
資料探勘基礎-2.中文分詞
一、中文分詞基礎

• 切開的開始位置對應位是1,否則對應位是0,來表示“有/意見/分歧”的bit內容是:11010,通過識別1後面幾個0,就可以知道有幾個字切在一塊。
• 還可以用一個分詞節點序列來表示切分方案,例如“有/意見/分歧”的分詞節點序列是{0,1,3,5},代表0-1為一起,1-3為一起,3-5為一起,有向無環圖DAG就是採用這種方式。
1.常用方法
• 最常見的分詞方法是基於詞典匹配
–最大長度查詢(前向查詢,後向查詢)
前向:首先有一個詞典,句子從前往後切分,如果有存在一個最大長度的詞在詞典中,就在這切分。
後向:類似於前向。一般來說後向切分效果會好一點,因為中文重心一般位於句子後面。
• 資料結構
– 為了提高查詢效率,不要逐個匹配詞典中的詞。否則每個詞都需要遍歷一下詞典。
– 查詢詞典所佔的時間可能佔總分詞時間的1/3,為了保證切分速度,需要優化查詢詞典方法。
– Trie樹常用於加速分詞查詢詞典問題,查到了某個字只需要向下再查有沒有更長的詞,而不需要再遍歷整個詞表看看整個詞是否存在。
2.有向無環圖:(DAG)
例如:0:[0,1,3],表示0到1是個詞,0到3是個詞,自身也可以是個詞。
3.概率語言模型
• 假設需要分出來的詞在語料庫和詞表中都存在,最簡單的方法是按詞計算概率。
• 從統計思想的角度來看,分詞問題的輸入是一個字串C=c1,c2……cn ,輸出是一個詞串S=w1,w2……wm ,其中m<=n。對於一個特定的字串C,會有多個切分方案S對應,分詞的任務就是在這些S中找出一個切分方案S,使得P(S|C)的值最大。
• P(S|C)就是由字串C產生切分S的概率,也就是對輸入字串切分出最有可能的詞序列。
• P(C)只是一個用來歸一化的固定值,即這個句子在語料庫中佔的比例。從詞串恢復到漢字串的概率只有一種可能,所以P(C|S)=1。比較P(S1|C)和P(S2|C)的大小變成比較P(S1)和P(S2) 的大小。
• 例如:對於輸入字串C“南京市長江大橋”,有下面兩種切分可能:
– S1:南京市 / 長江 / 大橋
– S2:南京 / 市長 / 江大橋
• 這兩種切分方法分別叫做S1和S2。計算條件概率P(S1|C)和P(S2|C),然後根據P(S1|C)和P(S2|C)的值來決定選擇S1還是S2。P(C)是字串在語料庫中出現的概率。比如說語料庫中有1萬個句子,其中有一句是 “南京市長江大橋” 那麼P(C)=P(“南京市長江大橋” )=萬分之一。
• 假設每個詞出現的概率互相獨立,因為P(S1)=P(南京市,長江,大橋)=P(南京市)*P(長江)*P(大橋)> P(S2)=P(南京,市長,江大橋),所以選擇切分方案S1。
4.一元模型
假設每個詞之間的概率是上下文無關:
• 對於不同的S,m(分詞的數量)的值是不一樣的,一般來說m越大,P(S)會越小。也就是說,分出的詞越多,概率越小。(但是也不一定,只是有這個傾向)
• 因此:logP(wi ) = log(Freq w ) - logN
• 這個P(S)的計算公式也叫做基於一元模型的計算公式,它綜合考慮了切分出的詞數和詞頻。
P(S) = P(w1,w 2,...,wm ) ≈P(w1)×P(w 2 )×...×P(wm )∝logP(w1) +logP(w 2 ) +...+ logP(wm )
• 其中,P(w) 就是這個詞出現在語料庫中的概率。因為函式y=log(x),當x增大,y也會增大,所以是單調遞增函式。 ∝是正比符號。因為詞的概率小於1,所以取log後是負數。
• 最後算 logP(w)。取log是為了防止向下溢位,如果一個數太小,例如0.00000000000 0000000000000000001 可能會向下溢位。
• 如果這些對數值事前已經算出來了,則結果直接用加法就可以得到,加法比乘法速度更快。
5.N元模型
• 假設在日本,[和服]也是一個常見的詞。按照一元概率分詞,可能會把“產品和服務”分成[產品][和服][務]。為了切分更準確,要考慮詞所處的上下文。
• N元模型使用n個單片語成的序列來衡量切分方案的合理性:
• 估計單詞w1後出現w2的概率。根據條件概率的定義:
• 可以得到:P(w1,w2)= P(w1)P(w2|w1),同理:P(w1,w2,w3)= P(w1,w2)P(w3|w1,w2)
• 所以有:P(w1,w2,w3)= P(w1)P(w2|w1)P(w3|w1,w2)
• 更加一般的形式:
P(S)=P(w1,w2,...,wn)= P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1w2…wn-1)
• 這叫做概率的鏈規則。
• 如果一個詞的出現不依賴於它前面出現的詞,叫做一元模型(Unigram)。
• 如果簡化成一個詞的出現僅依賴於它前面出現的一個詞,那麼就稱為二元模型(Bigram)。
P(S)=P(w1,w2,...,wn)=P(w1) P(w2|w1) P(w3|w1,w2)…P(wn|w1w2…wn-1)≈P(w1) P(w2|w1) P(w3|w2)…P(wn|wn-1)
• 如果簡化成一個詞的出現僅依賴於它前面出現的兩個詞,就稱之為三元模型(Trigram)。
二、Jieba分詞
1.介紹
jieba分詞主要是基於統計詞典,構造一個字首詞典;然後利用字首詞典對輸入句子進行切分,得到所有的切分可能,根據切分位置,構造一個有向無環圖;通過動態規劃演算法,計算得到最大概率路徑,也就得到了最終的切分形式。
• 支援三種分詞模式
– 精確模式:將句子最精確的分開,適合文字分析
– 全模式:句子中所有可以成詞的詞語都掃描出來,速度快,不能解決歧義
– 搜尋引擎模式:在精確模式基礎上,對長詞再次切分,提高召回
• 支援繁體分詞
• 支援自定義字典
• 基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG)
• 採用了動態規劃查詢最大概率路徑, 找出基於詞頻的最大切分組合
• 對於未登入詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法
2.Jieba詞典載入
以“去北京大學玩”為例,作為待分詞的輸入文字。
離線統計的詞典形式如下,每一行有三列,第一列是詞,第二列是詞頻,第三列是詞性。
例如:
北京大學 2053 nt
大學 20025 n
去 123402 v
玩 4207 v
北京 34488 ns
3.字首詞典構建
首先是基於統計詞典構造字首詞典,如統計詞典中的詞“北京大學”的字首分別是“北”、“北京”、“北京大”、“北京大學”;詞“大學”的字首是“大”、“大學”。統計詞典中所有的詞形成的字首詞典如下所示,你也許會注意到“北京大”作為“北京大學”的字首,但是它的詞頻卻為0,這是為了便於後面有向無環圖的構建。
北京大學 2053
北京大 0
大學 20025
去 123402
玩 4207
北京 34488
北 17860
京 6583
大 144099
學 17482
4.有向無環圖構建
然後基於字首詞典,對輸入文字進行切分,對於“去”,沒有字首,那麼就只有一種劃分方式;對於“北”,則有“北”、“北京”、“北京大學”三種劃分方式;對於“京”,也只有一種劃分方式;對於“大”,則有“大”、“大學”兩種劃分方式,依次類推,可以得到以每個字開始的字首詞的劃分方式。
在jieba分詞中,對每個字都是通過在文字中的位置來標記的,因此可以構建一個以位置為key,相應劃分的末尾位置構成的列表為value的對映,如下所示:
0: [0]
1: [1,2,4]
2: [2]
3: [3,4]
4: [4]
5: [5]
對於0: [0],表示位置0對應的詞,就是0 ~ 0,就是“去”;對於1: [1,2,4],表示位置1開始,在1,2,4位置都是詞,就是1 ~ 1,1 ~ 2,1 ~ 4,即“北”,“北京”,“北京大學”這三個詞。對於每一種劃分,都將相應的首尾位置相連,例如,對於位置1,可以將它與位置1、位置2、位置4相連線,最終構成一個有向無環圖,如下所示:

5.最大概率路徑計算
在得到所有可能的切分方式構成的有向無環圖後,我們發現從起點到終點存在多條路徑,多條路徑也就意味著存在多種分詞結果,例如:
# 路徑1:0 -> 1 -> 2 -> 3 -> 4 -> 5,# 分詞結果1,去 / 北 / 京 / 大 / 學 / 玩
# 路徑2:0 -> 1 , 2 -> 3 -> 4 -> 5, # 分詞結果2,去 / 北京 / 大 / 學 / 玩
# 路徑3:0 -> 1 , 2 -> 3 , 4 -> 5, # 分詞結果3,去 / 北京 / 大學 / 玩
# 路徑4:0 -> 1 , 2 , 3 , 4 -> 5, # 分詞結果4,去 / 北京大學 / 玩
因此,我們需要計算最大概率路徑,也即按照這種方式切分後的分詞結果的概率最大。在計算最大概率路徑時,jieba分詞采用從後往前這種方式進行計算。為什麼採用從後往前這種方式計算呢?這裡反向是因為漢語句子的重心經常落在後面, 就是落在右邊, 因為通常情況下形容詞太多, 後面的才是主幹, 因此, 從右往左計算, 正確率要高於從左往右計算, 這個類似於逆向最大匹配。
在採用動態規劃計算最大概率路徑時,每到達一個節點,它前面的節點到終點的最大路徑概率已經計算出來。
6.原始碼分析
演算法流程
jieba.__init__.py中實現了jieba分詞介面函式cut(self, sentence, cut_all=False, HMM=True)。
jieba分詞介面主入口函式,會首先將輸入文字解碼為Unicode編碼,然後根據入參,選擇不同的切分方式,本文主要以精確模式進行講解,因此cut_all和HMM這兩個入參均為預設值;
切分方式選擇:
re_han = re_han_default
re_skip = re_skip_default
塊切分方式選擇:
cut_block = self.__cut_DAG
函式__cut_DAG(self, sentence)首先構建字首詞典,其次構建有向無環圖,然後計算最大概率路徑,最後基於最大概率路徑進行分詞,如果遇到未登入詞,則呼叫HMM模型進行切分。
字首詞典構建
get_DAG(self, sentence)函式會首先檢查系統是否初始化,如果沒有初始化,則進行初始化。在初始化的過程中,會構建字首詞典。
構建字首詞典的入口函式是gen_pfdict(self, f),解析離線統計詞典文字檔案,每一行分別對應著詞、詞頻、詞性,將詞和詞頻提取出來,以詞為key,以詞頻為value,加入到字首詞典中。對於每個詞,再分別獲取它的字首詞,如果字首詞已經存在於字首詞典中,則不處理;如果該字首詞不在字首詞典中,則將其詞頻置為0,便於後續構建有向無環圖。
jieba分詞中gen_pfdict函式實現如下:
# f是離線統計的詞典檔案控制代碼,檔案控制代碼對於開啟的檔案是唯一的識別依據
def gen_pfdict(self, f):
# 初始化字首詞典
lfreq = {}
ltotal = 0應該是統計總共的詞數,用來計算詞頻
f_name = resolve_filename(f) #獲得檔案的名字,即dict.txt
for lineno, line in enumerate(f, 1):
try:
# 解析離線詞典文字檔案
line = line.strip().decode('utf-8')
# 詞和對應的詞頻
word, freq = line.split(' ')[:2]
freq = int(freq)
lfreq[word] = freq
ltotal += freq
# 獲取該詞所有的字首詞
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
# 如果某字首詞不在字首詞典中,則將對應詞頻設定為0,
# 如第2章中的例子“北京大”
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
return lfreq, ltotal
為什麼jieba沒有使用trie樹作為字首詞典儲存的資料結構?
對於get_DAG()函式來說,用Trie資料結構,特別是在Python環境,記憶體使用量過大。經實驗,可構造一個字首集合解決問題。
該集合儲存詞語及其字首,如set(['數', '資料', '資料結', '資料結構'])。在句子中按字正向查詢詞語,在字首列表中就繼續查詢,直到不在字首列表中或超出句子範圍。大約比原詞庫增加40%詞條。
有向無環圖構建
有向無環圖,directed acyclic graphs,簡稱DAG,是一種圖的資料結構,顧名思義,就是沒有環的有向圖。DAG在分詞中的應用很廣,無論是最大概率路徑,還是其它做法,DAG都廣泛存在於分詞中。因為DAG本身也是有向圖,所以用鄰接矩陣來表示是可行的,但是jieba採用了Python的dict結構,可以更方便的表示DAG。最終的DAG是以{k : [k , j , ..] , m : [m , p , q] , ...}的字典結構儲存,其中k和m為詞在文字sentence中的位置,k對應的列表存放的是文字中以k開始且詞sentence[k: j + 1]在字首詞典中的 以k開始j結尾的詞的列表,即列表存放的是sentence中以k開始的可能的詞語的結束位置,這樣通過查詢字首詞典就可以得到詞。
get_DAG(self, sentence)函式進行對系統初始化完畢後,會構建有向無環圖。
從前往後依次遍歷文字的每個位置,對於位置k,首先形成一個片段,這個片段開始只包含位置k的字,然後就判斷該片段是否在字首詞典中:
1.如果這個片段在字首詞典中
1.1 如果詞頻大於0,就將這個位置i追加到以k為key的一個列表中;
1.2 如果詞頻等於0,如同第2章中提到的“北京大”,則表明字首詞典存在這個字首,但是統計詞典並沒有這個詞,繼續迴圈;
2.如果這個片段不在字首詞典中,則表明這個片段已經超出統計詞典中該詞的範圍,則終止迴圈;
3.然後該位置加1,然後就形成一個新的片段,該片段在文字的索引為[k:i+1],繼續判斷下一個片段是否在字首詞典中。
jieba分詞中get_DAG函式實現如下,
# 有向無環圖構建主函式
def get_DAG(self, sentence):
# 檢查系統是否已經初始化
self.check_initialized()
# DAG儲存向無環圖的資料,資料結構是dict
DAG = {}
N = len(sentence)
# 依次遍歷文字中的每個位置
for k in xrange(N):
tmplist = []
i = k
# 位置k形成的片段
frag = sentence[k]
# 判斷片段是否在字首詞典中
# 如果片段不在字首詞典中,則跳出本迴圈
# 也即該片段已經超出統計詞典中該詞的長度
while i < N and frag in self.FREQ:
# 如果該片段的詞頻大於0
# 將該片段加入到有向無環圖中
# 否則,繼續迴圈
if self.FREQ[frag]:
tmplist.append(i)
# 片段末尾位置加1
i += 1
# 新的片段較舊的片段右邊新增一個字
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG
以“去北京大學玩”為例,最終形成的有向無環圖為:
{0: [0], 1: [1,2,4], 2: [2], 3: [3,4], 4: [4], 5: [5]}
最大概率路徑計算
有向無環圖DAG的每個節點,都是帶權的,對於在字首詞典裡面的詞語,其權重就是它的詞頻;我們想要求得route = (w1,w2,w3,...,wn),使得 ∑weight(wi) 最大。
如果需要使用動態規劃求解,需要滿足兩個條件,重複子問題、最優子結構
重複子問題
對於節點wi和其可能存在的多個後繼節點Wj和Wk:
任意通過Wi到達Wj的路徑的權重 = 該路徑通過Wi的路徑權重 + Wj的權重,也即{Ri -> j} = {Ri + weight(j)}
任意通過Wi到達Wk的路徑的權重 = 該路徑通過Wi的路徑權重 + Wk的權重,也即{Ri -> k} = {Ri + weight(k)}
即對於擁有公共前驅節點Wi的節點Wj和Wk,需要重複計算達到Wi的路徑的概率。
最優子結構
對於整個句子的最優路徑Rmax和一個末端節點Wx,對於其可能存在的多個前驅Wi,Wj,Wk...,設到達Wi,Wj,Wk的最大路徑分別是Rmaxi,Rmaxj,Rmaxk,有,
Rmax = max(Rmaxi,Rmaxj,Rmaxk,...) + weight(Wx)
於是,問題轉化為,求解Rmaxi,Rmaxj,Rmaxk,...等,組成了最優子結構,子結構裡面的最優解是全域性的最優解的一部分。
狀態轉移方程為:Rmax = max{(Rmaxi,Rmaxj,Rmaxk,...) + weight(Wx)}
jieba分詞中計算最大概率路徑的主函式是calc(self, sentence, DAG, route),函式根據已經構建好的有向無環圖計算最大概率路徑。函式是一個自底向上的動態規劃問題,它從sentence的最後一個字(N-1)開始倒序遍歷sentence的每個字(idx)的方式,計運算元句sentence[idx ~ N-1]的概率對數得分。然後將概率對數得分最高的情況以(概率對數,詞語最後一個位置)這樣的元組儲存在route中。函式中,logtotal為構建字首詞頻時所有的詞頻之和的對數值,這裡的計算都是使用概率對數值,可以有效防止下溢問題。
jieba分詞中calc函式實現如下,
def calc(self, sentence, DAG, route):
N = len(sentence)
# 初始化末尾為0
route[N] = (0, 0)
logtotal = log(self.total)
# 從後到前計算
for idx in xrange(N - 1, -1, -1):#遍歷0-N-1,-1代表遞減的方式
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])
print "root:",route
DAG :{0: [0, 1], 1: [1], 2: [2, 3, 5], 3: [3], 4: [4, 5], 5: [5], 6: [6, 7], 7: [7]}
計算過程:
root: {8: (0, 0), 7: (-8.702713881905304, 7)}
root: {8: (0, 0), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7)}
root: {8: (0, 0), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7)}
root: {8: (0, 0), 4: (-25.495037477673915, 5), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7)}
root: {3: (-34.70541057789988, 3), 4: (-25.495037477673915, 5), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7), 8: (0, 0)}
root: {2: (-25.495037477673915, 5), 3: (-34.70541057789988, 3), 4: (-25.495037477673915, 5), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7), 8: (0, 0)}
root: {1: (-33.72931380325669, 1), 2: (-25.495037477673915, 5), 3: (-34.70541057789988, 3), 4: (-25.495037477673915, 5), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7), 8: (0, 0)}
root: {0: (-34.76895126093703, 1), 1: (-33.72931380325669, 1), 2: (-25.495037477673915, 5), 3: (-34.70541057789988, 3), 4: (-25.495037477673915, 5), 5: (-18.81251125649701, 5), 6: (-8.682096638586806, 7), 7: (-8.702713881905304, 7), 8: (0, 0)}
三、馬爾科夫模型
1.馬爾科夫
• 每個狀態只依賴之前有限個狀態
– N階馬爾科夫:依賴之前n個狀態
p(w1,w2,w3,w4…wn) = p(w1)p(w2|w1)p(w3|w1,w2)……p(wn|w1,w2,……,wn-1) =p(w1) p(w2|w1) p(w3|w2)……p(wn|wn-1)
– 1階馬爾科夫:僅僅依賴前一個狀態
p(w1=今天,w2=我,w3=寫,w4=了,w5=一個,w6=程式)=p(w1=今天)p(w2=我|w1=今天)p(w3=寫|w2=我)……p(w6=程式|w5=一個)
• 引數
– 狀態,由數字表示,假設共有M個(有多少字就有多少個M)
– 初始概率,由πk表示
– 狀態轉移概率,由表示ak,l表示,詞k變換到詞l
這些引數值用統計的方法來獲得,即最大似然估計法。
2.最大似然法
最大似然估計,就是利用已知的樣本結果,反推最有可能(最大概率)導致這樣結果的引數值,在這裡就是根據樣本的情況,近似地得到概率值,所以下面的等號嚴格來說是約等號。
– 狀態轉移概率ak,l
• P(St+1=l|St=k)=l緊跟k出現的次數/k出現的總次數
– 初始概率πk
• P(S1=k)=k作為序列開始的次數/觀測序列總數
• 馬爾科夫模型是對一個序列資料建模,但有時我們需要對兩個序列資料建模,所以需要隱馬爾可夫模型。
– 例如:
• 機器翻譯:源語言序列 <-> 目標語言序列
• 語音識別:語音訊號序列 <-> 文字序列
• 詞性標註:文字序列 <-> 詞性序列
– 寫/一個/程式
– Verb/Num/Noun
四、隱馬爾科夫模型
1.觀察序列和隱藏序列
• 通常其中一個序列是我們觀察到的,背後隱藏的序列是我們要尋找的
– 把觀察到的序列表示為O,隱藏的序列表示為S
• 觀察序列O中的資料通常是由對應的隱藏序列資料決定的,聲波訊號彼此間相互獨立
• 隱藏序列資料間相互依賴,通常構成了馬爾科夫序列
– 例如,語音識別中聲波訊號每段訊號都是相互獨立的,有對應的文字決定
– 對應的文字序列中相鄰的字相互依賴,構成Markov鏈。
• HMM引數
– 狀態s,由數字表示,假設共有M個
– 觀測o,由數字表示,假設共有N個
– 初始概率,由πk表示
– 狀態轉移概率,由ak,l表示
• ak,l = P (st+1=l|st=k) k,l = 1,2, … , M
– 發射概率,由bk(u) 表示
2.初始概率
在5_codes/word_seg/jieba/jieba/posseg中,可以看到jieba的各個概率值
('S', 'uv'): -8.15808672228609,這個代表某單個詞屬於’uv’詞性的概率是-8.15808672228609
3.轉移概率
4.發射概率
5.HMM生成過程
生成第一個狀態,然後依次由當前狀態生成下一個狀態,最後每個狀態發射出一個觀察值。
6.隱馬模型例項
觀測細胞在不同時刻的健康程度(cell state)細胞健康程度不易直接觀測,不過可以通過觀測一種熒光蛋白( GFP)的密集程度對健康程度有一個間接瞭解。
cell state: { Healthy, OK, Sick}
GFP intensity: {High, Average, Low}
cell state 就是隱藏狀態,GFP intensity 就是觀測狀態
P(Healthy)=0.5,P(OK)=0.3,P(Sick)=0.2
那給定這麼一個 HMM,能做什麼?假設我們觀測到這麼一個 GFP intensity 序列:
出現這麼一個觀測序列的概率是多少?P(Hi, Av, Av, Lo, Lo)= ?
這個觀測序列背後最有可能的 cell state 序列是什麼?
三個基本問題
– 模型引數估計,需要現有以下個θ概率值
在jieba模型中,已經有了θ值,現在考慮如何根據θ計算最大概率的S。
7.前後向演算法
前向概率是聯合概率,後向概率是條件概率。
前向概率-簡單演算法
簡單演算法:將t之前所有的情況全部列出來,並將概率相加。
對於剛才的例子:
前向概率-改進演算法 動態規劃
後向概率
其他概率
8.隱馬爾科夫模型引數估計
完全資料:
9.HMM應用
基於字首詞典和動態規劃方法可以實現分詞,但是如果沒有字首詞典或者有些詞不在字首詞典中,jieba分詞一樣可以分詞,基於漢字成詞能力的HMM模型識別未登入詞。利用HMM模型進行分詞,主要是將分詞問題視為一個序列標註(sequence labeling)問題,其中,句子為觀測序列,分詞結果為狀態序列。首先通過語料訓練出HMM相關的模型,然後利用Viterbi演算法進行求解,最終得到最優的狀態序列,然後再根據狀態序列,輸出分詞結果。
序列標註
序列標註,就是將輸入句子和分詞結果當作兩個序列,句子為觀測序列,分詞結果為狀態序列,當完成狀態序列的標註,也就得到了分詞結果。
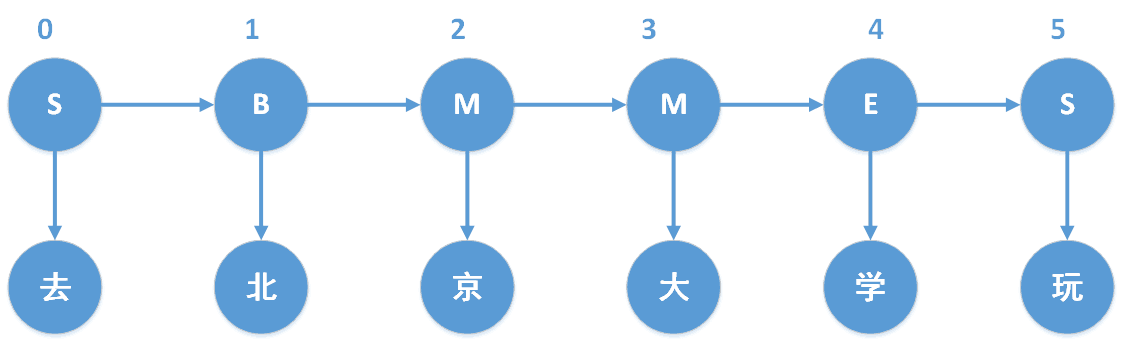
以“去北京大學玩”為例,我們知道“去北京大學玩”的分詞結果是“去 / 北京大學 / 玩”。對於分詞狀態,由於jieba分詞中使用的是4-tag,因此我們以4-tag進行計算。4-tag,也就是每個字處在詞語中的4種可能狀態,B、M、E、S,分別表示Begin(這個字處於詞的開始位置)、Middle(這個字處於詞的中間位置)、End(這個字處於詞的結束位置)、Single(這個字是單字成詞)。具體如下圖所示,“去”和“玩”都是單字成詞,因此狀態就是S,“北京大學”是多字組合成的詞,因此“北”、“京”、“大”、“學”分別位於“北京大學”中的B、M、M、E。
HMM模型作的兩個基本假設:
1.齊次馬爾科夫性假設,即假設隱藏的馬爾科夫鏈在任意時刻t的狀態只依賴於其前一時刻的狀態,與其它時刻的狀態及觀測無關,也與時刻t無關;
2.觀測獨立性假設,即假設任意時刻的觀測只依賴於該時刻的馬爾科夫鏈的狀態,與其它觀測和狀態無關,
HMM模型有三個基本問題:
1.概率計算問題,給定模型 λ=(A,B,π)和觀測序列 O=(o1,o2,...,oT),怎樣計算在模型λ下觀測序列O出現的概率 P(O|λ),也就是前向(Forward-backward)演算法;
2.學習問題,已知觀測序列 O=(o1,o2,...,oT)O=(o1,o2,...,oT) ,估計模型 λ=(A,B,π)λ=(A,B,π) ,使得在該模型下觀測序列的概率 P(O|λ)P(O|λ) 儘可能的大,即用極大似然估計的方法估計引數;
3.預測問題,也稱為解碼問題,已知模型 λ=(A,B,π)和觀測序列 O=(o1,o2,...,oT),求對給定觀測序列條件概率 P(S|O)P(S|O) 最大的狀態序列 I=(s1,s2,...,sT),即給定觀測序列,求最有可能的對應的狀態序列;
其中,jieba分詞主要涉及第三個問題,也即預測問題。
這裡仍然以“去北京大學玩”為例,那麼“去北京大學玩”就是觀測序列。而“去北京大學玩”對應的“SBMMES”則是隱藏狀態序列,我們將會注意到B後面只能接(M或者E),不可能接(B或者S);而M後面也只能接(M或者E),不可能接(B或者S)。
狀態初始概率表示,每個詞初始狀態的概率;jieba分詞訓練出的狀態初始概率模型如下所示。
P={'B': -0.26268660809250016, 'E': -3.14e+100, 'M': -3.14e+100, 'S': -1.4652633398537678}
其中的概率值都是取對數之後的結果(可以讓概率相乘轉變為概率相加),其中-3.14e+100代表負無窮,對應的概率值就是0。這個概率表說明一個詞中的第一個字屬於{B、M、E、S}這四種狀態的概率,如下可以看出,E和M的概率都是0,這也和實際相符合:開頭的第一個字只可能是每個詞的首字(B),或者單字成詞(S)。這部分對應jieba/finaseg/ prob_start.py,具體可以進入原始碼檢視。
狀態轉移概率是馬爾科夫鏈中很重要的一個知識點,一階的馬爾科夫鏈最大的特點就是當前時刻T = i的狀態states(i),只和T = i時刻之前的n個狀態有關,即{states(i-1),states(i-2),...,states(i-n)}。再看jieba中的狀態轉移概率,其實就是一個巢狀的詞典,數值是概率值求對數後的值,如下所示,
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155}, 'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937}, 'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226}, 'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}
P['B']['E']代表的含義就是從狀態B轉移到狀態E的概率,由P['B']['E'] = -0.58971497368-54513,表示當前狀態是B,下一個狀態是E的概率對數是-0.5897149736854513,對應的概率值是0.6,相應的,當前狀態是B,下一個狀態是M的概率是0.4,說明當我們處於一個詞的開頭時,下一個字是結尾的概率要遠高於下一個字是中間字的概率,符合我們的直覺,因為二個字的詞比多個字的詞更常見。這部分對應jieba/finaseg/prob_trans.py,具體可以檢視原始碼。
狀態發射概率,根據HMM模型中觀測獨立性假設,發射概率,即觀測值只取決於當前狀態值,也就如下所示,
P(observed[i],states[j]) = P(states[j]) * P(observed[i] | states[j])
其中,P(observed[i] | states[j])就是從狀態發射概率中獲得的。
P={'B': {'一': -3.6544978750449433, '丁': -8.125041941842026, '七': -7.817392401429855, ... 'S': {':': -15.828865681131282, '一': -4.92368982120877, '丁': -9.024528361347633,
P['B']['一']代表的含義就是狀態處於'B',而觀測的字是‘一’的概率對數值為P['B']['一'] = -3.6544978750449433。這部分對應jieba/finaseg/prob_emit.py,具體可以檢視原始碼。
viterbi演算法
Viterbi演算法實際上是用動態規劃求解HMM模型預測問題,即用動態規劃求概率路徑最大(最優路徑)。一條路徑對應著一個狀態序列。根據動態規劃原理,最優路徑具有這樣的特性:如果最優路徑在時刻t通過結點 it ,那麼這一路徑從結點 it 到終點 iT 的部分路徑,對於從 it 到 iT的所有可能的部分路徑來說,必須是最優的。因為假如不是這樣,那麼it 到 iT就有另一條更好的部分路徑存在,如果把它和從 it 到達 iT的部分路徑連線起來,就會形成一條比原來的路徑更優的路徑,這是矛盾的。依據這個原理,我們只需要從時刻t=1開始,遞推地計算在時刻t狀態i的各條部分路徑的最大概率,直至得到時刻t=T狀態為i的各條路徑的最大概率。時刻t=T的最大概率就是最優路徑的概率 P,最優路徑的終結點 iT也同時得到。之後,為了找出最優路徑的各個結點,從終結點 iT開始,由後向前逐步求得結點 iT−1,...,...,i1 ,最終得到最優路徑 I=(i1,i2,...,iT)I=(i1,i2,...,iT) 。(不理解)
首先先定義兩個變數,δ,ψ,定義在時刻t狀態i的所有單個路徑 (i1,i2,...,it)(i1,i2,...,it) 中概率最大值為
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] # tabular
path = {}
# 時刻t = 0,初始狀態
for y in states: # init
V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT)
path[y] = [y]
# 時刻t = 1,...,len(obs) - 1
for t in xrange(1, len(obs)):
V.append({})
newpath = {}
# 當前時刻所處的各種可能的狀態
for y in states:
# 獲取發射概率對數
em_p = emit_p[y].get(obs[t], MIN_FLOAT)
# 分別獲取上一時刻的狀態的概率對數,該狀態到本時刻的狀態的轉移概率對數,本時刻的狀態的發射概率對數
# 其中,PrevStatus[y]是當前時刻的狀態所對應上一時刻可能的狀態
(prob, state) = max(
[(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]])
V[t][y] = prob
# 將上一時刻最優的狀態 + 這一時刻的狀態
newpath[y] = path[state] + [y]
path = newpath
# 最後一個時刻
(prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES')
# 返回最大概率對數和最優路徑
return (prob, path[state])
輸出分詞結果
由Viterbi演算法得到狀態序列,根據狀態序列得到分詞結果。其中狀態以B開頭,離它最近的以E結尾的一個子狀態序列或者單獨為S的子狀態序列,就是一個分詞。以”去北京大學玩“的隱藏狀態序列”SBMMES“為例,則分詞為”S / BMME / S“,對應觀測序列,也就是”去 / 北京大學 / 玩”。
10.原始碼分析
jieba分詞中HMM模型識別未登入詞的原始碼目錄在jieba/finalseg/下,
__init__.py 實現了HMM模型識別未登入詞;
prob_start.py 儲存了已經訓練好的HMM模型的狀態初始概率表;
prob_trans.py 儲存了已經訓練好的HMM模型的狀態轉移概率表;
prob_emit.py 儲存了已經訓練好的HMM模型的狀態發射概率表;
HMM模型引數訓練
來源主要有兩個,一個是網上能下載到的1998人民日報的切分語料還有一個msr的切分語料。另一個是我自己收集的一些txt小說,用ictclas把他們切分(可能有一定誤差),然後用python指令碼統計詞頻。
要統計的主要有三個概率表:1)位置轉換概率,即B(開頭),M(中間),E(結尾),S(獨立成詞)四種狀態的轉移概率;2)位置到單字的發射概率,比如P("和"|M)表示一個詞的中間出現”和"這個字的概率;3) 詞語以某種狀態開頭的概率,其實只有兩種,要麼是B,要麼是S。
基於HMM模型的分詞流程
jieba分詞會首先呼叫函式cut(sentence),cut函式會先將輸入句子進行解碼,然後呼叫__cut函式進行處理。__cut函式就是jieba分詞中實現HMM模型分詞的主函式。__cut函式會首先呼叫viterbi演算法,求出輸入句子的隱藏狀態,然後基於隱藏狀態進行分詞。
def __cut(sentence):
global emit_P
# 通過viterbi演算法求出隱藏狀態序列
prob, pos_list = viterbi(sentence, 'BMES', start_P, trans_P, emit_P)
begin, nexti = 0, 0
# print pos_list, sentence
# 基於隱藏狀態序列進行分詞
for i, char in enumerate(sentence):
pos = pos_list[i]
# 字所處的位置是開始位置
if pos == 'B':
begin = i
# 字所處的位置是結束位置
elif pos == 'E':
# 這個子序列就是一個分詞
yield sentence[begin:i + 1]
nexti = i + 1
# 單獨成字
elif pos == 'S':
yield char
nexti = i + 1
# 剩餘的直接作為一個分詞,返回
if nexti < len(sentence):
yield sentence[nexti:]
五、實踐
案例1:中文分詞和webserver
1. yum install git(如果自己電腦沒有git的話)
3. [[email protected] test]# python demo.py進入test資料夾後,隨便執行一個
4. [[email protected] test]# cp demo.py badou.py在此模板上修改
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")//將jieba模組載入進來,這裡的jieba模組是jieba資料夾下的jieba資料夾
import jieba
import jieba.posseg
import jieba.analyse
s = "體專案。2013年,實現營業收入0萬元,實現淨利潤-139.13萬元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w)) //分出單詞和詞的權重
5. [[email protected] word_seg]# cd segment/,這裡的web是開源工具,編輯word_seg.py
#encoding=utf-8
import web
import sys
sys.path.append("./")//這裡需要把jieba裡面的jieba模組載入進去,所以要注意路徑問題。
import jieba
import jieba.posseg
import jieba.analyse
urls = (
'/', 'index',預設的方式
'/test', 'test',
)
app = web.application(urls, globals())
class index:
def GET(self):
params = web.input()
context = params.get('context', '')//自定義輸入http://192.168.101.10:9999/? context=語句
seg_list = jieba.cut(context)
result = ", ".join(seg_list)
print("=====>", result)列印結果
return result
def GET(self):
print web.input()
return '222'
if __name__ == "__main__":
app.run()
[[email protected] segment]# python web_seg.py 9999
http://192.168.101.10:9998/?context=加入購物車,結果為亂碼,需要在瀏覽器修改編碼方式,在選項卡里面工具,修改為自動檢測或者utf-8等。
結果:加入, 購物車
案例2:jieba和mapreduce結合
1.run.sh
#HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
#STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH_1="/music_meta.txt.small"
其中music_meta.txt.small 資料如下
8920791333 天路MV-韓紅
8920845333 初音未來
一、中文分詞基礎
• 切開的開始位置對應位是1,否則對應位是0,來表示“有/意見/分歧”的bit內容是:11010,通過識別1後面幾個0,就可以知道有幾個字切在一塊。
• 還可以用一個分詞節點序列來表示切分方案,例如“有/意見/分歧”的分詞節點序列是{0,1,3,5}
本文結合程式碼例項待你上手python資料探勘和機器學習技術。
本文包含了五個知識點:
1. 資料探勘與機器學習技術簡介
2. Python資料預處理實戰
3. 常見分類演算法介紹
本部落格根據非常好的excel資料而編寫,使用python語言操作,預計使用一週的時間更新完成。需要《非常好的excel資料》word文件,歡迎發郵件給[email protected],免費發放。
1、幾種常見的統計函式
2、分佈函式
① ② ,求P{X=5
環境 centos7,solr7.5.0
1. 新建core
從 solr-7.5.0/example/files/conf 作為配置檔案模板,建立core,名為mycore
2.下載分詞器
從https://search.maven.org/search?q=g:com
本部落格根據非常好的excel資料而編寫,使用python語言操作,預計使用一週的時間更新完成。需要《非常好的excel資料》word文件,歡迎發郵件給[email protected],免費發放。這篇部落格對應《非常好的excel資料》裡的第3章節。
1.假設檢驗實驗
1
第五章 分類 其他分類
貝葉斯分類器
貝葉斯定理:把類的先驗知識和從資料中收集的新證據相結合的統計原理。
公式:
P(Y|X)=P(X|Y)*P(Y)/P(X)
X是屬性集,Y是類變數
把X和Y看成隨機變數,用P(Y|X)以概率的方式捕捉二者之間的關係,這個條件
一、資料探勘的基本任務
利用分類與預測、聚類分析、關聯規則、時序模式、偏差檢測、智慧推薦等方法,幫助企業提取資料中蘊含的商業價值,提升企業的競爭力。
二、資料探勘建模過程
定義挖掘目標:任務目標和完
一、文字相似度
相似度度量指的是計算個體間相似程度,一般使用距離來度量,相似度值越小,距離越大,相似度值越大,距離越小。在說明文字相似度概念和計算方式之前,先回顧下餘弦相似度。
1.餘弦相似度
衡量文字相似度最常用的方法是使用餘弦相似度。
– 空間中,兩個向量夾角的
介紹了關聯規則挖掘的一些基本概念和經典的Apriori演算法,Aprori演算法利用頻繁集的兩個特性,過濾了很多無關的集合,效率提高不少,但是我們發現Apriori演算法是一個候選消除演算法,每一次消除都需要掃描一次所有資料記錄,造成整個演算法在面臨大資料集時顯得無能
一. 基於Python的資料探勘 基本架構
1. matplotlib, 圖形化
2. pandas,資料探勘的關鍵, 提供各種挖掘分析的演算法
3. numpy, 提供基本的統計
scipy, 提供各種數學公式
4. python common lib,py
1. 矩陣知識:
//特徵值,行列式,秩,對稱矩陣,單位矩陣,正定半正定,雅可比等等!!
正交矩陣:
如果:AA'=E(E為單位矩陣,A'表示“矩陣A的轉置矩陣”。)或A′A=E,則n階實矩陣A稱為正交矩陣, 若A為正交陣,則滿足以下條件:
1) AT是正交矩陣
2)( Basis(基礎):
SSE(Sum of Squared Error, 平方誤差和)
SAE(Sum of Absolute Error, 絕對誤差和)
SRE(Sum of Relative Error, 相對誤差和)
MSE(Mean Squared Error, 均方誤差)
RMSE(R
在上一篇部落格中簡單介紹了實驗環境和流程,這一篇我們繼續。
第一步,下載搜狗中文語料庫。連結:http://www.sogou.com/labs/dl/c.html
我們下載
一、定義:
文字挖掘:從大量文字資料中抽取出有價值的知識,並且利用這些知識重新組織資訊的過程。
二、語料庫(Corpus)
語料庫是我們要分析的所有文件的集合。
import os
import os.path
filePaths = [] #定義一個數組變數
#再用
如下演算法實現分詞:
1. 基於字首詞典實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖 (DAG);
作者這個版本中使用字首字典實現了詞庫的儲存(即dict.txt檔案中的內容),而棄用之前版本的trie樹儲存詞庫,想想也是,python中實現的trie樹是基於dict型
NLP進階-詳解Jieba分詞工具
一、Jieba分詞工具
1. 三種模式
• 精確模式:將句子最精確的分開,適合文字分析
• 全模式:句子中所有可以成詞的詞語都掃描出來,速度快,不能解決歧義
• 搜尋引擎模式:在精確模式基礎上,對長詞再次切分,提高召回
2.實現的演算法
• 基於Tri word cut 用法 地址 api mas 精確 == com api參考地址:https://github.com/fxsjy/jieba/blob/master/README.md
安裝自行百度
基本用法:
import jieba
#全模式
word = jie inf git deb seq 效果 analysis stream fix sps CoreNLP是由斯坦福大學開源的一套Java NLP工具,提供諸如:詞性標註(part-of-speech (POS) tagger)、命名實體識別(named entity recog
首先需要的準備好ik分詞器,因為Solr6.0版本比較高,所以ik分詞器的版本最好高一點,我是用ikanalyzer-solr5來搭建的. 第一步 解壓ikanalyzer-solr5.
第二步 複製ik-analyzer-solr5-5.x.jar並將其放在solr-6.2.1\se
摘要: 下面是一些關於大資料探勘的知識點,今天和大家一起來學習一下。1. 資料、資訊和知識是廣義資料表現的不同形式。2. 主要知識模式型別有:廣義知識,關聯知識,類知識,預測型知識,特異型知識3. web挖掘研究的主要流派有:Web結構挖掘、Web使用挖掘、Web內容挖掘4. 一般地說,KD 相關推薦
資料探勘基礎-2.中文分詞
利用Python學習資料探勘【2】
資料探勘基礎之統計學的分佈函式
學習筆記:從0開始學習大資料-29. solr增加ik中文分詞器並匯入doc,pdf文件全文檢索
資料探勘基礎之統計學的假設檢驗實驗
資料探勘基礎導論學習筆記(五)
《Python資料分析與挖掘實戰》筆記(一):資料探勘基礎
資料探勘基礎-1.文字相似度
資料探勘(2)關聯規則FpGrowth演算法
python 資料探勘基礎 入門
資料探勘基礎知識-矩陣(分解)
NLP&資料探勘基礎知識
資料探勘 文字分類(二)蒐集中文語料庫與ICTCLAS分詞
資料探勘01---文字分析(jieba分詞和詞雲繪製)
【結巴分詞資料彙編】結巴中文分詞原始碼分析(2)
資料探勘乾貨總結(二)--NLP進階-詳解Jieba分詞工具
python基礎===jieba模塊,Python 中文分詞組件
開源中文分詞工具探析(六):Stanford CoreNLP
Solr6.2搭建和配置ik中文分詞器
零基礎學習大資料探勘的33個知識點整理