
哈夫曼編碼測試
哈夫曼樹介紹
1.定義:給定n個權值作為n個葉子結點,構造一棵二叉樹,若該樹的帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹(Huffman Tree)。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。
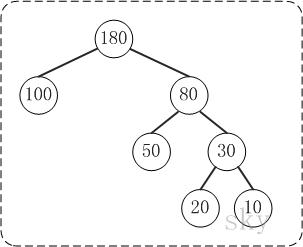
2.術語
(01) 路徑和路徑長度
定義:在一棵樹中,從一個結點往下可以達到的孩子或孫子結點之間的通路,稱為路徑。通路中分支的數目稱為路徑長度。若規定根結點的層數為1,則從根結點到第L層結點的路徑長度為L-1。
例子:100和80的路徑長度是1,50和30的路徑長度是2,20和10的路徑長度是3。
(02) 結點的權及帶權路徑長度
定義:若將樹中結點賦給一個有著某種含義的數值,則這個數值稱為該結點的權。結點的帶權路徑長度為:從根結點到該結點之間的路徑長度與該結點的權的乘積。
例子:節點20的路徑長度是3,它的帶權路徑長度= 路徑長度 * 權 = 3 * 20 = 60。
(03) 樹的帶權路徑長度
定義:樹的帶權路徑長度規定為所有葉子結點的帶權路徑長度之和,記為WPL。
例子:示例中,樹的WPL= 1100 + 280 + 320 + 310 = 100 + 160 + 60 + 30 = 350。
3.構造
假設有n個權值,則構造出的哈夫曼樹有n個葉子結點。 n個權值分別設為 w1、w2、…、wn,則哈夫曼樹的構造規則為:
(1) 將w1、w2、…,wn看成是有n 棵樹的森林(每棵樹僅有一個結點);
(2) 在森林中選出兩個根結點的權值最小的樹合併,作為一棵新樹的左、右子樹,且新樹的根結點權值為其左、右子樹根結點權值之和;
(3)從森林中刪除選取的兩棵樹,並將新樹加入森林;
(4)重複(2)、(3)步,直到森林中只剩一棵樹為止,該樹即為所求得的哈夫曼樹。
哈夫曼樹設計構造
HuffmanTreeNode設計
- 一個哈夫曼樹結點應包括父結點、左右孩子結點,權值,還有元素(元素是在進行哈夫曼編碼解碼時才想到並使用的)
還有實現Comparable介面,用結點權值來決定大小。getter和setter方法不再描述。
public class HuffmanTreeNode implements Comparable<HuffmanTreeNode> { private int weight; private HuffmanTreeNode parent,left,right; private char element; public HuffmanTreeNode(int weight, char element ,HuffmanTreeNode parent, HuffmanTreeNode left, HuffmanTreeNode right) { this.weight = weight; this.element = element; this.parent = parent; this.left = left; this.right = right; } @Override public int compareTo(HuffmanTreeNode huffmanTreeNode) { return this.weight - huffmanTreeNode.getWeight(); }
構造哈夫曼樹
1.定義一個根節點
private HuffmanTreeNode mRoot; // 根結點
2.建構函式
這裡將會使用一個最小堆,用來每次取出權值最小的兩個哈夫曼樹結點來構造成一個新的哈夫曼樹結點,並新增到最小堆中去。直到所有元素構造成一個哈夫曼樹結點,設為根節點。
public HuffmanTree(HuffmanTreeNode[] array) {
HuffmanTreeNode parent = null;
ArrayHeap<HuffmanTreeNode> heap = new ArrayHeap();
for (int i=0;i<array.length;i++)
{
heap.addElement(array[i]);
}
for(int i=0; i<array.length-1; i++) {
HuffmanTreeNode left = heap.removeMin();
HuffmanTreeNode right = heap.removeMin();
parent = new HuffmanTreeNode(left.getWeight()+right.getWeight(),' ',null,left,right);
left.setParent(parent);
right.setParent(parent);
heap.addElement(parent);
}
mRoot = parent;
}哈夫曼樹編碼與解碼
哈夫曼樹編碼
編碼的方法寫在了哈夫曼樹的構造中。
採用了中序遍歷把所有葉子結點都新增到一個數組中來,然後對這些葉子結點逐個進行編碼,從下往上,若為左孩子,則為0,反之為1,放入棧中,直至根節點,再將棧中元素全部取出,得到該結點的編碼。
public String[] getEncoding() {
ArrayList<HuffmanTreeNode> arrayList = new ArrayList();
inOrder(mRoot,arrayList);
for (int i=0;i<arrayList.size();i++)
{
HuffmanTreeNode node = arrayList.get(i);
String result ="";
int x = node.getElement()-'a';
Stack stack = new Stack();
while (node!=mRoot)
{
if (node==node.getParent().getLeft())
stack.push(0);
if (node==node.getParent().getRight())
stack.push(1);
node=node.getParent();
}
while (!stack.isEmpty())
{
result +=stack.pop();
}
codes[x] = result;
}
return codes;
}
protected void inOrder( HuffmanTreeNode node,
ArrayList<HuffmanTreeNode> tempList)
{
if (node != null)
{
inOrder(node.getLeft(), tempList);
if (node.getElement()!=' ')
tempList.add(node);
inOrder(node.getRight(), tempList);
}
}哈夫曼樹解碼
解碼這裡一開始的思路是從編碼結果中取出若干元素,對比各個字元編碼結果,得到解碼結果,沒有去做,感覺太麻煩,而且沒有規律性,很難做。
參看了這篇部落格:哈夫曼樹及解碼
自己才理清思路,開始編寫,
這個思路是:從編碼結果逐個讀取,若為0,則指向結點左孩子,反之為其右孩子,如果其沒有左右孩子,便為我們所找的葉子結點,將其對應元素新增進來,並重新從根結點開始,直至讀取完畢。
//進行解碼
String result2 = "";
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) == '0') {
if (huffmanTreeNode.getLeft() != null) {
huffmanTreeNode = huffmanTreeNode.getLeft();
}
} else {
if (s1.charAt(i) == '1') {
if (huffmanTreeNode.getRight() != null) {
huffmanTreeNode = huffmanTreeNode.getRight();
}
}
}
if (huffmanTreeNode.getLeft() == null && huffmanTreeNode.getRight() == null) {
result2 += huffmanTreeNode.getElement();
huffmanTreeNode = huffmanTree.getmRoot();
}
}碼雲連結
感悟
- 哈夫曼樹的編碼解碼也比較有意思,編碼的思路自己一開始理清了,解碼其實就是一個逆過程,但自己沒有想到,直到參看資料才有了思路。