
重溫目標檢測--YOLO v2 -- YOLO9000
YOLO9000:Better, Faster, Stronger CVPR 2017, Best Paper Honorable Mention https://pjreddie.com/darknet/yolo/
本文是對 YOLO v1 的改進。
2 Better
YOLO v1 主要問題有兩個:1)localization error 較高;2)relatively low recall
主要的改進細節如下表所示:
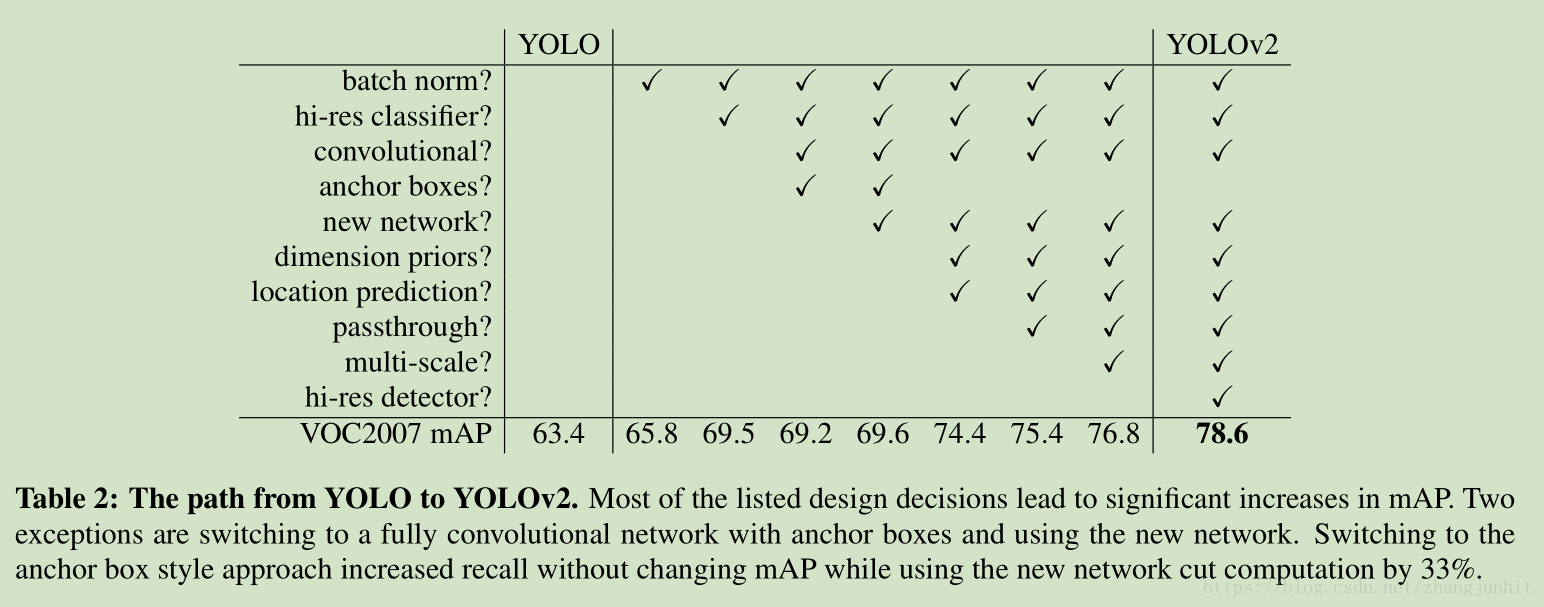
Batch Normalization: 主要作用是加速網路的收斂,這樣就不再需要其他形式的 regularization,我們在 YOLO 所有的卷積層上面使用 Batch Normalization ,有了 Batch Normalization 我們就不需要使用 dropout了。提升了 2% mAP
High Resolution Classifier: 目前主要的檢測方法都使用在 ImageNet 資料庫上預訓練的分類器。從 AlexNet 開始,大部分分類器的輸入影象尺寸都小於 256 × 256。 YOLO v1 的訓練策略是首先在 224 × 224 上面訓練,然後在 448 尺寸上做檢測訓練。這意味著網路需要適應不同尺寸的檢測。
對於 YOLO v2 我們首先在 448×448尺寸的 ImageNet 資料庫訓練 10個 epochs,然後在檢測資料庫上微調。 這個高解析度分類網路提升了 近 4% mAP
Convolutional With Anchor Boxes YOLO v1 直接在卷積特徵圖上使用全連線層進行矩形框座標的預測。 Faster R-CNN 沒有直接預測座標,使用手工先驗知識來預測矩形框,這裡的 hand-picked priors 就是若干 Anchor Boxes,這些 boxes 形狀大小的選擇依賴於待檢測物體的先驗知識,手工設計的。Faster R-CNN 中的 RPN 只使用卷積層來預測 anchor boxes 的偏差和置信度。因為預測層是卷積的,所以RPN 在特徵圖每個位置預測矩形框偏差。 預測偏差相對於座標簡化了網路學習的難度。
在 YOLO v2中,我們去掉了 YOLO v1 中的全連線層,使用 anchor boxes 來預測矩形框。首先我們去除了一個池化層,這樣增加了特徵圖尺寸大小。我們也將影象的輸入尺寸從 448×448 變為 416×416,這麼做的目的是使得最終的特徵圖尺寸為奇數,檢測位置的唯一性。
當我們使用了 anchor boxes 時,我們同時也將空位置從類別預測機制中分離出來,我們對每個 anchor boxe 預測類別和 objectness。 和 YOLO v1 一樣,objectness預測仍然是 預測 the IOU of the ground truth and the proposed box, 類別預測是假定存在一個物體時,該物體的類別概率。
使用 anchor boxes 我們的精度有所下降,但是 recall 提升較大。 YOLO v1( 69.5 mAP with a recall of 81%) 我們對每個影象只預測了98 個矩形框,在 YOLO v2(69.2 mAP with a recall of 88%) 中使用了 anchor boxes 後 我們預測的矩形框數超過 1000個。recall 的提升意味著我們的模型有更大的改進空間。
Dimension Clusters 在 YOLO v2 使用 anchor boxes 我們面臨兩個問題。第一個問題就是 box dimensions ,即使用多少個 anchor boxes 的問題?在 Faster R-CNN 中這個是手工挑選的。如果我們能夠根據先驗知識挑選更好的數量,那麼網路應該更容易學習。
這裡我們沒有手工挑選,而是在訓練的矩形框集合裡使用 k-means 聚類方法自動找到好的先驗知識 good priors
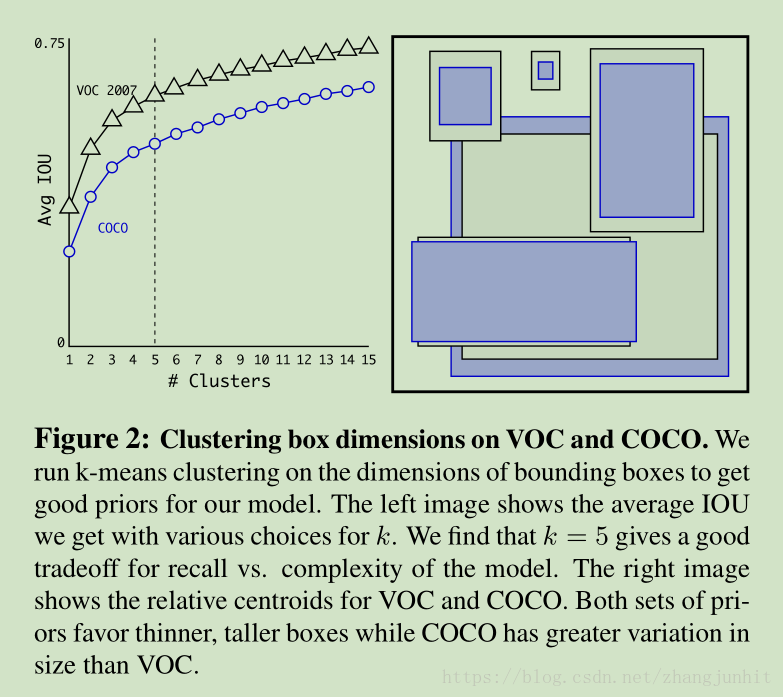
We choose k = 5 as a good tradeoff between model complexity and high recall…
Direct location prediction 使用 anchor boxes 面臨的第二個問題是模型的穩定性,尤其是在訓練迭代的早期。 造成這個原因是位置預測公式沒有約束 This formulation is unconstrained so any anchor box can end up at any point in the image, regardless of what locationpredictedthebox
Since we constrain the location prediction the parametrization is easier to learn, making the networkmore stable
Fine-Grained Features : 針對小目標檢測,這裡我們採用了另一個方式來利用 較大尺寸的特徵圖,simply adding a passthrough layer that brings features from an earlier layer at 26 × 26 resolution
Multi-Scale Training: 多尺度輸入影象的訓練可以提升網路的效能
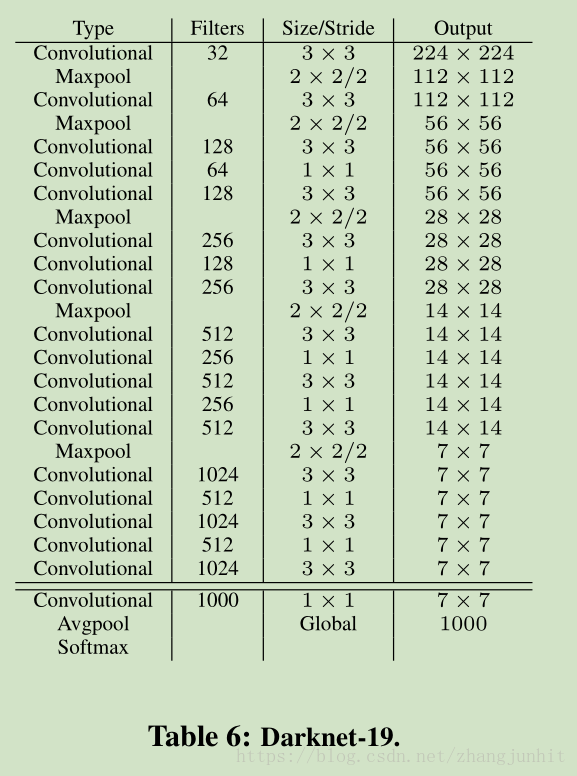
3 Faster 為了提高網路的檢測速度,我們從新設計了一個 Darknet-19
4 Stronger 這裡主要是充分利用現有的分類資料庫來提升檢測網路的檢測類別,採用 WordTree 來增加物體檢測類別