CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
摘要
問題:擁擠場景中的pose估計
文章提出自己的方法,包含兩個關鍵點:
- joint-candidate single person pose estimation (SPPE)
- global maximum joints association
該方法,對每個節點進行多峰預測,並利用圖模型和全域性關聯,對擁擠場景中不可避免的干擾具有魯棒性,推理效率高。
介紹
當前資料集MSCOCO,MPII,和AI Challenger 中擁擠場景較少,比如MSCOCO 中67.01%的場景中沒有相互重疊的目標
當前的methods隨擁擠程度上升,效能下降很快,如下圖所示


文章提出了一種新的方法來解決群體中的姿態估計問題,使用全域性的view來解決互相干擾的問題。
採用top-down方法
提出一個關節候選的(joint-cadinate)SPPE,還有一個全域性最大(權重和)關節關聯演算法 global maximum joints association algorithm
- 候選的(關節)列表包括目標關節以及對該目標關節造成干擾的關節
- 關聯演算法利用這些候選關節點,構建一個person-joint 的連結圖
- 通過一個全域性最大的關節關聯(權重和)演算法求解這個圖中的關節關聯問題
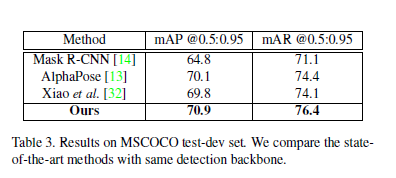
效果:在文章提出的資料集上比所有現有的方法高4.8mAP,然後在MSCOCO中提升0.8mAP
方法
SPPE 中 loss設計
目的是設計一種loss,既區別目標關節,也不把干擾關節完全抑制
對於人,它的box區域為
,經過SPPEnetwork 後得到的熱圖為
中有兩種關節,一種是目標關節(target joints),屬於
目標的,另外一種是干擾關節(interference joints),屬於其他目標的
我們的目標是增強熱圖中目標關節的響應,抑制干擾關節的響應。但是,我們並沒有直接對其進行抑制,因為當前proposal的干擾節點可以作為其他proposal的目標節點。
因而,我們應該用全域性(所有proposal結果)的方法,
Thus, we can leverage
因此為了領用這兩種候選joint,我們需要中二者輸出不同的響應強度
對於人的
關節,SPPE的 相應熱圖為
,其目標設計為一個二維的高斯分佈
將干擾關節定義為一個集合,相應的熱圖定義為
,由一個高斯混合分佈構成
那麼人的loss定義為
是一個衰減因子在區間
中
如前所述,干擾關節在指示其他人proposal的關節時是有用的。
因此,我們應該通過交叉驗證從全域性的角度來考慮它。
最後,,和上述筆者的直覺匹配,即干擾關節的響應應該被抑制,但是不能過度。
傳統的熱圖損失函式可以看作是我們的特例
Person-Joint Graph
檢測到的joint數量比實際要多,這是由於冗餘的人proposal 以及上述JC SPPE的loss設計
Person-Joint Graph 設計旨在重建最後的human pose 並且減少冗餘的joints
Joint Node Building
如下圖所示,高度重疊的proposal傾向於檢測相同的實際關節

文章首先將,表示同一個實際關節的候選關節點,組合成一個graph node。
由於高質量的關節預測,上述表徵同一實際關節的候選關節總是彼此接近的。
因此可以通過以下方式進行分組:
給定兩個候選節點,座標分別為和
,定義一個控制偏差
,如果滿足下面的條件,就把這兩個候選點組合
是對應的熱圖相應值,使用min是為了滿足,當這兩個候選節點同時出現在對方應該出現的範圍內(loss定義的範圍)
通過把所有的joint組 用一個graph node表示,我們得到joint在graph上的node集合
Person Node Building
影象中M個人proposal在graph上的node定義為
理想情況下,一個符合條件的person proposal可以緊密地包圍一個person例項。
然而,在擁擠的場景中,這種條件並不總是滿足的。person探測器會產生許多冗餘的proposal,包括截斷和鬆散的邊界框。
文章將在下面的全域性person-joint 匹配中把這些冗餘的proposal去除
Person-Joint Edge
如果 (從上面得到的joint node 其實是一個joint 的 group)中包含了
的候選joint,那
和
之間建立連結
權重等於該候選節點在熱圖中的相應值
由此得到一個edge集合
Person-Joint graph 可以寫成
Globally Optimizing Association
優化目標定義為:
s.t. ,
,
因為關節之間相互獨立,所以可以被分解為多個子圖
上述優化問題是一個二分匹配問題,貪婪match、匈牙利演算法等都可以用於求解,最好還是匈牙利演算法吧……
文章使用updated Kuhn-Munkres algorithm(G. Carpaneto and P. Toth. Algorithm for the solution of the assignment problem for sparse matrices. Computing, 1983.)
來求解上述問題,還沒看,後面看了補連結
該演算法複雜度為,後面部分比較可以通過匈牙利演算法理解,二分匹配的匹配對數一定少於等於node較少的那邊的node數量
結果對比