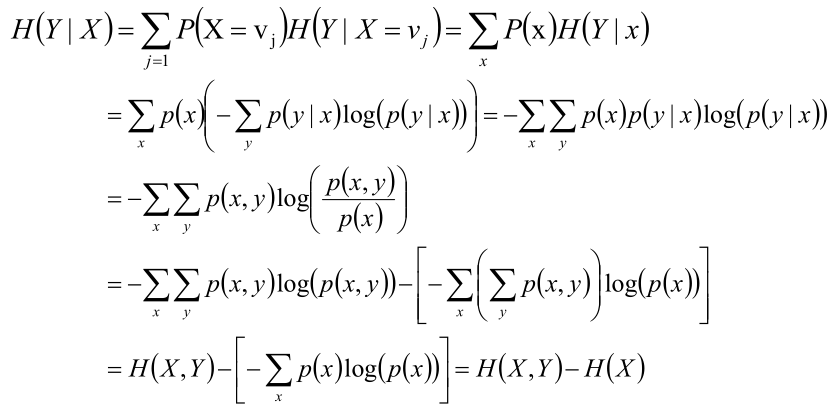機器學習 資訊熵
位元化(Bits)
假設存在一組隨機變數X,各個值出現的概率關係如圖;現在有一組由X變數組成的序列: BACADDCBAC.....;如果現在希望將這個序列轉換為二進位制來進行網路傳輸,那麼我們得到一個得到一個這樣的序列:01001000111110010010.......
結論: 在這種情況下,我們可以使用兩個位元位來表示一個隨機變數。
P(X=A)=1/4 P(X=B)=1/4 P(X=C)=1/4 P(X=D)=1/4
A B C D
00 01 10 11
而當X變量出現的概率值不一樣的時候,對於一組序列資訊來講,每個變數平均
需要多少個位元位來描述呢??
P(X=A)=1/2 P(X=B)=1/4 P(X=C)=1/8 P(X=D)=1/8
A B C D
0 10 110 111
假設現在隨機變數X具有m個值,分別為: V 1 ,V 2 ,....,V m ;並且各個值出現的概率
如下表所示;那麼對於一組序列資訊來講,每個變數平均需要多少個位元位來描
述呢??
P(X=V1)=p1 P(X=V2)=p2 P(X=V3)=p3 .................... P(X=Vm)=pm
可以使用這些變數的期望來表示每個變數需要多少個位元位來描述資訊:
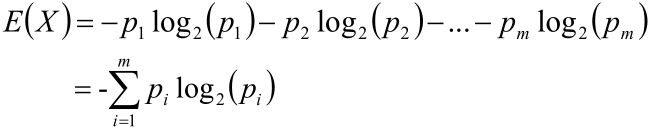
資訊熵(Entropy)
H(X)就叫做隨機變數X的資訊熵;
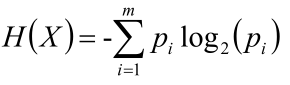
資訊熵(Entropy)
資訊量:指的是一個樣本/事件所蘊含的資訊,如果一個事件的概率越大,那麼就可以認為該事件所蘊含的資訊越少。極端情況下,比如:“太陽從東方升起”,因為是確定事件,所以不攜帶任何資訊量。
資訊熵:1948年,夏農引入資訊熵;一個系統越是有序,資訊熵就越低,一個系統越是混亂,資訊熵就越高,所以資訊熵被認為是一個系統有序程度的度量。
資訊熵就是用來描述系統資訊量的不確定度。
High Entropy(高資訊熵):表示隨機變數X是均勻分佈的,各種取值情況是等概率出現的。
Low Entropy(低資訊熵):表示隨機變數X各種取值不是等概率出現。可能出現有的事件概率很大,有的事件概率很小。
條件熵H(Y|X)
給定條件X的情況下,隨機變數Y的資訊熵就叫做條件熵。
給定條件X的情況下,所有不同x值情況下Y的資訊熵的平均值叫做條件熵。
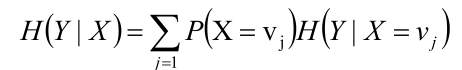
另外,一個公式如下所示:
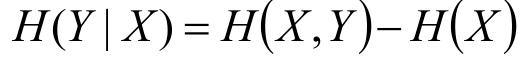
事件(X,Y)發生所包含的熵,減去事件X單獨發生的熵,即為在事件X發生的前提下,Y發生“新”帶來的熵,這個也就是條件熵本身的概念。