
哈夫曼編碼壓縮解壓縮實現&不同型別檔案壓縮比的測試
壓縮原理及步驟&&壓縮比的計算
壓縮原理及步驟
壓縮的第一步:
將一個檔案以各個字元出現的次數為權值建立哈夫曼樹,這樣每個字元可以用從樹根到該字元所在到葉子節點的路徑來表示。(左為0,右為1)
壓縮第二步:
哈夫曼編碼有一個很重要的特性:每個字元編碼不會成為另一個編碼的字首。這個特性保證了即使我們把不同長度的編碼存在一起,仍然也可以把它們分離開,不會出現認錯人的衝突。
那麼我們就可以把所有的字元按照原有順序用其編碼替換,構建新的字串作為其壓縮後的串。
壓縮第三步:
有的小夥伴可能要問了,這樣一搞不是越變越多了麼,哪是什麼壓縮。哈哈,大部分孩子可能已經想到啦,既然單位編碼除了0就是1為什麼還要用位元組來存呢,用位來儲存,8個單位編碼為1位
。這樣轉化完成後的串才是真正壓縮後的串。
當然,因為我們還要進行解壓,所以這裡構建的樹也要和串一併加入到檔案。
壓縮比的計算
- 介紹完步驟,我們來計算一下哈夫曼編碼的壓縮比。
- 用len表示串長度,path(i)表示每i個字元的編碼長度,那麼根據上文所介紹的原理,我們可以很容易知道,串通過哈夫曼壓縮後的長度為
- sum(path(i)) 1<=i<=len
- 這個式子雖然正確但不能直觀的感受的壓縮比,所以我們來假設一種平均情況進行估算
- 假如一個串長度為n,一共包含m個不同的字元,那麼所構建成的哈夫曼樹的總結點數為 2*m-1。
- 假設,n很大,那麼可以忽略樹的儲存所佔用的空間。如果假設此串中每個字元出現的次數都是相同的,那麼也可以假設,它們所生成的哈夫曼樹是完全二叉樹.
- 即每個葉子(字元)的深度為log(m)+1,則路徑長度為log(m)。log(m)即為該串字元的平均路徑長度,那麼壓縮後的串長為log(m)/8。
- 由上可以得出平均壓縮比的公式為:
- n*log(2*m-1)/8/n = log(2*m-1)/8;
- 可見壓縮比的大小主要與m有關,即不同的字元越少越好。
- ascii碼的範圍為0~255,共有256種不同字元,代入上式得
- log(2*256-1) = 6.23 …
向上取整為7(路徑個數哪有小數)
7/8 = 0.875 = %87.5
所以哈夫曼編碼的平均壓縮比為%87.5。
強調
上述的假設在計算情況中忽略了對哈夫曼樹的儲存,所以只在檔案總長度與不同字元總數相差很大時才生效。
考慮ascii碼外的其它語言
一開始為考慮這個鑽了牛角尖,想著去統一用wchar_t儲存或是轉為Unicode等等什麼的。但其實不必那麼複雜,因為漢字(不僅僅漢字,任何字元都是這樣的)都是以位元組為單位的,由多個位元組組成的,將其分開對待,因為最終解壓時恢復原串還是按照原有順序組裝,所以和純英文檔案的實現沒有什麼區別);
需要注意的地方
所有字元路徑的總長不一定整除8,所以在按為儲存時,要注意最後一項不足8的情況,進行補零,且要將補零的個數儲存起來。
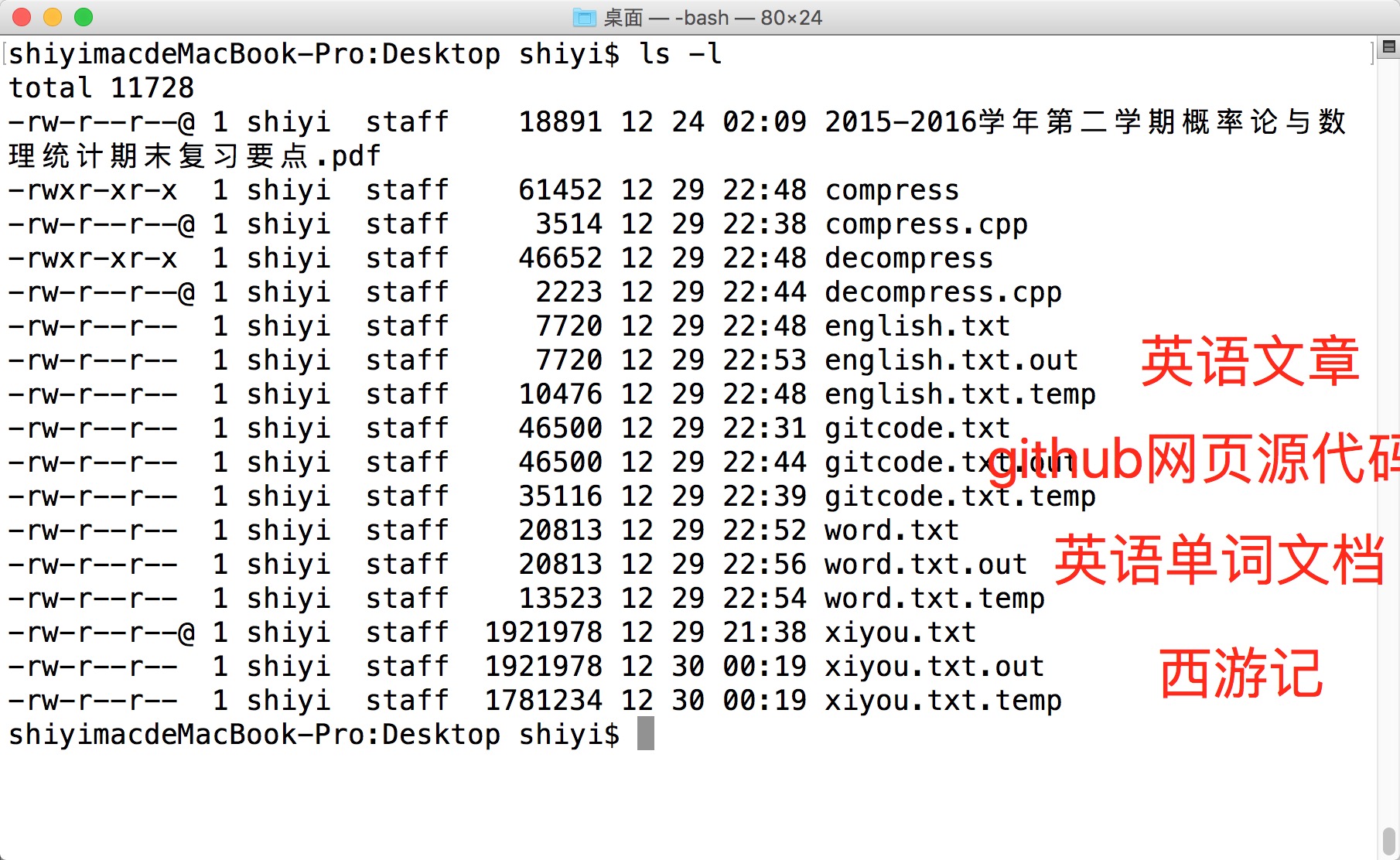
程式碼對不同型別文件的壓縮比測試情況
英語文章
樣例文件:西遊記英文節選
原大小:7720
壓縮後:10476
壓縮比:1.356 – %135
此處的檔案壓縮後不降反增,因為檔案本身大小與不同字元的數量相差並不大,加上對樹的儲存後,空間大於壓縮前。
純漢語文件
樣例文件:西遊記
原大小:1921978
壓縮後:1781234
壓縮比:0.926 – %92
不同漢字的數量多。
程式程式碼
樣例文件:github網頁原始碼
原大小:46500
壓縮後:35116
壓縮比:0.755 – %76
原始碼中全是英文字母與符號,不超過100種,總大小與其相差近500倍,且程式碼重複詞比較多。
英語單詞文件
樣例文件:英語單詞5000
原大小:20813
壓縮後:13523
壓縮比:0.649 – %65
原始碼
壓縮程式原始檔 compress.cpp
#include <iostream>
#include <locale>
#include <cstdlib>
#include <fstream>
#include <vector>
#include <queue>
using namespace std;
const long long MAX_SIZE = 10000000000;//
const int MAX_TYPE = 300;
unsigned int *f = new unsigned int[MAX_TYPE];//計數
unsigned int *p = new unsigned int[MAX_TYPE];//計下標
char *v = new char[MAX_TYPE];
char filename[20];
char *s[MAX_TYPE];
struct Node
{
unsigned int weight, parent, lson, rson;
Node(){};
}HuffmanTree[MAX_TYPE<<1];
struct NodeCmp
{
bool operator()(int a, int b)
{
return HuffmanTree[a].weight > HuffmanTree[b].weight;
}
};
int CreatTree(char *str, long long len)
{
int num = 1;
for(int i=0;i<len;i++)
f[str[i]]++;
cout<<"len::"<<len<<endl;
for(int i=0;i<len;i++)
{
if(f[str[i]])
{
HuffmanTree[num].weight = f[str[i]];
HuffmanTree[num].lson = 0;
HuffmanTree[num].rson = 0;
f[str[i]] = 0;
if(p[str[i]] == 0)
p[str[i]] = num;
v[num] = str[i];
++num;
}
}
cout<<"num::"<<num<<endl;
return num;
}
void CodingTree(int num)
{
priority_queue<int, vector<int>, NodeCmp> q;
for(int i=1;i<num;i++)
q.push(i);
int len = num;
for(int i=0;i<num-2;i++)
{
int x = q.top(); q.pop();
int y = q.top(); q.pop();
HuffmanTree[len].weight = HuffmanTree[x].weight + HuffmanTree[y].weight;
HuffmanTree[x].parent = HuffmanTree[y].parent = len;
HuffmanTree[len].lson = y;
HuffmanTree[len].rson = x;
q.push(len++);
}
}
void FindPath(int num)
{
char *t = new char[num];
t[num-1] = '\0';
for(int i=1;i<num;i++)
{
int son = i, father = HuffmanTree[i].parent;
int start = num-1;
while(father != 0)
{
--start;
if(HuffmanTree[father].rson == son)
t[start] = '1';
else
t[start] = '0';
son = father;
father = HuffmanTree[father].parent;
}
s[i] = new char[num - start];
strcpy(s[i], &t[start]);
}
}
void print(int num, long long len, char *str)
{
ofstream fout(filename, ios::out);
fout<<num<<endl;
for(int i=1;i<num;i++)
{
fout<<s[i]<<endl;
fout<<v[i]<<endl;
}
long long pos = 0;
char *ans = new char[MAX_SIZE];
int now = 7;
for(long long i=0;i<len;i++)
{
int k = 0;
while(s[p[str[i]]][k] != '\0')
{
ans[pos] |= (s[p[str[i]]][k]-'0')<<now--;
if(now < 0)
{
now = 7;
pos++;
}
++k;
}
}
int zero = 0;
if(now != 7) zero = now%7+1, pos++;
fout<<zero<<" "<<pos<<endl;
fout.write(ans, sizeof(char)*pos);
fout.close();
cout<<"zero::"<<zero<<endl;
}
int main(int argc, char **argv)
{
sprintf(filename, "%s.temp", argv[1]);
ifstream fin(argv[1],ios::ate | ios::in);
if(!fin)
{
cout<<"File open error!"<<endl;
return 0;
}
long long size = fin.tellg();
if(size > MAX_SIZE)
{
cout<<"Too long!"<<endl;
return 0;
}
fin.seekg(0, ios::beg);
char *str = new char[size+1];
fin.read(str,size);
fin.close();
int num = CreatTree(str, size);
CodingTree(num);
FindPath(num);
print(num, size, str);
return 0;
}解壓程式原始檔 compress.cpp
#include <iostream>
#include <locale>
#include <cstdlib>
#include <fstream>
#include <vector>
#include <queue>
using namespace std;
char filename[20];
const long long MAX_SIZE = 10000000000;//
const int MAX_TYPE = 300;
struct Node
{
char v;
int parent, lson, rson;
Node(){};
}HuffmanTree[MAX_TYPE<<1];
char *str = new char[MAX_SIZE];
char *ans = new char[MAX_SIZE];
void CreatTree(char *t, char v, int &pos)
{
int root = 0;
for(int i=0;t[i]!='\0';i++)
{
if(t[i] == '1')
{
if(HuffmanTree[root].rson == 0)
HuffmanTree[root].rson = pos++;
root = HuffmanTree[root].rson;
}
else
{
if(HuffmanTree[root].lson == 0)
HuffmanTree[root].lson = pos++;
root = HuffmanTree[root].lson;
}
}
HuffmanTree[root].v = v;
}
void print(int zero, int len, char *str)
{
long long start = 0;
int root = 0;
int end = 0;
for(int i=0;i<len;i++)
{
char t = str[i];
if(i == len-1)
end = zero;
for(int j=7;j>=end;j--)
{
if((1<<j) & t)
root = HuffmanTree[root].rson;
else
root = HuffmanTree[root].lson;
if(HuffmanTree[root].lson == 0 && HuffmanTree[root].rson == 0)
{
ans[start++] = HuffmanTree[root].v;
root = 0;
}
}
}
cout<<"len::"<<start<<endl;
ofstream out(filename, ios::out);
out.write(ans, sizeof(char)*(start));
out.close();
}
int main(int argc, char **argv)
{
strcpy(filename, argv[1]);
filename[strlen(filename)-4] = 'o';
filename[strlen(filename)-3] = 'u';
filename[strlen(filename)-2] = 't';
filename[strlen(filename)-1] = '\0';
ifstream fin(argv[1], ios::in);
if(!fin)
{
cout<<"File open error!"<<endl;
return 0;
}
int num;
char *t = new char[num];
char *v = new char[3];
fin>>num;
fin.getline(t,num);
cout<<"size::"<<num<<endl;
int pos = 1;
for(int i=1;i<num;i++)
{
fin.getline(t,num);
fin.getline(v,num);
if(v[0] == '\0')
{
fin.getline(v,num);
v[0] = '\n';
}
CreatTree(t, v[0], pos);
v[0]=0;
}
int zero;
long long size;
fin>>zero; fin>>size;
fin.getline(t,num);
fin.read(str,sizeof(char)*size);
print(zero, size, str);
cout<<"zero::"<<zero<<endl;
return 0;
}程式碼讀寫操作用檔案流實現,所以在時間效率方面還有很多可優化的地方,待日後閒了再說,畢竟考試在即。。。如果哪裡有錯誤,歡迎砸磚,便於在下提升修正。