
20172311-哈夫曼編碼測試
20172311-哈夫曼編碼測試
哈夫曼編碼與哈夫曼樹
哈夫曼樹
哈夫曼樹又稱最優二叉樹,是一種帶權路徑長度最短的二叉樹。所謂樹的帶權路徑長度,就是樹中所有的葉結點的權值乘上其到根結點的路徑長度(若根結點為0層,葉結點到根結點的路徑長度為葉結點的層數)。樹的帶權路徑長度記為WPL= (W1L1+W2L2+W3L3+...+WnLn),N個權值Wi(i=1,2,...n)構成一棵有N個葉結點的二叉樹,相應的葉結點的路徑長度為Li(i=1,2,...n)。可以證明哈夫曼樹的WPL是最小的。哈夫曼編碼
哈夫曼編碼(HuffmanCoding)是一種編碼方式,哈夫曼編碼是可變字長編碼(VLC)的一種。uffman於1952年提出一種編碼方法,該方法完全依據字元出現概率來構造異字頭的平均長 度最短的碼字,有時稱之為最佳編碼,一般就叫作Huffman編碼。哈夫曼編碼是一種無字首編碼。解碼時不會混淆。其主要應用在資料壓縮,加密解密等場合。
哈夫曼編碼步驟
1、對給定的n個權值{W1,W2,W3,...,Wi,...,Wn}構成n棵二叉樹的初始集合F={T1,T2,T3,...,Ti,...,Tn},其中每棵二叉樹Ti中只有一個權值為Wi的根結點,它的左右子樹均為空。(為方便在計算機上實現演算法,一般還要求以Ti的權值Wi的升序排列。)
2、在F中選取兩棵根結點權值最小的樹作為新構造的二叉樹的左右子樹,新二叉樹的根結點的權值為其左右子樹的根結點的權值之和。
3、從F中刪除這兩棵樹,並把這棵新的二叉樹同樣以升序排列加入到集合F中。
4、重複二和三兩步,直到集合F中只有一棵二叉樹為止。
舉例如下:
假如我有A,B,C,D,E五個字元,出現的頻率(即權值)分別為5,4,3,2,1,那麼我們第一步先取兩個最小權值作為左右子樹構造一個新樹,即取1,2構成新樹,其結點為1+2=3,如圖:
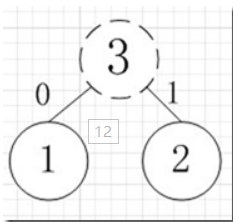
虛線為新生成的結點,第二步再把新生成的權值為3的結點放到剩下的集合中,所以集合變成{5,4,3,3},再根據第二步,取最小的兩個權值構成新樹,如圖:
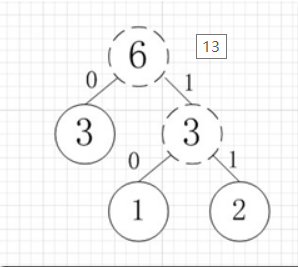
再依次建立哈夫曼樹,如下圖:
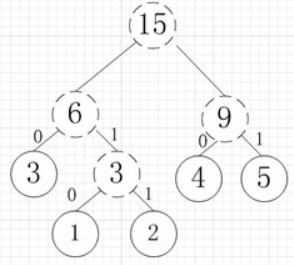
其中各個權值替換對應的字元即為下圖:
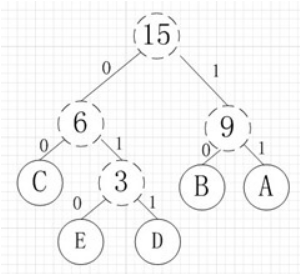
所以各字元對應的編碼為:A->11,B->10,C->00,D->011,E->010
用Java實現哈夫曼編碼
建立哈夫曼樹的結點類
該結點類中包括哈夫曼樹的父節點,左孩子和右孩子;權值以及char型別的元素(存放26個英文字母用)。程式碼如下:
//哈夫曼樹的節點類 public class huffmanNode implements Comparable<huffmanNode> { private int weight; private huffmanNode parent,left,right; private char element; public huffmanNode(int weight, char element , huffmanNode parent, huffmanNode left, huffmanNode right) { this.weight = weight;//權值 this.element = element;//char元素 this.parent = parent;//父節點 this.left = left;//左孩子 this.right = right;//右孩子 } public int getWeight() { return weight; } @Override public int compareTo(huffmanNode huffmanNode) { return this.weight - huffmanNode.getWeight(); } public huffmanNode getParent() { return parent; } public void setParent(huffmanNode parent) { this.parent = parent; } public huffmanNode getLeft() { return left; } public void setLeft(huffmanNode left) { this.left = left; } public huffmanNode getRight() { return right; } public void setRight(huffmanNode right) { this.right = right; } public char getElement() { return element; } public void setElement(char element) { this.element = element; } }
建立哈夫曼樹類
1.編寫建構函式,接收一個哈夫曼節點類的陣列,使用最小堆生成相應的哈夫曼樹。建構函式如下:
public huffmanTree(huffmanNode[] huffmanArray) {
huffmanNode parent = null;
SmallArrayHeap<huffmanNode> heap = new SmallArrayHeap<>();
for (int i=0;i<huffmanArray.length;i++)
{
heap.addElement(huffmanArray[i]);
}
for(int i=0; i<huffmanArray.length-1; i++) {
huffmanNode left = heap.removeMin(); //左孩子是最小節點
huffmanNode right = heap.removeMin();
parent = new huffmanNode(left.getWeight()+right.getWeight(),' ',null,left,right);
left.setParent(parent);
right.setParent(parent);
heap.addElement(parent);
}
root = parent;
} 2.編寫一個哈夫曼樹的中序遍歷方法用於得到基本元素的編碼的陣列,中序遍歷方法如下:
protected void inOrder( huffmanNode node,
ArrayList<huffmanNode> tempList)
{
if (node != null)
{
inOrder(node.getLeft(), tempList);
if (node.getElement()!=' ')
tempList.add(node);
inOrder(node.getRight(), tempList);
}
}
3.利用無序列表和棧以及中序遍歷方法實現得到需要的基本元素的編碼的陣列的方法,方法如下:
public String[] getEncoding() {
ArrayList<huffmanNode> arrayList = new ArrayList();
inOrder(root,arrayList);
for (int i=0;i<arrayList.size();i++)
{
huffmanNode node = arrayList.get(i);
String result ="";
int x = node.getElement()-'a';
Stack stack = new Stack();
while (node!= root)
{
if (node==node.getParent().getLeft())
stack.push(0);
if (node==node.getParent().getRight())
stack.push(1);
node=node.getParent();
}
while (!stack.isEmpty())
{
result +=stack.pop();
}
codes[x] = result;
}
return codes;
} 使用哈夫曼樹編碼解碼測試
1.讀取檔案,並列印檔案中各字母出現的頻率,程式碼如下:
File file = new File("C:\\Users\\user\\IdeaProjects\\socialsea\\socialsea\\src\\HuffmanTest\\readFile");
Scanner scan = new Scanner(file);
String s = scan.nextLine();
System.out.println(s);
int[] array = new int[26];
for (int i = 0; i < array.length; i++) {
array[i] = 0;
}
for (int i = 0; i < s.length(); i++) {
char x = s.charAt(i);
array[x - 'a']++;
}
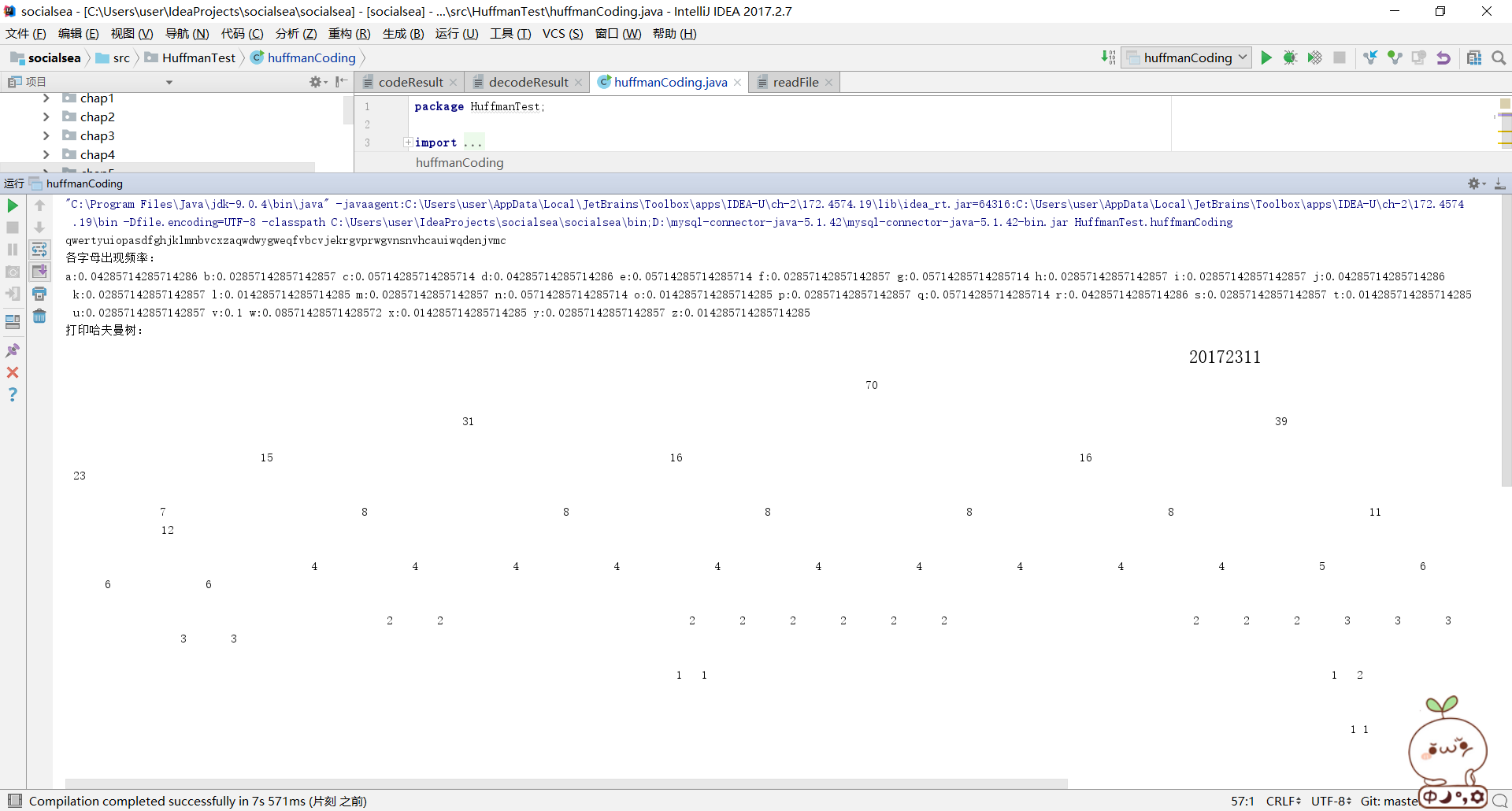
System.out.println("各字母出現頻率:");
for (int i = 0; i < array.length; i++) {
System.out.print((char)('a'+i)+":"+(double) array[i] / s.length()+" ");
} 2.構造有26個字母元素的哈夫曼樹,程式碼如下:
huffmanNode[] huffmanTreeNodes = new huffmanNode[array.length];
for (int i = 0; i < array.length; i++) {
huffmanTreeNodes[i] = new huffmanNode(array[i], (char) ('a' + i), null, null, null);
}
huffmanTree huffmanTree = new huffmanTree(huffmanTreeNodes); 3.使用哈夫曼樹類中getEncoding()方法得到a——z各字母對應的編碼並打印出來。程式碼如下:
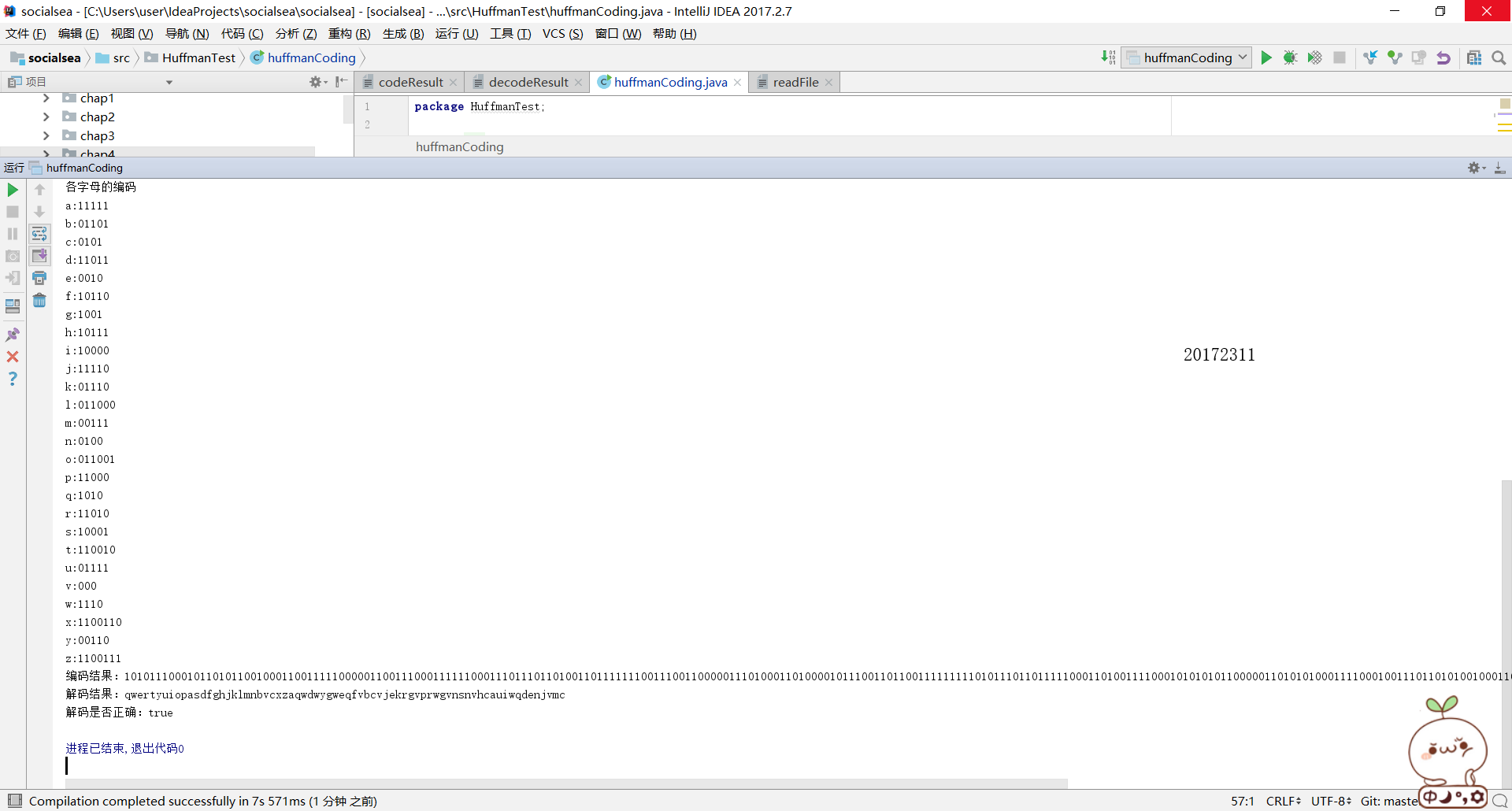
System.out.println("各字母的編碼");
String[] codes = huffmanTree.getEncoding();
for (int i = 0; i < codes.length; i++) {
System.out.println((char) ('a' + i) + ":" + codes[i]);
}4.對readFile檔案中內容進行編碼並輸出,然後寫入到codeResult檔案中去,程式碼如下:
//進行編碼:
String result = "";
for (int i = 0; i < s.length(); i++) {
int x = s.charAt(i) - 'a';
result += codes[x];
}
System.out.println("編碼結果:"+result);
//寫入檔案
File file1 = new File("C:\\Users\\user\\IdeaProjects\\socialsea\\socialsea\\src\\HuffmanTest\\codeResult");
FileWriter fileWriter = new FileWriter(file1);
fileWriter.write(result);
fileWriter.close();5.從codeResult檔案中讀取編碼後的內容並解碼,然後寫入到decodeResult檔案中,程式碼如下:
//從檔案讀取
Scanner scan1 = new Scanner(file1);
String s1 = scan1.nextLine();
huffmanNode huffmanTreeNode = huffmanTree.getRoot();
//進行解碼
String result2 = "";
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) == '0') {
if (huffmanTreeNode.getLeft() != null) {
huffmanTreeNode = huffmanTreeNode.getLeft();
}
} else {
if (s1.charAt(i) == '1') {
if (huffmanTreeNode.getRight() != null) {
huffmanTreeNode = huffmanTreeNode.getRight();
}
}
}
if (huffmanTreeNode.getLeft() == null && huffmanTreeNode.getRight() == null) {
result2 += huffmanTreeNode.getElement();
huffmanTreeNode = huffmanTree.getRoot();
}
}
System.out.println("解碼結果:"+result2);
//寫入檔案
File file2 = new File("C:\\Users\\user\\IdeaProjects\\socialsea\\socialsea\\src\\HuffmanTest\\decodeResult");
FileWriter fileWriter1 = new FileWriter(file2);
fileWriter1.write(result2);
fileWriter1.close(); 實驗結果截圖
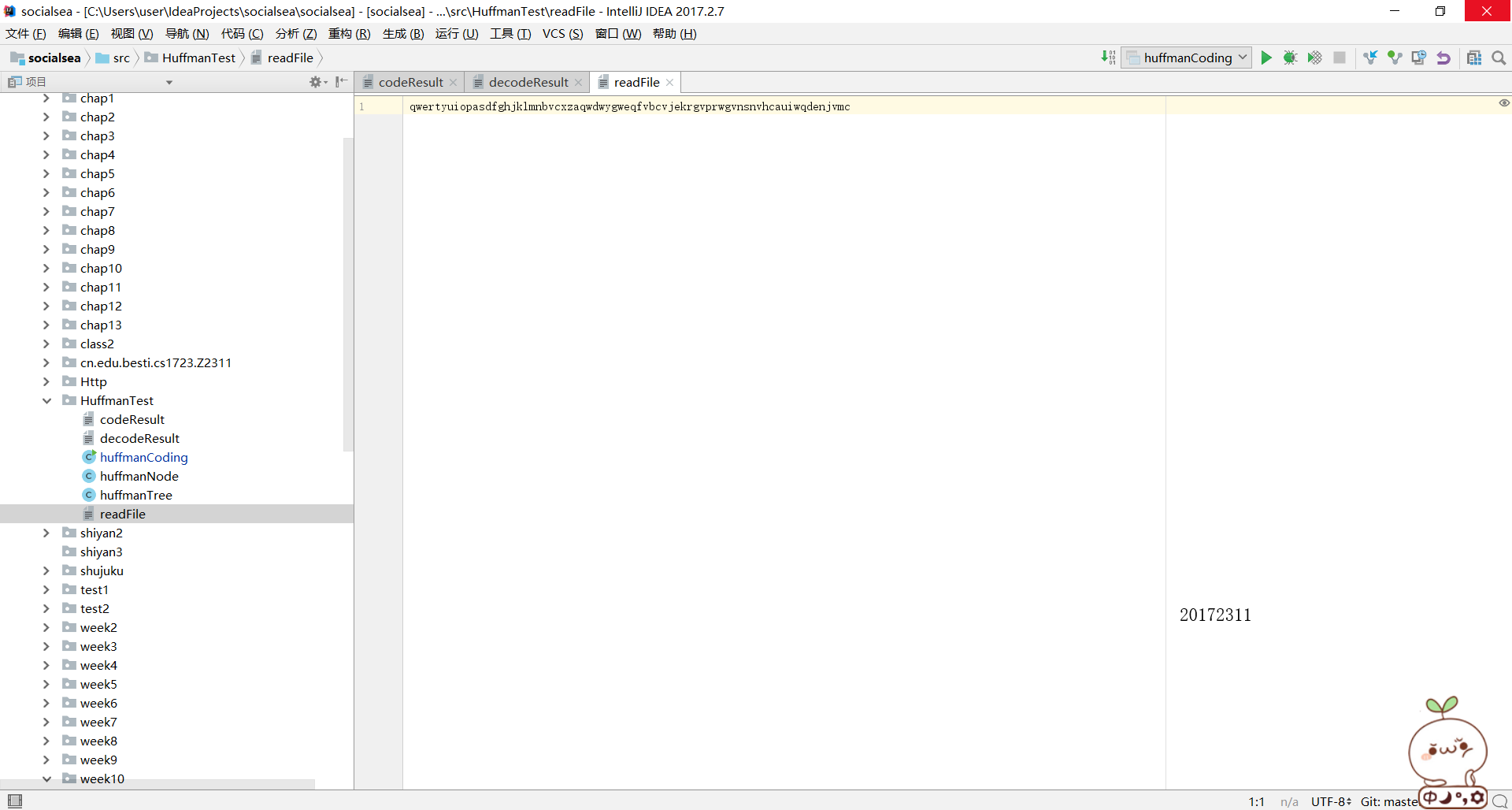
readFile檔案
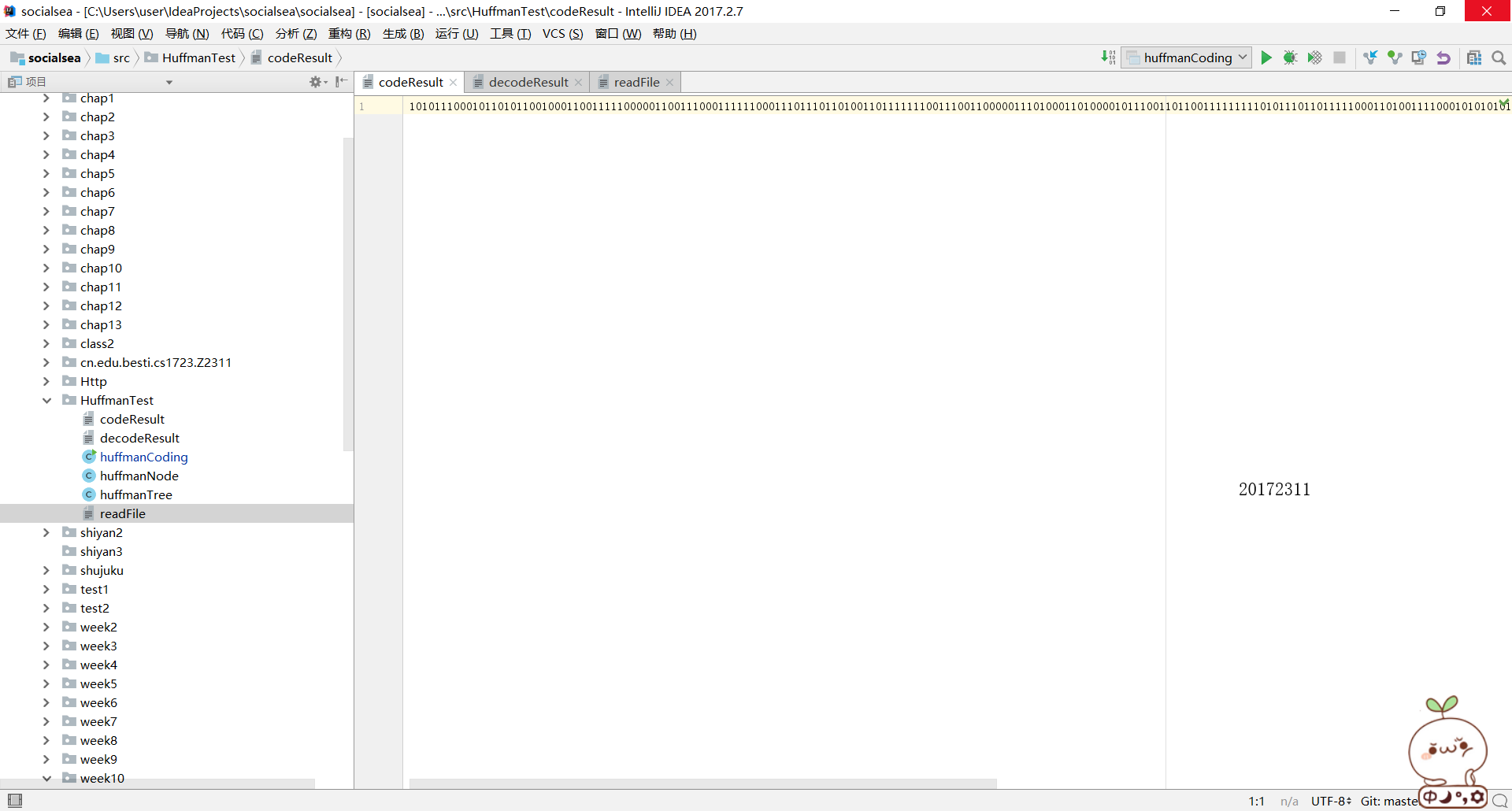
codeResult檔案
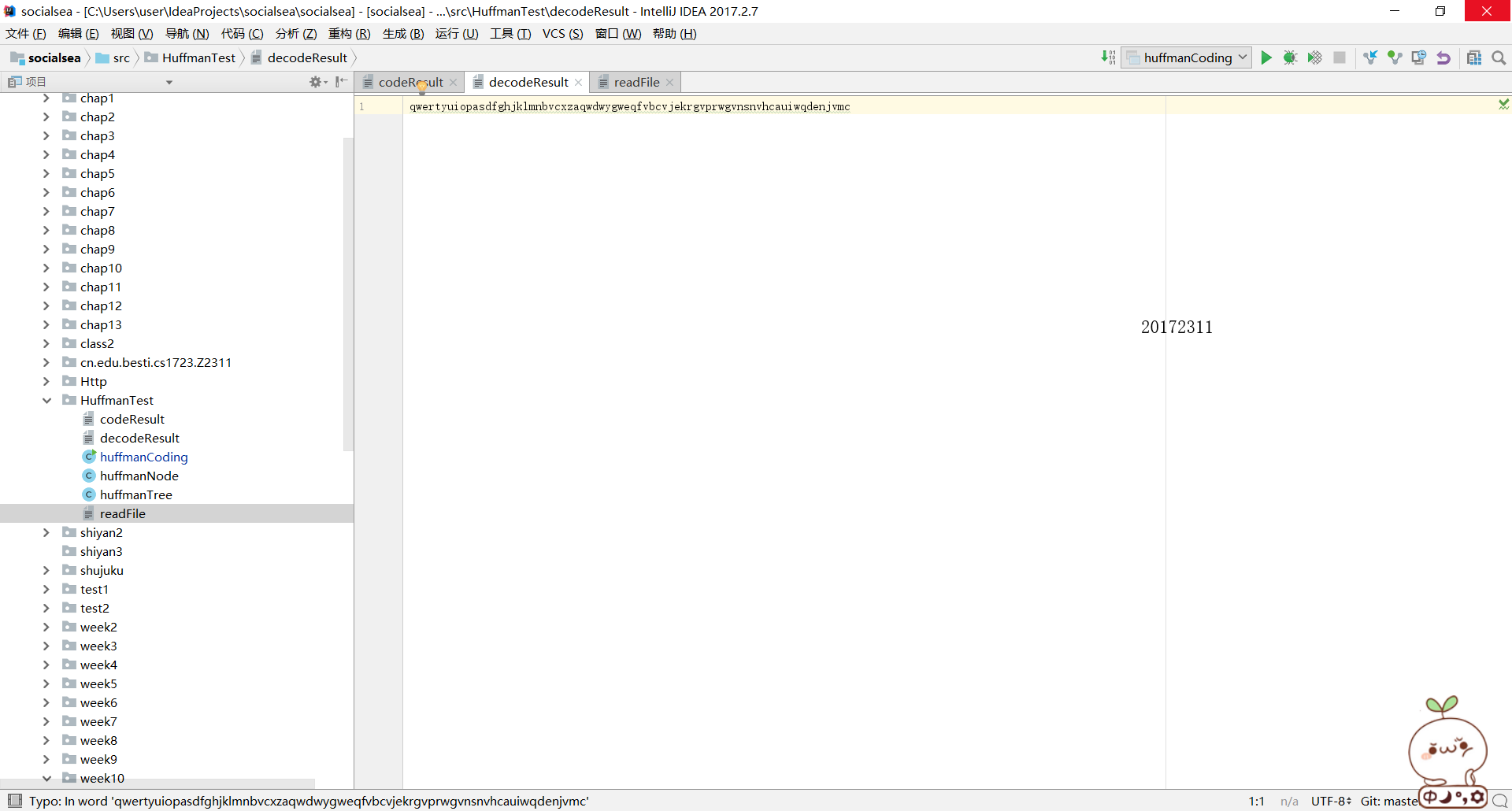
decodeResult檔案
執行結果
碼雲連結
感悟
剛開始的時候感覺通過哈夫曼樹實現編碼與解碼肯定是非常複雜,首先每個字母對應的編碼去怎麼設計就好像無法完成,但是在學習的過程中逐漸發現其實也沒有想象中那麼難,把大的問題拆分開來,一步一步的去解決,最終就能將問題解決了,本次實驗讓我受益匪淺!