
ConcurrentHashMap原始碼解析
阿新 • • 發佈:2018-12-10
初始化
先看看ConcurrentHashMap中幾個重要的屬性:
// 初始化容量大小 static final int DEFAULT_INITIAL_CAPACITY = 16; //預設負載因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; //預設併發級別 static final int DEFAULT_CONCURRENCY_LEVEL = 16; //最大的容量大小 static final int MAXIMUM_CAPACITY = 1 << 30; //每個segment最小的陣列大小 static final int MIN_SEGMENT_TABLE_CAPACITY = 2; //最大的segment個數 static final int MAX_SEGMENTS = 1 << 16; //獲取鎖的重試次數,避免頻繁修改下無限重試 static final int RETRIES_BEFORE_LOCK = 2; //用於獲取segments索引的mask值 final int segmentMask; final int segmentShift; //存放所有Segment的陣列 final Segment<K,V>[] segments;
// initialCapacity整個陣列的初始化大小 // loadFactor負載因子,跟HashMap一樣 // 併發級別。 public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; //計算並行級別。這裡是為了保證並行級別為2的n次方 while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //initialCapacity是整個map的容量大小,這裡要把容量平分到每個Segment上 int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; }
put方法
public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key); // 計算Segment陣列的下標位置 int j = (hash >>> segmentShift) & segmentMask; //如果Segment還沒建立,就先建立 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); //把資料put到segment中 return s.put(key, hash, value, false); }
進入ensureSegment方法,檢視建立segment的過程:
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
//建立ConcurrentHashMap的時候就初始化第一個Segment的原因就在這裡。就是為了使用第一個segment的陣列長度,loadFactor去初始化別的segment.
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
//初始化Segment內部的陣列
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
//使用CAS機制來初始化,防止併發問題
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
Segment解析
Segment繼承了ReentrantLock。 檢視其segment中的put方法:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//先使用tryLock嘗試獲取獨佔鎖。如果獲取成功,返回null,如果獲取不到,就進入scanAndLockForPut方法。
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
//Segment內部的陣列
HashEntry<K,V>[] tab = table;
//計算陣列下標
int index = (tab.length - 1) & hash;
//拿到這個陣列下標位置的值
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 如果原來已經有這個key,就覆蓋舊值
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果這個Segement超過了閾值,對這個Segement進行擴容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
繼續進入scanAndLockForPut方法:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//如果嘗試次數大於MAX_SCAN_RETRIES,就阻塞的等待獲取鎖。
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
這個方法的意思說白了也就是獲取鎖,順便初始化一下HashEnrty.
進入rehash方法,看看Segment中的陣列是如何擴容的:
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
get方法
總結
ConcurrentHashMap結構:
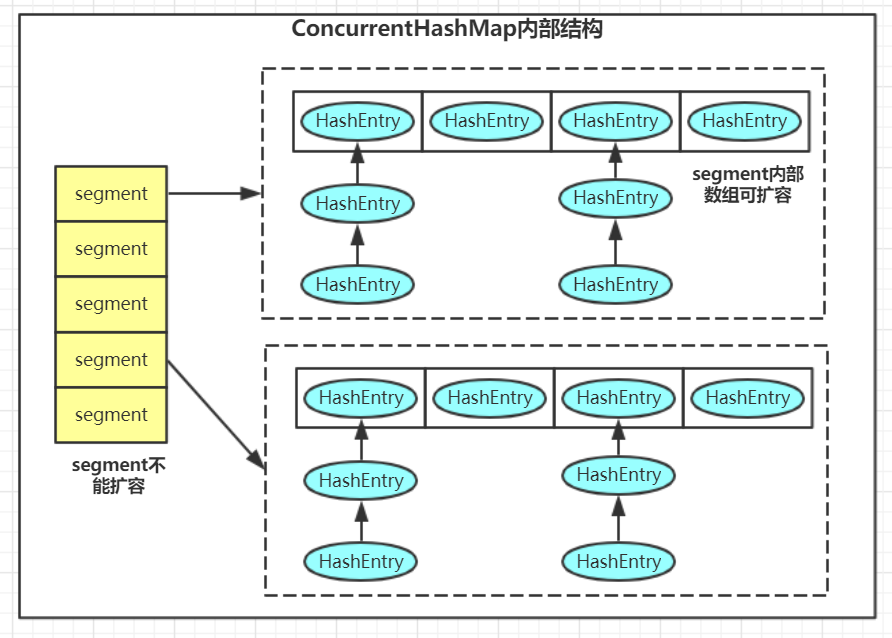
1. 預設的併發級別是16,也就是說預設會建立16個segment,並且初始化之後就不能修改。 併發級別為16的意思也就是說,預設支援16個併發寫,如果這16個寫操作發生在不同的segment上的話。
2. 每個segment的內部儲存原理就跟HashMap是類似的。
3.put操作的鎖是加在每個segment上而不是整個map上的,這樣就提高了併發性。