
機器學習--資訊 資訊熵 資訊增益
資訊:
資訊這個概念的理解更應該把他認為是一用名稱,就比如‘雞‘(加引號意思是說這個是名稱)是用來修飾雞(沒加引號是說存在的動物即雞),‘狗’是用來修飾狗的,但是假如在雞還未被命名為'雞'的時候,雞被命名為‘狗’,狗未被命名為‘狗’的時候,狗被命名為'雞',那麼現在我們看到狗就會稱其為‘雞’,見到雞的話會稱其為‘雞’,同理,資訊應該是對一個抽象事物的命名,無論用不用‘資訊’來命名這種抽象事物,或者用其他名稱來命名這種抽象事物,這種抽象事物是客觀存在的。引用夏農的話,資訊是用來消除隨機不確定性的東西。在機器學習資訊的定義是,如果待分類的事物可能劃分在多個分類之中,則這個類(Xi)的資訊定義如下:(也可以看成在數學裡資訊就是這個公式)

I(x)用來表示隨機變數的資訊,p(xi)指是當xi發生時的概率,這裡說一下隨機變數的概念,隨機變數時概率論中的概念,是從樣本空間到實數集的一個對映,樣本空間是指所有隨機事件發生的結果的並集,比如當你拋硬幣的時候,會發生兩個結果,正面或反面,而隨機事件在這裡可以是,硬幣是正面;硬幣是反面;兩個隨機事件,而{正面,反面}這個集合便是樣本空間,但是在數學中不會說用‘正面’、‘反面’這樣的詞語來作為數學運算的介質,而是用0表示反面,用1表示正面,而“正面->1”,"反面->0"這樣的對映便為隨機變數,即類似一個數學函式。
在上面這個例子中正面和反面,即(Xi)在機器學習中可以看做為分類,(Xi)的發生的概率就是(Xi)這個類別在樣本集中出現的次數除以樣本總量,而(Xi)這個類的資訊就是上面的公式。
資訊熵:
資訊熵的大小指的的是瞭解一件事情所需要付出的資訊量是多少,這件事的不確定性越大,要搞清它所需要的資訊量也就越大,也就是它的資訊熵越大。在機器學習中,熵值的計算如下公式:
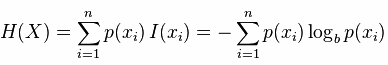
從公式上看,資訊熵就是一件事每個類別
資訊增益:
資訊增益在決策樹演算法中是用來選擇特徵的指標,資訊增益越大,則這個特徵的選擇性越好,在概率中定義為:待分類的集合的熵和選定某個特徵的條件熵之差(這裡只的是經驗熵或經驗條件熵,由於真正的熵並不知道,是根據樣本計算出來的),公式如下:
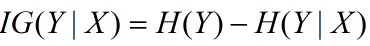
注意:這裡不要理解偏差,因為上邊說了熵是類別的,但是在這裡又說是集合的熵,沒區別,因為在計算熵的時候是根據各個類別對應的值求期望來得到熵。