭代,都要先乘以一個小於1的因子,從而使得不斷減小,因此總得來看,是不斷減小的。
最開始也提到L1正則化一定程度上也可以防止過擬合。之前做了解釋,當L1的正則化係數很小時,得到的最優解會很小,可以達到和L2正則化類似的效果。
正則化引數的選擇
L1正則化引數
通常越大的可以讓代價函式在引數為0時取到最小值。下面是一個簡單的例子,這個例子來自Quora上的問答。為了方便敘述,一些符號跟這篇帖子的符號保持一致。
假設有如下帶L1正則化項的代價函式:
其中是要估計的引數,相當於上文中提到的以及. 注意到L1正則化在某些位置是不可導的,當足夠大時可以使得在時取到最小值。如下圖:
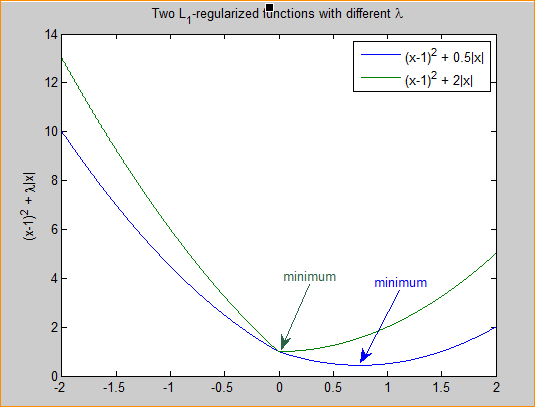
分別取和,可以看到越大的越容易使在時取到最小值。
L2正則化引數
從公式5可以看到,越大,衰減得越快。另一個理解可以參考圖2,越大,L2圓的半徑越小,最後求得代價函式最值時各引數也會變得很小。